%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
AI ASMR
AI ASMRジェネレーターは、AI技術を使用してASMR動画を生成するツールです。ユーザーが迅速に高品質なASMR動画を作成できるようにし、より豊かな体験と刺激を提供します。
\"\"
37.0K
Vidduo
最先端のAI技術を使用した画像から動画への変換ツールは、自動的に最適なモデルを選択し、1080pの高精細な動画を生成します。複数のショットを取りながら、多様なスタイルとスムーズな動きをサポートします。主な特長は、高速で高品質な動画生成、複雑なシーンのサポート、カメラモーションの制御などであり、特にデザイナーやコンテンツクリエイターに適しています。
\"\"
37.8K

Veo3video
Veo3 Videoは、Google Veo3モデルを使用して高品質なビデオを生成するプラットフォームです。高度な技術とアルゴリズムを使用し、ビデオ生成中にリップシンクを保証し、一貫した画質を提供します。
\"\"
37.8K
Veo3
Veo 3は最新のAIビデオ生成ツールで、効果音、台詞、環境音を取り入れて、あなたの物語を生き生きとさせます。
AI
37.8K
海外精選

Veo 3
Veo 3は最新のビデオ生成モデルであり、4K出力によるリアルな映像と改良されたオーディオ効果により、ユーザーのプロンプトに的確に対応します。この技術はビデオ生成分野における重要な進化を遂げており、より強力な創造的コントロール機能を提供します。Veo 3のリリースはVeo 2への重要なアップデートであり、クリエイターが自身の創造的なビジョンを実現することを支援します。この製品は広告からゲーム開発まで、高品質なビデオ生成が必要なクリエイティブ業界全般に適しています。具体的な料金情報は公表されていません。
ディープラーニング
38.1K
中国語精選
Hunyuancustom
HunyuanCustom は、ユーザー定義の条件に基づいて特定のテーマのビデオを生成するためのマルチモーダルカスタムビデオ生成フレームワークです。この技術は、画像ID強化モジュールや時間 CASCADE の導入を通じて、テキスト、画像、音声、ビデオなどの多様な入力に対応しており、バーチャルキャラクターアドバタイジングやビデオ編集など、さまざまなシーンでの用途に適しています。
マルチモーダル
37.8K

Pixverse MCP
PixVerse-MCPは、モデルコンテキストプロトコル(MCP)をサポートするアプリケーションを介して、PixVerseの最新のビデオ生成モデルにアクセスできるツールです。テキストからビデオへの変換などの機能を提供し、クリエイターと開発者がどこでも高品質のビデオを生成できます。PixVerseプラットフォームではAPIクレジットが必要であり、ユーザーが別途購入する必要があります。
ビデオ アップデート
37.8K
海外精選
Avatarfx
AvatarFX は、インタラクティブなストーリーテリングに特化した最先端のAIプラットフォームです。ユーザーは画像をアップロードし、音声を選択することで、生き生きとしたリアルなキャラクタービデオを迅速に生成できます。そのコアテクノロジーは、DiTベースの拡散ビデオ生成モデルであり、高忠実度で時間的に一貫性のあるビデオを効率的に生成でき、特に複数のキャラクターと会話シーンが必要なクリエイションに最適です。クリエイターにツールを提供し、想像力の無限の可能性を実現することを目指しています。
["ビデオ ジェネレーター],["オーディオ カレクター ジェネレーター]
39.2K
高品質新製品

Vidu Q1
Vidu Q1は、生数科技が開発した国産ビデオ生成大規模言語モデルで、ビデオクリエーター向けに設計されており、1080pの高解像度ビデオ生成に対応し、映画レベルのカメラワークと先頭と末尾のフレーム機能を備えています。この製品は、VBench-1.0とVBench-2.0の評価でトップにランクインしており、コストパフォーマンスに優れ、価格は競合製品の10分の1です。映画、広告、アニメーションなど、さまざまな分野に適用でき、制作コストの大幅な削減と制作効率の向上を実現します。
["ビデオ アップデート, AI モデル]
37.8K
中国語精選

