%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Primitiveanything
PrimitiveAnything は、自己回帰変換器を使用した 3D モデル生成技術であり、細部まで丁寧な 3D オリジナルアセンブリを自動的に作成します。この技術の主な利点は、複雑な 3D 形状をディープラーニングで高速に生成できる点です。これによりデザイナーの生産性が大幅に向上します。本製品はさまざまなデザイン用途に適しており、価格は無料で、3D モデリング分野向けに位置づけられています。
深層学習
37.5K

Kimi Audio
Kimi-Audioは、音声認識やオーディオ会話などの様々なオーディオ処理タスクを処理することを目的とした、高度なオープンソースのオーディオ基礎モデルです。1300万時間以上の多様なオーディオデータとテキストデータで大規模に事前学習されており、強力なオーディオ推論と言語理解能力を備えています。主な利点として、優れた性能と柔軟性があり、研究者や開発者がオーディオ関連の研究開発を行うのに適しています。
ファッションポーチ
37.3K

Describe Anything
Describe Anythingモデル(DAM)は、画像または動画の特定の領域を処理し、詳細な記述を生成できます。主な利点は、単純なマーキング(点、枠、落書き、またはマスク)によって高品質の局所的な記述を生成できることであり、コンピュータビジョン分野における画像理解能力を大幅に向上させます。このモデルは、NVIDIAと複数の大学が共同で開発したもので、研究、開発、および実用アプリケーションに適しています。
家庭用品
38.1K
海外精選

Flex.2 Preview
Flex.2は現在最も柔軟なテキストから画像への拡散モデルであり、組み込みの再描画機能と汎用的な制御機能を備えています。これはコミュニティによってサポートされているオープンソースプロジェクトであり、人工知能の民主化を促進することを目指しています。Flex.2は8億のパラメーターを備え、512トークンの長さの入力に対応し、OSIのApache 2.0ライセンスに準拠しています。このモデルは多くのクリエイティブなプロジェクトで強力なサポートを提供できます。ユーザーはフィードバックを通じてモデルを継続的に改善し、技術の進歩を促進することができます。
チャットボット
37.5K
Nes2net
Nes2Netは、基礎モデル駆動の音声反詐欺タスク向けに設計された軽量なネスト型アーキテクチャであり、低いエラー率を特長としており、オーディオディープフェイク検出に適しています。このモデルは複数のデータセットで優れたパフォーマンスを示しており、事前学習済みモデルとコードはGitHubで公開されているため、研究者や開発者が容易に使用できます。音声処理とセキュリティ分野に適しており、音声認識と反詐欺の効率性と正確性の向上を目指しています。
???????
37.8K

D1
このモデルは、強化学習と高品質な推論軌跡のマスクされた自己教師あり微調整により、拡散型大規模言語モデルの推論能力の向上を実現しました。この技術の重要性は、モデルの推論プロセスを最適化し、計算コストを削減しながら、学習ダイナミクスの安定性を維持できる点にあります。ライティングや推論タスクで効率を向上させたいユーザーに適しています。
レクチャー資料
37.8K
中国語精選

Wan2.1 FLF2V 14B
Wan2.1-FLF2V-14Bは、ビデオ生成分野の進歩を促進することを目的とした、オープンソースの大規模ビデオ生成モデルです。このモデルは、複数のベンチマークテストで優れた性能を示しており、消費者向けGPUに対応し、480Pおよび720Pのビデオを効率的に生成できます。テキストからビデオ、画像からビデオなど、複数のタスクで優れた性能を発揮し、強力なビジュアルテキスト生成能力を備えており、様々な現実的なアプリケーションシナリオに適しています。
ビデオ アップデート
37.8K

Framepack
FramePackは、入力フレームのコンテキストを圧縮することで、ビデオ生成の品質と効率を向上させる革新的なビデオ生成モデルです。主な利点として、ビデオ生成におけるドリフト問題を解決し、双方向サンプリング手法によりビデオ品質を維持することで、長尺ビデオの生成が必要なユーザーに適しています。この技術的背景は、既存モデルの徹底的な研究と実験に基づいており、ビデオ生成の安定性と一貫性を向上させます。
ビデオ アップデート
37.8K

