%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Phantom
Phantomは、クロスモーダルアライメントにより主体の一貫性を維持した動画生成を実現する、先進的な動画生成技術です。一枚または複数枚の参照画像から、生き生きとした動画コンテンツを生成し、同時に主体のアイデンティティの特徴を厳密に保持します。この技術は、コンテンツ制作、仮想現実、広告などの分野で重要な応用価値を持ち、制作者に効率的で創造的な動画生成ソリューションを提供します。Phantomの主な利点としては、高い主体の一貫性、豊富な動画の詳細、強力なマルチモーダルインタラクション能力が挙げられます。
映像制作
57.1K
Pippo
Pippoは、Meta Reality Labsと複数の大学が共同開発した生成モデルであり、一枚の普通の画像から高解像度の複数視点ビデオを生成できます。この技術の最大の強みは、追加の入力(パラメータ化モデルやカメラパラメータなど)なしで、高品質な1K解像度のビデオを生成できる点です。多視点拡散トランスフォーマーアーキテクチャに基づいており、仮想現実、映画制作など、幅広い応用が期待できます。Pippoのコードはオープンソースですが、事前学習済みウェイトは含まれておらず、ユーザーは自分でモデルをトレーニングする必要があります。
映像制作
67.3K

Gamefactory
GameFactoryは、少量の『マインクラフト』ゲームビデオデータから学習し、事前学習済みのビデオ拡散モデルの事前知識を利用して新しいゲームコンテンツを生成することに特化した、革新的な汎用ワールドモデルです。この技術の核心は、そのオープンワールドな生成能力にあり、ユーザーが入力したテキストプロンプトと操作指示に基づいて、多様なゲームシーンとインタラクティブな体験を生成できます。強力なシーン生成能力を示すだけでなく、多段階トレーニング戦略とプラグ可能なアクション制御モジュールにより、高品質なインタラクティブビデオの生成を実現しています。この技術は、ゲーム開発、仮想現実、クリエイティブコンテンツ生成などの分野で幅広い応用が期待されており、現在のところ価格と商業化の戦略は明確ではありません。
ゲーム制作
52.2K