Wan2.1 FLF2V 14B
Wan2.1-FLF2V-14Bは、ビデオ生成分野の進歩を促進することを目的とした、オープンソースの大規模ビデオ生成モデルです。このモデルは、複数のベンチマークテストで優れた性能を示しており、消費者向けGPUに対応し、480Pおよび720Pのビデオを効率的に生成できます。テキストからビデオ、画像からビデオなど、複数のタスクで優れた性能を発揮し、強力なビジュアルテキスト生成能力を備えており、様々な現実的なアプリケーションシナリオに適しています。
ビデオ アップデート
37.8K

Framepack
FramePackは、入力フレームのコンテキストを圧縮することで、ビデオ生成の品質と効率を向上させる革新的なビデオ生成モデルです。主な利点として、ビデオ生成におけるドリフト問題を解決し、双方向サンプリング手法によりビデオ品質を維持することで、長尺ビデオの生成が必要なユーザーに適しています。この技術的背景は、既存モデルの徹底的な研究と実験に基づいており、ビデオ生成の安定性と一貫性を向上させます。
ビデオ アップデート
37.8K

Dreamactor M1
DreamActor-M1は、拡散トランスフォーマー(DiT)に基づいたヒューマンアニメーションフレームワークであり、きめ細やかな全体制御性、マルチスケール適応性、長期的な時間的一貫性を達成することを目指しています。本モデルは混合誘導によって、肖像画から全身アニメーションまで、様々なシーンに適用可能な、高表現力かつリアルなヒューマンビデオを生成できます。主な利点は高忠実度とアイデンティティ保持であり、ヒューマンビヘイビアアニメーションに新たな可能性をもたらします。
ビデオ アップデート
37.8K

