%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Stable Virtual Camera
紹介 :
Stable Virtual Cameraは、Stability AIが開発した13億パラメーターの汎用拡散モデルであり、Transformer画像からビデオへの変換モデルです。その重要性は、新しいビュー合成(NVS)に技術的なサポートを提供することであり、入力ビューとターゲットカメラに基づいて、3D整合性のある新しいシーンビューを生成できます。主な利点としては、ターゲットカメラの軌跡を自由に指定でき、大きな視点の変化と時間的に滑らかなサンプルを生成でき、追加のニューラル放射場(NeRF)蒸留なしで高い整合性を維持でき、さらに最長30秒の高品質でシームレスなループビデオを生成できることが挙げられます。このモデルは、研究および非商業目的でのみ無料で使用でき、研究者や非商業クリエイターに革新的な画像からビデオへの変換ソリューションを提供することを目的としています。
ターゲットユーザー :
「主な対象ユーザーは、研究者、アーティスト、デザイナー、教育者です。研究者にとっては、新しいビュー合成、再構成モデルなどの研究に使用でき、モデルの性能と限界を探るのに役立ちます。アーティストやデザイナーは、これを使用してユニークなシーンビューや創造的な素材を生成し、作品の内容と視覚効果を豊かにすることができます。教育者は、より生き生きとした方法で知識を示し、教育効果を高めるために、教育ツールに適用できます。」
使用シナリオ
1. 研究者はこのモデルを使用して、さまざまなシーンにおけるビュー合成効果を研究し、ターゲットカメラの軌跡を調整することで、モデルが生成した新しいビューの3D整合性におけるパフォーマンスを分析します。
2. デジタルペインティング作品を作成するアーティストは、Stable Virtual Cameraが生成するさまざまな視点のシーンビューを使用してインスピレーションを得て、ユニークな視点を持つアート作品を作成します。
3. 教師は、建築構造に関する教育ビデオを作成する際に、このモデルを使用して建築物のさまざまな角度の3Dビューを生成し、生徒が建築構造をより直感的に理解するのに役立てます。
製品特徴
- **新しいビュー合成**: 入力された複数のビューとターゲットカメラに基づいて、3D整合性のある新しいシーンビューを生成し、シーン作成により多くの視点の選択肢を提供します。
- **自由な軌跡設定**: ユーザーはターゲットカメラの軌跡を自由に指定でき、広い空間範囲にわたって、多様な創作ニーズを満たします。
- **大きな視点変化の生成**: 大きな視点の変化のあるサンプルを生成でき、ビデオコンテンツの表示効果を豊かにし、視聴者に斬新な視覚体験をもたらします。
- **時間的な滑らかな処理**: 生成されたサンプルは時間的に滑らかで、ビデオの遷移が自然になり、視聴体験が向上します。
- **合成プロセスの簡素化**: 追加のNeRF蒸留なしで高い整合性を維持でき、ビュー合成のプロセスを簡素化し、創作効率を向上させます。
- **高品質な長尺ビデオの生成**: 高品質で最長30秒の長尺ビデオを生成でき、シームレスなループ機能を備えているため、さまざまな創作シーンに適しています。
- **アート創作のサポート**: アート作品の作成に使用したり、デザインやその他の芸術創作のプロセスで素材や創造的なインスピレーションを提供したりできます。
- **教育と研究への支援**: 教育ツールやクリエイティブツールの技術サポートを提供し、研究者による再構成モデルの研究や、モデルの能力の限界を探るためにも役立ちます。
使用チュートリアル
1. プロジェクトのGitHubリポジトリにアクセスし、このモデルを使用するための関連コードとドキュメントを取得します。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. GitHubの説明に従って、必要な依存関係のインストールなど、モデルを実行するために必要な環境を準備します。
3. 新しいビューを生成するために使用する入力ビューデータを集め、データがモデルの要件を満たす形式であることを確認します。
4. クリエイティブなニーズに応じて、ターゲットカメラの軌跡を決定し、生成したい新しいビューの視点とモーションパスを明確にします。
5. 入力ビューデータとターゲットカメラの軌跡情報を、モデルの入力仕様に従って設定します。
6. コードを実行し、モデルを使用して新しいシーンビューとビデオを生成します。
7. 生成された結果を分析して調整します。満足できない場合は、入力データまたはカメラの軌跡を変更し、期待どおりの結果が得られるまでモデルを再実行します。








おすすめAI製品
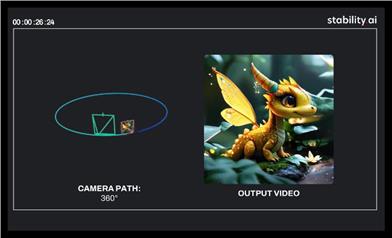
Stable Virtual Camera
Stable Virtual Cameraは、Stability AIが開発した13億パラメーターの汎用拡散モデルであり、Transformer画像からビデオへの変換モデルです。その重要性は、新しいビュー合成(NVS)に技術的なサポートを提供することであり、入力ビューとターゲットカメラに基づいて、3D整合性のある新しいシーンビューを生成できます。主な利点としては、ターゲットカメラの軌跡を自由に指定でき、大きな視点の変化と時間的に滑らかなサンプルを生成でき、追加のニューラル放射場(NeRF)蒸留なしで高い整合性を維持でき、さらに最長30秒の高品質でシームレスなループビデオを生成できることが挙げられます。このモデルは、研究および非商業目的でのみ無料で使用でき、研究者や非商業クリエイターに革新的な画像からビデオへの変換ソリューションを提供することを目的としています。
ビデオ アップデート
52.2K
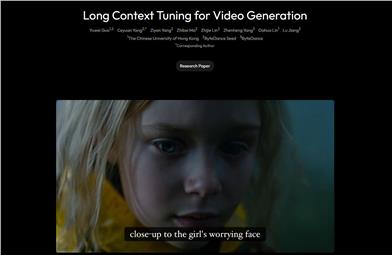
ロングコンテキスト最適化(LCT)
ロングコンテキスト最適化(LCT)は、現在の単一生成能力と現実のナラティブビデオ制作とのギャップを解消することを目的としています。この技術は、データ駆動型のアプローチを使用してシーンレベルの一貫性を直接学習し、インタラクティブなマルチカメラ開発と合成生成をサポートしており、ビデオ制作のあらゆる側面に適用できます。
ビデオ アップデート
48.0K