%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Pusa
紹介 :
Pusaはフレームレベルのノイズ制御によって動画拡散モデリングに革新的な手法を取り入れ、高品質な動画生成を実現します。テキストから動画、画像から動画など、様々な動画生成タスクに適用可能です。優れたモーションの忠実度と効率的なトレーニングプロセスにより、ユーザーが容易に動画生成タスクを実行できるオープンソースのソリューションを提供します。
ターゲットユーザー :
「Pusaは、高度な動画生成技術を利用して高品質なビジュアルコンテンツを作成したい、動画制作者、デジタルアーティスト、研究者にとって最適です。オープンソースであるため、ユーザーは自身のニーズに合わせてカスタマイズおよび拡張できます。」
使用シナリオ
テキストプロンプトによる動画生成、例:「人がバスケットボールをしている」と入力すると、関連する動画が生成されます。
ユーザーが提供した画像を動的な動画に変換し、ソーシャルメディアコンテンツの作成に使用します。
商業広告用の短編動画を作成し、シームレスループと動画トランジション効果を使用して効果を高めます。
製品特徴
テキストから動画の生成に対応:ユーザーはテキストプロンプトを入力して、対応する動画コンテンツを生成できます。
画像から動画への変換:ユーザーは静止画を動的な動画に変換し、視覚的な表現力を高めることができます。
フレーム補間機能:補間技術により動画フレームを滑らかにし、視聴体験を向上させます。
シームレスループ生成:ループ再生可能な動画を作成でき、短編動画コンテンツに最適です。
動画トランジション効果:動画間のトランジション効果に対応し、動画制作の専門性を高めます。
拡張動画生成:より長い動画の生成に対応し、様々なユーザーニーズに対応します。
高効率:トレーニングにはわずか0.1k H800 GPU時間しかかからず、コストが低いです。
完全なオープンソースリリース:完全なコードリポジトリと詳細なドキュメントを提供し、ユーザーによる二次開発を容易にします。
使用チュートリアル
Pusaモデルをインストールするには、Gitでコードリポジトリをクローンし、依存関係をインストールします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
モデルの重みをダウンロードします。Hugging Faceなどのソースから必要なファイルを取得します。
テキストから動画を生成するコマンドを実行し、モデルパスとプロンプト情報を提供します。
最適な効果を得るために、さまざまな条件位置を試します。
複数の画像を処理する場合は、各画像に対応するテキストプロンプトファイルを用意してください。








おすすめAI製品
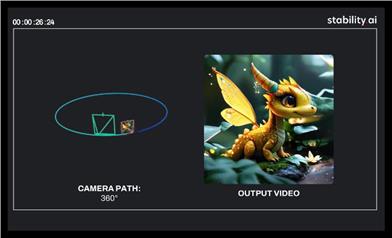
Stable Virtual Camera
Stable Virtual Cameraは、Stability AIが開発した13億パラメーターの汎用拡散モデルであり、Transformer画像からビデオへの変換モデルです。その重要性は、新しいビュー合成(NVS)に技術的なサポートを提供することであり、入力ビューとターゲットカメラに基づいて、3D整合性のある新しいシーンビューを生成できます。主な利点としては、ターゲットカメラの軌跡を自由に指定でき、大きな視点の変化と時間的に滑らかなサンプルを生成でき、追加のニューラル放射場(NeRF)蒸留なしで高い整合性を維持でき、さらに最長30秒の高品質でシームレスなループビデオを生成できることが挙げられます。このモデルは、研究および非商業目的でのみ無料で使用でき、研究者や非商業クリエイターに革新的な画像からビデオへの変換ソリューションを提供することを目的としています。
ビデオ アップデート
51.6K
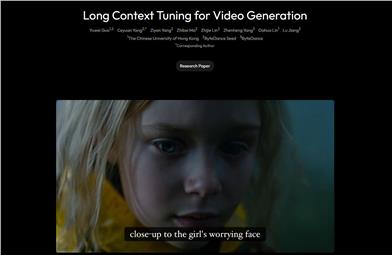
ロングコンテキスト最適化(LCT)
ロングコンテキスト最適化(LCT)は、現在の単一生成能力と現実のナラティブビデオ制作とのギャップを解消することを目的としています。この技術は、データ駆動型のアプローチを使用してシーンレベルの一貫性を直接学習し、インタラクティブなマルチカメラ開発と合成生成をサポートしており、ビデオ制作のあらゆる側面に適用できます。
ビデオ アップデート
46.6K