Liquid
Liquidは、画像を離散コードに分解し、テキストトークンと特徴空間を共有することで、視覚理解とテキスト生成のシームレスな統合を促進する自己回帰生成モデルです。このモデルの主な利点は、外部で事前にトレーニングされた視覚埋め込みを必要とせず、リソースへの依存を削減し、スケール則を通じて理解と生成タスク間の相互促進効果を発見したことです。
衣服
37.8K
中国語精選

GLM 4 32B
GLM-4-32Bは、様々な自然言語処理タスクに対応することを目的とした高性能な生成言語モデルです。深層学習技術を用いて訓練されており、首尾一貫したテキストの生成や複雑な質問への回答が可能です。本モデルは、学術研究、商業用途、開発者に適しており、価格も手頃で、的確な位置付けをしており、自然言語処理分野をリードする製品です。
AIモデル
38.4K

Pusa
Pusaはフレームレベルのノイズ制御によって動画拡散モデリングに革新的な手法を取り入れ、高品質な動画生成を実現します。テキストから動画、画像から動画など、様々な動画生成タスクに適用可能です。優れたモーションの忠実度と効率的なトレーニングプロセスにより、ユーザーが容易に動画生成タスクを実行できるオープンソースのソリューションを提供します。
ビデオ アップデート
37.8K

UNO
UNOは、拡散変換器に基づいたマルチイメージ条件付き生成モデルです。漸進的なクロスモーダルアライメントと汎用回転位置埋め込みを導入することで、高一貫性の画像生成を実現します。主な利点として、単一または複数の主題の生成に対する制御性の向上が挙げられ、様々なクリエイティブな画像生成タスクに適しています。
チャットボット
38.4K
Visualcloze
VisualClozeは、視覚的コンテキスト学習による汎用的な画像生成フレームワークであり、従来のタスク固有モデルが多様なニーズにおいて低効率であるという問題を解決することを目的としています。このフレームワークは、複数の内部タスクをサポートするだけでなく、未経験のタスクにも一般化でき、視覚的な例を用いてモデルによるタスクの理解を支援します。この方法は、高度な画像修復モデルの強力な生成事前知識を活用し、画像生成を強力にサポートします。
チャットボット
38.4K
Skyreels A2
SkyReels-A2は、動画拡散トランスフォーマーに基づくフレームワークであり、ユーザーは動画コンテンツの合成と生成を行うことができます。このモデルは深層学習技術を活用することで、柔軟な創作能力を提供し、アニメーションや特殊効果制作など、様々な動画生成アプリケーションに適しています。本製品の利点は、オープンソースであることと、効率的なモデル性能であり、研究者や開発者による使用に適しており、現在無料で提供されています。
ビデオ アップデート
37.0K

Megatts 3
MegaTTS 3は、バイトダンスが開発したPyTorchベースの高効率音声合成モデルであり、超高品質の音声クローン機能を備えています。軽量のアーキテクチャはわずか0.45Bのパラメータで構成され、中国語、英語、コードの切り替えに対応し、入力テキストに基づいて自然で滑らかな音声を作成できます。学術研究や技術開発で幅広く利用されています。
["ファッション, AI モデル]
38.1K

Easycontrol
EasyControlは、Diffusion Transformer(拡散変換器)に効率的で柔軟な制御を提供するフレームワークであり、現在のDiTエコシステムにおける効率のボトルネックやモデルの適合性の不足といった問題に対処することを目的としています。主な利点としては、様々な条件の組み合わせに対応、生成の柔軟性と推論効率の向上があります。本製品は最新の研究成果に基づいて開発されており、画像生成、スタイル変換などの分野で使用できます。
AIモデル
38.1K

Dreamactor M1
DreamActor-M1は、拡散トランスフォーマー(DiT)に基づいたヒューマンアニメーションフレームワークであり、きめ細やかな全体制御性、マルチスケール適応性、長期的な時間的一貫性を達成することを目指しています。本モデルは混合誘導によって、肖像画から全身アニメーションまで、様々なシーンに適用可能な、高表現力かつリアルなヒューマンビデオを生成できます。主な利点は高忠実度とアイデンティティ保持であり、ヒューマンビヘイビアアニメーションに新たな可能性をもたらします。
ビデオ アップデート
37.8K
中国語精選

