%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

D1
紹介 :
このモデルは、強化学習と高品質な推論軌跡のマスクされた自己教師あり微調整により、拡散型大規模言語モデルの推論能力の向上を実現しました。この技術の重要性は、モデルの推論プロセスを最適化し、計算コストを削減しながら、学習ダイナミクスの安定性を維持できる点にあります。ライティングや推論タスクで効率を向上させたいユーザーに適しています。
ターゲットユーザー :
「研究者や開発者で、強化学習を利用して大規模言語モデルの推論能力を最適化し、アプリケーションの効率を向上させたいと考えている方に向いています。」
使用シナリオ
このモデルを使用して、複雑な問題に対するチャットボットの推論能力を向上させます。
教育アプリケーションにおいて、生徒が論理的推論の問題を解決するのを支援します。
コンテンツクリエイターにインテリジェントなライティングアシスタンスを提供し、創作効率を向上させます。
製品特徴
高品質な推論軌跡:厳選された1000個の推論問題を使用して微調整を行いました。
効果的な方策勾配法アルゴリズム:マスクされた拡散型大規模言語モデルに適応するために、diffu-GRPO を導入しました。
対数確率推定:平均場近似法を採用し、効率的な対数確率推定を提供します。
ランダムマスク:摂動ビューを作成し、方策最適化の正則化効果を高めます。
安定した学習ダイナミクス:内部更新の回数を増やし、外部バッチ反復の必要性を低減します。
使用チュートリアル
モデルソフトウェアをダウンロードしてインストールします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
高品質の推論問題データセットを用意します。
マスクされた自己教師あり微調整を実行します。
diffu-GRPO を適用してポリシーを最適化します。
実際のアプリケーションにおけるモデルのパフォーマンスを評価し、調整します。



おすすめAI製品
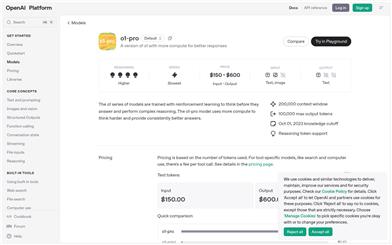
O1 Pro
o1-proモデルは、高品質なテキスト生成と複雑な推論を提供するために設計された、高度な人工知能言語モデルです。推論と応答の正確性に優れており、高精度なテキスト処理が必要なアプリケーションシーンに適しています。本モデルの価格は使用トークン数に基づいており、入力100万トークンあたり150米ドル、出力100万トークンあたり600米ドルです。企業や開発者は、本モデルをアプリケーションに統合することで、効率的なテキスト生成能力を活用できます。
レクチャー資料
45.8K
Anystory
AnyStory は、AI 技術を使用してユーザーにライティング支援を提供し、迅速に最初の草稿を作成し、インテリジェントな提案を提供することで、ユーザーのライティング効率と品質を向上させます。主な利点は、ユーザーのライティングスタイルを理解し、ユーザーのニーズに合ったコンテンツを生成できることであり、さまざまなライティングプロジェクトの種類をサポートし、さまざまなユーザーのニーズを満たします。製品はライティングアシスタントとして位置付けられており、あらゆるライティングシーンに適用でき、価格は使用状況に応じて課金され、シンプルで透明性があります。
レクチャー資料
43.1K