GAIA 2
GAIA-2は、ウェイブが開発した高度なビデオ生成モデルであり、自動運転システムに多様で複雑な運転シナリオを提供し、安全性と信頼性を向上させることを目的としています。このモデルは、現実世界のデータ収集への依存という制約に対処するために合成データの生成を行い、一般的なケースとエッジケースを含む様々な運転状況を作成できます。GAIA-2は、様々な地理的および環境条件のシミュレーションをサポートしており、開発者は高額なコストをかけることなく、自動運転アルゴリズムを迅速にテストおよび検証できます。
ビデオ アップデート
39.7K
ロングコンテキスト最適化(LCT)
ロングコンテキスト最適化(LCT)は、現在の単一生成能力と現実のナラティブビデオ制作とのギャップを解消することを目的としています。この技術は、データ駆動型のアプローチを使用してシーンレベルの一貫性を直接学習し、インタラクティブなマルチカメラ開発と合成生成をサポートしており、ビデオ制作のあらゆる側面に適用できます。
ビデオ アップデート
46.6K
MM StoryAgent
MM_StoryAgentは、マルチエージェントパラダイムに基づいたストーリービデオ生成フレームワークであり、テキスト、画像、音声などの複数のモダリティを組み合わせて、多段階のプロセスを通じて高品質のストーリービデオを生成します。このフレームワークの主要な利点はカスタマイズ可能性であり、ユーザーは各コンポーネントの生成品質を向上させるために専門家ツールをカスタマイズできます。さらに、ストーリーのテーマリストと評価基準を提供することで、さらなるストーリーの作成と評価を容易にします。MM_StoryAgentは、効率的にストーリービデオを生成する必要があるクリエイターや企業を対象としており、オープンソースであるため、ユーザーは自身のニーズに合わせて拡張および最適化できます。
["ビデオ アップデート, AI モデル]
44.7K
Wan.video
Wan_AI Creative Drawingは、人工知能技術に基づいたクリエイティブな絵画とビデオ制作プラットフォームです。高度なAIモデルを通じて、ユーザーが入力したテキストの説明に基づいて、ユニークなアート作品とビデオコンテンツを生成します。この技術は、アート制作のハードルを下げるだけでなく、クリエイターに強力なツールを提供します。製品は主にクリエイティブな専門家、アーティスト、一般ユーザーを対象としており、創造的なアイデアを迅速に実現する支援をします。現在、このプラットフォームは無料トライアルまたは有料利用を提供している可能性があり、具体的な価格と位置付けについては、さらに確認する必要があります。
AIデジタルアーツ
44.7K
Hunyuan Video Keyframe Control Lora
HunyuanVideo Keyframe Control Loraは、HunyuanVideo T2Vモデルを対象としたアダプターであり、キーフレームビデオ生成に特化しています。入力埋め込み層を変更してキーフレーム情報を効果的に統合し、低ランク適応(LoRA)技術を適用して線形層と畳み込み入力層を最適化することで、効率的な微調整を実現します。このモデルにより、ユーザーはキーフレームを定義することで生成ビデオの開始フレームと終了フレームを正確に制御し、生成コンテンツが指定されたキーフレームとシームレスに接続され、ビデオの一貫性と物語性を高めることができます。ビデオ生成分野で重要な応用価値があり、特にビデオコンテンツの正確な制御が必要な場面で優れた性能を発揮します。
映像制作
52.4K
Cinemaster
CineMasterは、高品質な映画レベルのビデオ生成に特化したフレームワークです。3D空間認識機能と制御性により、ユーザーはプロの映画監督のように、シーン内のオブジェクト配置、カメラの動き、レンダリングフレームのレイアウトを正確に制御できます。このフレームワークは、2段階の操作で実現します。第1段階では、インタラクティブなワークフローを通じて、ユーザーが3D空間で条件信号を直感的に構築します。第2段階では、これらの信号をテキストからビデオへの拡散モデルのガイドとして使用し、ユーザーが期待するビデオコンテンツを生成します。CineMasterの主な利点は、その高い制御性と3D空間認識機能であり、高品質なダイナミックなビデオコンテンツを生成でき、映画制作、広告制作などの分野に適しています。
映像制作
51.1K
Magic 1 For 1
Magic 1-For-1は、効率的なビデオ生成に特化したモデルであり、テキストと画像をビデオに高速に変換する機能がコアです。テキストからビデオへの生成タスクを、テキストから画像、画像からビデオの2つのサブタスクに分解することで、メモリ使用量を最適化し、推論の遅延を削減しています。主な利点としては、効率性、低遅延、拡張性があります。このモデルは北京大学DA-Groupチームによって開発され、インタラクティブな基礎ビデオ生成分野の発展を目指しています。現在、このモデルと関連コードはオープンソース化されており、ユーザーは無料で使用できますが、オープンソースライセンス契約を遵守する必要があります。
映像制作
54.1K
Lumina Video
Lumina-Videoは、Alpha-VLLMチームが開発した、テキストから高品質なビデオコンテンツを生成するためのビデオ生成モデルです。深層学習技術に基づいており、ユーザーが入力したテキストプロンプトに基づいて対応するビデオを生成でき、効率性と柔軟性を備えています。ビデオ生成分野において重要な意味を持ち、コンテンツ制作者に強力なツールを提供し、ビデオ素材を迅速に生成することを可能にします。現在、このプロジェクトはオープンソース化されており、様々な解像度とフレームレートのビデオ生成をサポートし、詳細なインストールと使用方法ガイドを提供しています。
映像制作
59.9K

