%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Dreamactor M1
紹介 :
DreamActor-M1は、拡散トランスフォーマー(DiT)に基づいたヒューマンアニメーションフレームワークであり、きめ細やかな全体制御性、マルチスケール適応性、長期的な時間的一貫性を達成することを目指しています。本モデルは混合誘導によって、肖像画から全身アニメーションまで、様々なシーンに適用可能な、高表現力かつリアルなヒューマンビデオを生成できます。主な利点は高忠実度とアイデンティティ保持であり、ヒューマンビヘイビアアニメーションに新たな可能性をもたらします。
ターゲットユーザー :
「本製品は、アニメーション制作従事者、ゲーム開発者、高品質なヒューマンアニメーションを必要とするクリエイター向けです。強力な制御機能と多様な適用シーンにより、プロフェッショナルの高いアニメーション表現力と一貫性への要求を満たすことができます。」
使用シナリオ
アニメ映画制作において、DreamActor-M1を利用して高品質なヒューマンキャラクターアニメーションを生成します。
ゲーム開発において、このモデルを使用してゲームキャラクターに滑らかな動作表現を作成します。
ソーシャルメディアコンテンツ制作において、DreamActor-M1を使用して目を引く短編ビデオを生成します。
製品特徴
精細な制御:暗黙的な顔の表現、3Dヘッドボール、3Dボディスケルトンを組み合わせることで、顔の表情と体の動きを堅牢に制御します。
マルチスケール適応:段階的なトレーニング戦略を採用し、様々な体の姿勢と異なる解像度の画像を処理し、肖像画と全身ビューの変換をサポートします。
長期的な時間的一貫性:連続フレームの動きパターンと視覚的な参照を統合することで、複雑な動きにおける未観測領域の時間的一貫性を確保します。
顔アニメーションのサポート:音声駆動の顔アニメーションに拡張でき、多言語の口パク同期を実現します。
形状認識アニメーション:骨格の長さ調整技術により、形状に適応したアニメーション生成を実現します。
柔軟なモーション転送:顔の表情や頭の動きなど、一部の動きのみを転送できます。
多様なスタイルのサポート:様々なキャラクターや動きスタイルに堅牢です。
多様な視点のサポート:異なる頭の姿勢でアニメーション結果を生成できます。
使用チュートリアル
参照画像と駆動ビデオフレームを用意します。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
参照画像とビデオフレームをモデルに入力してトレーニングします。
混合誘導パラメータを設定して、顔と体の動きを調整します。
モデルを実行して、目標アニメーションビデオを生成します。
必要に応じて、生成されたビデオを後処理および調整します。








おすすめAI製品
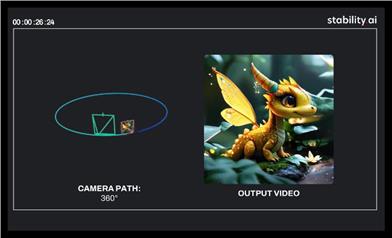
Stable Virtual Camera
Stable Virtual Cameraは、Stability AIが開発した13億パラメーターの汎用拡散モデルであり、Transformer画像からビデオへの変換モデルです。その重要性は、新しいビュー合成(NVS)に技術的なサポートを提供することであり、入力ビューとターゲットカメラに基づいて、3D整合性のある新しいシーンビューを生成できます。主な利点としては、ターゲットカメラの軌跡を自由に指定でき、大きな視点の変化と時間的に滑らかなサンプルを生成でき、追加のニューラル放射場(NeRF)蒸留なしで高い整合性を維持でき、さらに最長30秒の高品質でシームレスなループビデオを生成できることが挙げられます。このモデルは、研究および非商業目的でのみ無料で使用でき、研究者や非商業クリエイターに革新的な画像からビデオへの変換ソリューションを提供することを目的としています。
ビデオ アップデート
51.6K
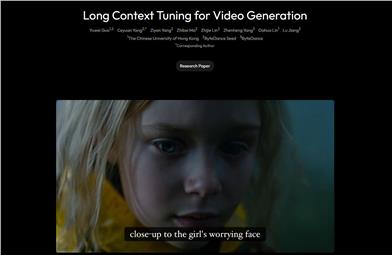
ロングコンテキスト最適化(LCT)
ロングコンテキスト最適化(LCT)は、現在の単一生成能力と現実のナラティブビデオ制作とのギャップを解消することを目的としています。この技術は、データ駆動型のアプローチを使用してシーンレベルの一貫性を直接学習し、インタラクティブなマルチカメラ開発と合成生成をサポートしており、ビデオ制作のあらゆる側面に適用できます。
ビデオ アップデート
46.6K