QVQ Max
QVQ-Maxは、Qwenチームが開発したビジュアル推論モデルで、画像やビデオの内容を理解して分析し、解決策を提供します。テキスト入力だけでなく、複雑な視覚情報も処理できます。教育、仕事、生活など、マルチモーダルな情報処理が必要なユーザーに適しています。この製品は、深層学習とコンピュータビジョン技術に基づいて開発され、学生、ビジネスパーソン、クリエイターの方々に最適です。このバージョンは最初のリリースであり、今後継続的に改善していきます。
AIモデル
42.2K
Video T1
Video-T1は、テスト時間スケーリング(TTS)技術により、生成動画の品質と整合性を大幅に向上させる動画生成モデルです。この技術により、推論中により多くの計算資源を使用できるため、生成結果を最適化できます。従来の動画生成方法と比較して、TTSはより高い生成品質とより豊かなコンテンツ表現を提供し、デジタル創作分野に適しています。本製品は主に研究者と開発者を対象としており、価格情報は明確にされていません。
["ビデオ アップデート, AI モデル]
42.8K
RF DETR
RF-DETRは、エッジデバイスに高精度とリアルタイム性能を提供することを目的とした、Transformerベースのリアルタイム物体検出モデルです。Microsoft COCOベンチマークで60 APを超える競争力のある性能と高速な推論速度を備え、様々な実用的なアプリケーションシナリオに適しています。RF-DETRは、現実世界の物体検出問題を解決することを目的としており、防犯、自動運転、スマート監視など、高効率かつ正確な検出が必要な業界に適しています。
["ラクシー パチャーン],["AI モデル]
51.1K
中国語精選
混元T1
混元T1はテンセントが発表した超大規模推論モデルであり、強化学習技術に基づいており、大量の後訓練によって推論能力を大幅に向上させています。長文処理とコンテキストの把握において優れた性能を発揮し、計算資源の消費も最適化されており、効率的な推論能力を備えています。あらゆる種類の推論タスクに適用でき、特に数学、論理推論などの分野で優れた性能を発揮します。本製品は深層学習をベースとしており、実際のフィードバックを参考に継続的に最適化されており、研究、教育など複数の分野での応用に向いています。
AIモデル
42.0K
中国語精選
混元T1
混元T1は、テンセントが開発した強化学習に基づく深層推論大規模モデルです。大規模な事後学習と人間の好みの調整により、推論能力と効率が大幅に向上しています。大規模なHybrid-Transformer-Mamba MoEアーキテクチャに基づいており、長文の処理において優れたパフォーマンスを発揮します。複雑な推論と論理的な解決策を必要とするあらゆるユーザーに適しており、科学研究や技術開発を支援します。
AIモデル
47.2K
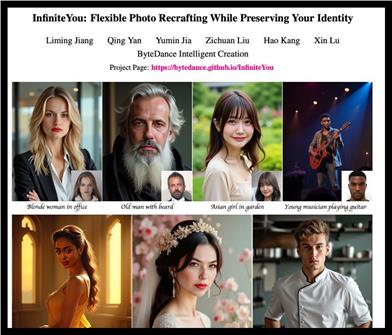
Infiniteyou
InfiniteYou(InfU)は、拡散変換器に基づいた強力なフレームワークであり、柔軟な画像再構成を実現し、ユーザーのアイデンティティを維持することを目的としています。アイデンティティの特徴を導入し、多段階トレーニング戦略を採用することで、画像生成の品質と美学を大幅に向上させ、テキストと画像のアライメントも改善します。この技術は、画像生成の類似性と美観の向上に重要な意味を持ち、様々な画像生成タスクに適用できます。
チャットボット
52.2K

Pruna
Prunaは開発者向けに設計されたモデル最適化フレームワークであり、量子化、剪定、コンパイルなどのさまざまな圧縮アルゴリズムを通じて、機械学習モデルの推論を高速化し、サイズを縮小し、計算コストを削減します。LLM、ビジョン変換器など、さまざまなモデルタイプに適用でき、Linux、MacOS、Windowsなど複数のプラットフォームをサポートしています。Prunaは、より高度な最適化機能と優先サポートを提供するエンタープライズ版Pruna Proも提供しており、ユーザーが実際のアプリケーションで効率を向上させることができます。
["ヴィーカス?オール?ウパカーラン],["モジュール?プラシクシャン?オール?パリニヨジャン]
47.2K
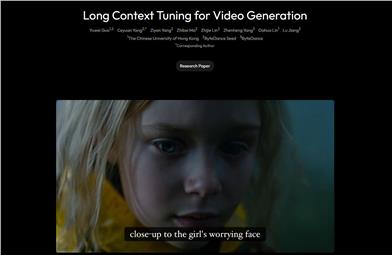
ロングコンテキスト最適化(LCT)
ロングコンテキスト最適化(LCT)は、現在の単一生成能力と現実のナラティブビデオ制作とのギャップを解消することを目的としています。この技術は、データ駆動型のアプローチを使用してシーンレベルの一貫性を直接学習し、インタラクティブなマルチカメラ開発と合成生成をサポートしており、ビデオ制作のあらゆる側面に適用できます。
ビデオ アップデート
46.6K