Go With The Flow
Go with the Flowは、従来の高斯ノイズの代わりにツイストノイズを用いることで、ビデオ拡散モデルのモーションモードを効率的に制御する革新的なビデオ生成技術です。元のモデルアーキテクチャを変更することなく、計算コストを増やすことなく、ビデオ内の物体やカメラの動きを正確に制御できます。主な利点として、効率性、柔軟性、拡張性が挙げられ、画像からビデオへの生成、テキストからビデオへの生成など、幅広いシーンで活用できます。Netflix Eyeline Studiosなどの研究者によって開発され、高い学術的価値と商業的応用可能性を備えており、現在オープンソースとして無料で公開されています。
映像制作
52.2K
Story Flicks
Story Flicksは、AI大規模言語モデルを基盤としたストーリーショートビデオ生成ツールです。高度な言語モデルと画像生成技術を組み合わせることで、ユーザーが入力したストーリーのテーマに基づいて、AI生成画像、ストーリー内容、音声、字幕を含む高画質ビデオを迅速に生成できます。OpenAI、阿里雲などのプラットフォームのモデルといった最新のAI技術を活用し、ユーザーに効率的で便利なコンテンツ作成方法を提供します。主に、ビデオコンテンツの迅速な生成が必要なクリエイター、教育関係者、エンターテインメント業界従事者を対象としており、効率的で低コストであるため、ユーザーの時間と労力の節約に役立ちます。
映像制作
92.5K
AIビデオスタートキット
video-starter-kitは、AIベースのビデオアプリケーションを構築するための強力なオープンソースツールキットです。Next.js、Remotion、fal.aiを基盤として構築されており、ブラウザでのAIビデオモデルの使用における複雑さを簡素化します。このツールキットは、マルチクリップビデオ合成、オーディオトラック統合、音声サポートなど、さまざまな高度なビデオ処理機能をサポートしており、メタデータエンコーディングやビデオ処理パイプラインなどの開発者フレンドリーなツールも提供しています。効率的なビデオ生成と処理を必要とする開発者やクリエイターに最適です。
映像制作
56.0K

Gamefactory
GameFactoryは、少量の『マインクラフト』ゲームビデオデータから学習し、事前学習済みのビデオ拡散モデルの事前知識を利用して新しいゲームコンテンツを生成することに特化した、革新的な汎用ワールドモデルです。この技術の核心は、そのオープンワールドな生成能力にあり、ユーザーが入力したテキストプロンプトと操作指示に基づいて、多様なゲームシーンとインタラクティブな体験を生成できます。強力なシーン生成能力を示すだけでなく、多段階トレーニング戦略とプラグ可能なアクション制御モジュールにより、高品質なインタラクティブビデオの生成を実現しています。この技術は、ゲーム開発、仮想現実、クリエイティブコンテンツ生成などの分野で幅広い応用が期待されており、現在のところ価格と商業化の戦略は明確ではありません。
ゲーム制作
51.3K
海外精選

Luma Ray2
Luma Ray2は、Lumaの新しいマルチモーダルアーキテクチャに基づいてトレーニングされた、高度なビデオ生成モデルです。Ray1と比べて10倍の計算能力を備えています。テキスト指示を理解し、画像やビデオを入力として受け入れることができ、迅速で滑らかな動き、超リアルなディテール、論理的なイベントシーケンスを備えたビデオを生成します。生成されたビデオは、プロダクションレベルに近い品質です。現在、テキストからビデオへの生成機能を提供しており、画像からビデオ、ビデオからビデオ、編集機能は近日中にリリース予定です。本製品は、ビデオクリエーター、広告会社など、高品質のビデオ生成を必要とするユーザー向けであり、現在、有料サブスクリプションユーザーのみに公開されています。公式サイトのリンクからお試しいただけます。
映像制作
62.1K
シェーダとしての拡散 (Diffusion As Shader)
Diffusion as Shader (DaS) は、3D認識に基づく拡散プロセスを通じてビデオ生成の多様な制御を実現することを目指した、革新的なビデオ生成制御モデルです。3Dトラッキングビデオを制御入力として利用し、メッシュからビデオ生成、カメラ制御、モーション転移、オブジェクト操作など、様々なビデオ制御タスクを統一アーキテクチャ内でサポートします。DaSの主な利点は、その3D認識能力であり、生成ビデオの時間的一貫性を効果的に向上させ、少量のデータで短時間で微調整することで強力な制御能力を発揮します。本モデルは、香港科技大学を始めとする複数の大学研究チームが共同で開発し、ビデオ生成技術の発展を促進し、映画制作、仮想現実などの分野に、より柔軟で効率的なソリューションを提供することを目指しています。
映像制作
51.9K

