%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Framepack
紹介 :
FramePackは、入力フレームのコンテキストを圧縮することで、ビデオ生成の品質と効率を向上させる革新的なビデオ生成モデルです。主な利点として、ビデオ生成におけるドリフト問題を解決し、双方向サンプリング手法によりビデオ品質を維持することで、長尺ビデオの生成が必要なユーザーに適しています。この技術的背景は、既存モデルの徹底的な研究と実験に基づいており、ビデオ生成の安定性と一貫性を向上させます。
ターゲットユーザー :
「この製品は、高品質なビデオを生成する必要があるビデオコンテンツ制作者、研究者、開発者、特に長尺ビデオ生成に優位性を持つ方々に適しています。FramePack は、ビデオの生成を迅速化し、特に長尺ビデオ生成においてビデオ品質を維持するのに役立ちます。」
使用シナリオ
ユーザーはFramePackを使用して30フレームのビデオを生成し、ショートビデオを作成できます。
個人実験では、研究者はフレームのコンテキストを調整して、さまざまなビデオ生成効果をテストできます。
開発者はFramePackをアプリケーションに統合して、ビデオ生成機能を提供できます。
製品特徴
次フレーム予測:ビデオの次のフレームの画像を正確に生成できます。
コンテキスト圧縮:フレームの重要性とリソース割り当てを調整することで、効率的なコンテキストエンコーディングを実現します。
双方向サンプリング:因果関係を打破し、双方向サンプリングを使用してドリフト現象を軽減します。
柔軟なスケジューリング:さまざまなスケジューリング戦略をサポートし、さまざまな生成ニーズに対応します。
効率的な計算:一定時間でストリーミング処理を行い、計算リソースの使用を最適化します。
高速なビデオ生成:個人のGPUで高速なビデオ生成を実現し、個人の実験に適しています。
高い互換性:さまざまな入力形式とユーザー定義の入力フレームをサポートします。
使用チュートリアル
FramePack モデルをダウンロードしてインストールします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
必要な入力フレームをインポートします。
適切なフレームスケジューリング戦略を選択します。
生成プロセスを開始し、出力を監視します。
生成されたビデオをローカルデバイスに保存します。








おすすめAI製品
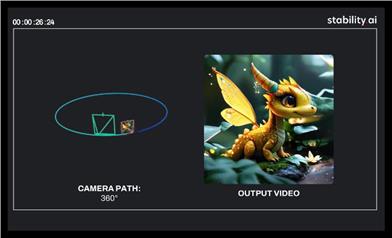
Stable Virtual Camera
Stable Virtual Cameraは、Stability AIが開発した13億パラメーターの汎用拡散モデルであり、Transformer画像からビデオへの変換モデルです。その重要性は、新しいビュー合成(NVS)に技術的なサポートを提供することであり、入力ビューとターゲットカメラに基づいて、3D整合性のある新しいシーンビューを生成できます。主な利点としては、ターゲットカメラの軌跡を自由に指定でき、大きな視点の変化と時間的に滑らかなサンプルを生成でき、追加のニューラル放射場(NeRF)蒸留なしで高い整合性を維持でき、さらに最長30秒の高品質でシームレスなループビデオを生成できることが挙げられます。このモデルは、研究および非商業目的でのみ無料で使用でき、研究者や非商業クリエイターに革新的な画像からビデオへの変換ソリューションを提供することを目的としています。
ビデオ アップデート
53.0K
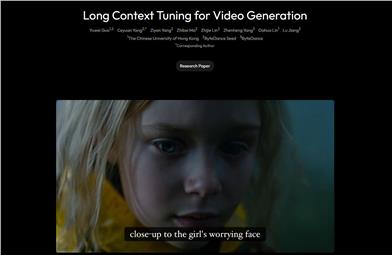
ロングコンテキスト最適化(LCT)
ロングコンテキスト最適化(LCT)は、現在の単一生成能力と現実のナラティブビデオ制作とのギャップを解消することを目的としています。この技術は、データ駆動型のアプローチを使用してシーンレベルの一貫性を直接学習し、インタラクティブなマルチカメラ開発と合成生成をサポートしており、ビデオ制作のあらゆる側面に適用できます。
ビデオ アップデート
48.9K