Thera
Theraは、さまざまな尺度で高品質な画像を生成できる高度な超解像度技術です。主な利点として、物理的な観測モデルが組み込まれており、エイリアシング現象を効果的に回避できる点が挙げられます。この技術はETH Zurichの研究チームによって開発され、画像強調とコンピュータビジョン分野、特にリモートセンシングと測量で幅広く応用されています。
チャットボット
47.7K
IMM
Inductive Moment Matching (IMM)は、高品質な画像生成を目的とした、最先端の生成モデル技術です。この技術は革新的な帰納的モーメントマッチング手法を用いることで、生成画像の品質と多様性を大幅に向上させます。主な利点としては、効率性、柔軟性、そして複雑なデータ分布に対する強力なモデリング能力が挙げられます。IMMはLuma AIとスタンフォード大学の研究チームによって開発され、生成モデル分野の発展を促進し、画像生成、データ拡張、創造的なデザインなどのアプリケーションに強力な技術サポートを提供することを目的としています。このプロジェクトはコードと事前学習済みモデルをオープンソース化しており、研究者や開発者が迅速に使い始めることができます。
チャットボット
50.5K
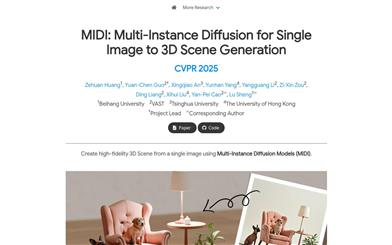
MIDI
MIDIは、多インスタンス拡散モデルを利用した革新的な画像から3Dシーン生成技術です。正確な空間関係を持つ複数の3Dインスタンスを、単一画像から直接生成できます。この技術の中核は多インスタンスアテンションメカニズムであり、複雑な複数ステップ処理を必要とせずに、物体間の相互作用と空間的一貫性を効果的に捉えることができます。MIDIは画像からシーン生成分野で優れた性能を示し、合成データ、現実世界のシーンデータ、そしてテキストから画像への拡散モデルによって生成されたスタイル化されたシーン画像に適しています。主な利点として、効率性、高忠実度、そして強力な汎化能力が挙げられます。
3Dモデリング
49.4K
R1 Omni
R1-Omniは、強化学習によってモデルの推論能力と汎化能力を向上させた、革新的なマルチモーダル感情認識モデルです。HumanOmni-0.5Bを基に開発され、感情認識タスクに特化しており、視覚および音声モーダル情報から感情分析を行うことができます。主な利点としては、強力な推論能力、感情認識性能の顕著な向上、および分布外データにおける優れたパフォーマンスが挙げられます。感情分析、スマートカスタマーサービスなどの分野でマルチモーダルな理解が必要なシナリオに適用でき、重要な研究および応用価値を有しています。
家庭用サービス
53.5K
Videopainter
VideoPainterは、深層学習に基づいたビデオ修復と編集ツールです。プリトレーニング済みの拡散変換器モデルと、軽量の背景コンテキストエンコーダー、IDリサンプリング技術を組み合わせることで、高品質なビデオ修復と編集を実現します。この技術の重要性は、従来のビデオ修復方法の長さと複雑さに関する制限を突破し、ビデオ制作者に効率的で柔軟なツールを提供することにあります。本製品は現在研究段階にあり、価格は未定です。主にビデオ編集分野の専門ユーザーや研究者を対象としています。
["ウェディングサプライヤー],["AIデジタルサイネージアプリケーション]
45.3K
- 1
- 2
- 3
- 4
- 5
- 6
- 10
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.5K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M