Dispose
DisPoseは、モーションフィールド誘導とキーポイント対応によってビデオ生成の質を向上させる、人物画像アニメーション制御手法です。この技術は、参照画像と駆動ビデオからビデオを生成し、モーションの整合性とアイデンティティ情報を維持します。DisPoseは、疎なモーションフィールドと参照画像から稠密なモーションフィールドを生成することで、局所的な稠密な誘導を提供しながら、疎なポーズ制御の汎化能力を維持します。さらに、参照画像からポーズキーポイントに対応する拡散特徴を抽出し、これらの点特徴をターゲットポーズに転送することで、独自のアイデンティティ情報を提供します。DisPoseの主な利点としては、追加の稠密な入力なしでより汎用的かつ効果的な制御信号を抽出できること、また、既存のモデルパラメータを凍結することなく、プラグアンドプレイ式の混合ControlNetによって生成ビデオの質と一貫性を向上させることが挙げられます。
映像制作
60.7K
如意模型 (Ruyi Models)
Ruyi-Modelsは、最大768ピクセル解像度、毎秒24フレームの映画レベルのビデオを生成できる画像からビデオへの変換モデルです。レンズ制御やモーションアンプリチュード制御にも対応しています。RTX 3090またはRTX 4090グラフィックボードを使用すれば、512ピクセル解像度、120フレームのビデオをロスレスで生成可能です。高画質ビデオ生成能力と細部への正確な制御が評価されており、映画制作、ゲーム制作、VR体験など、高画質ビデオコンテンツの生成が必要な分野で高い価値を発揮します。
映像制作
53.5K
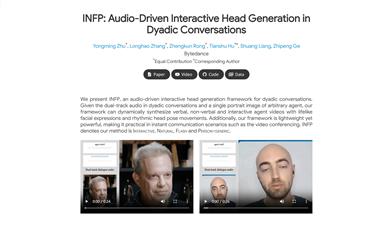
INFP
INFPは、二人間の会話用に設計された音声駆動型のインタラクティブなヘッド生成フレームワークです。二人間の会話のデュアルトラック音声と任意のエージェントの単一肖像画像から、リアルな表情とリズム感のあるヘッドポーズ動作を備えた、言語的、非言語的、インタラクティブなエージェントビデオを動的に合成します。このフレームワークは軽量かつ強力で、ビデオ会議などのリアルタイムコミュニケーションシーンに適しています。INFPは、Interactive(インタラクティブ)、Natural(自然)、Flash(高速)、Person-generic(汎用)を表します。
映像制作
54.1K
海外精選
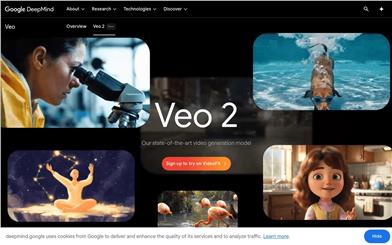
Veo 2
Veo 2は、Google DeepMindが開発した最新のビデオ生成モデルであり、ビデオ生成技術における大きな進歩を象徴しています。Veo 2は、現実世界の物理効果と幅広いビジュアルスタイルをリアルにシミュレートし、同時にシンプルで複雑な指示にも従うことができます。このモデルは、ディテール、リアリティ、アーティファクトの削減において、他のAIビデオモデルを大きく凌駕しています。Veo 2の高度なモーション制御機能により、正確な動き表現が可能になり、詳細な指示にも正確に従って、様々なショットスタイル、アングル、モーションを作成できます。Veo 2は、ビデオコンテンツの多様性と品質を向上させることで、映画制作、ゲーム開発、バーチャルリアリティなどの分野に強力な技術サポートを提供します。
映像制作
79.8K
- 1
- 2
- 3
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M