SCENICモデル
SCENICは、テキスト条件に基づくシーンインタラクションモデルです。様々な地形を持つ複雑なシーンにも対応し、自然言語を用いたユーザー指定の意味的制御をサポートします。ユーザーが指定した軌跡を副目標、テキストプロンプトを指示として用いて3Dシーン内をナビゲートします。SCENICは階層的推論によるシーン理解と、動きとテキスト間のフレームアライメントを組み合わせることで、様々な動作スタイル間のシームレスな遷移を実現します。この技術の重要性は、現実の物理法則とユーザー指示に沿ったキャラクターナビゲーション動作を生成できる点にあり、仮想現実、拡張現実、ゲーム開発などの分野で大きな意義を持ちます。
ゲーム開発
44.7K
Genex
GenExは、一枚の画像から完全に探検可能な360°3D世界を作成できるAIモデルです。ユーザーは生成された世界をインタラクティブに探索できます。GenExは想像空間における具現化AIを推進し、これらの能力を現実世界の探査に拡張する可能性を秘めています。
3Dモデリング
63.2K
SOLAMI
SOLAMIは、3D自律型キャラクターとの没入型インタラクションを可能にする、エンドツーエンドのソーシャル視覚?言語?動作(VLA)モデリングフレームワークです。このフレームワークは、ソーシャルVLAアーキテクチャ、インタラクティブなマルチモーダルデータ、没入型VRインターフェースという3つの主要な側面を統合することで、3D自律型キャラクターを構築します。SOLAMIの主な利点としては、より正確で自然なキャラクター応答(音声と動作を含む)、ユーザーの期待に沿った応答、そして低い遅延などが挙げられます。この技術の重要性は、3D自律型キャラクターに人間のようなソーシャルインテリジェンスを提供し、人間を感知、理解、そして人間とインタラクションすることを可能にする点にあります。これは、人工知能分野における未解決の基本的な課題です。
AI顔色生成
46.4K
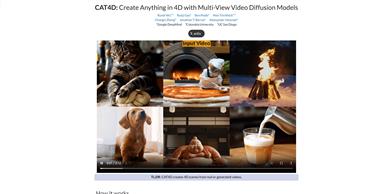
CAT4D
CAT4Dは、単眼ビデオから多視点ビデオ拡散モデルを用いて4Dシーンを生成する技術です。単眼ビデオを入力として、多視点ビデオに変換し、動的な3Dシーンを再構築します。この技術の重要性は、単一視点のビデオデータから三次元空間と時間の情報を完全に抽出し、再構築できる点にあります。仮想現実、拡張現実、3Dモデリングなどの分野に強力な技術サポートを提供します。製品背景情報によると、CAT4DはGoogle DeepMind、コロンビア大学、UCサンディエゴの研究者によって共同開発され、最先端の研究成果を実用化に移した事例です。
3Dモデリング
50.5K
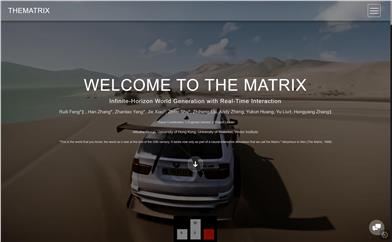
マトリックス
マトリックスは、AI技術を用いて没入型でインタラクティブなデジタル宇宙を作り出し、現実と幻想の境界線を曖昧にする先駆的なプロジェクトです。フレーム単位の正確なユーザーインタラクション、AAA級のビジュアル効果、無限の生成能力を提供することで、既存のビデオモデルの限界を突破し、ユーザーに無限の探求体験をもたらします。アリババグループ、香港大学、ウォータールー大学、ベクター研究所が共同開発したマトリックスは、世界シミュレーション技術の新たな高みを示しています。
仮想現実
48.0K
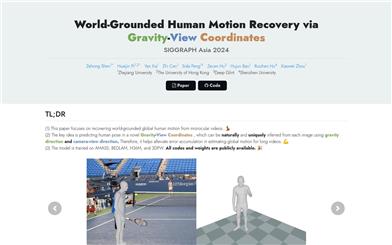
GVHMR
GVHMRは、単眼ビデオから世界座標系における人体運動を復元するという課題に対し、重力視点座標系を用いることで解決策を提供する革新的な人体運動復元技術です。本技術は、画像と姿勢のマッピング学習における曖昧性を低減し、自己回帰法における連続画像の累積誤差を回避します。GVHMRは野外ベンチマークテストにおいて優れた性能を示し、精度と速度において既存の最先端技術を凌駕しています。さらに、トレーニングプロセスとモデルウェイトは公開されており、高い研究的および実用的な価値を有しています。
AIモデル
54.6K

Omnire
OmniReは、デバイスログを用いて高保真な動的都市景観を効率的に再構築するための包括的な手法です。ガウス表現に基づく動的神経シーングラフの構築と、車両、歩行者、自転車乗りなどの様々な動的行動者をシミュレートするための複数の局所正規空間の構築により、シーン内の様々なオブジェクトを包括的に再構築します。OmniReは、シーンに存在する様々なオブジェクトを包括的に再構築し、その後、全ての参加者のリアルタイム参加による再構築シーンのシミュレーションを可能にします。Waymoデータセット上での広範な評価により、OmniReは定量的にも定性的にも、従来最先端の手法を大幅に凌駕することが示されました。
AI画像生成
49.7K
Avp Teleoperate
これは、人型ロボットUnitree H1_2の遠隔操作を実現するオープンソースプロジェクトです。Apple Vision Pro技術を活用し、ユーザーは仮想現実環境を通じてロボットを制御できます。Ubuntu 20.04およびUbuntu 22.04でテスト済みであり、詳細なインストールと設定ガイドを提供しています。この技術の主な利点としては、没入型の遠隔操作体験を提供できること、およびシミュレーション環境でのテストをサポートすることで、ロボット遠隔操作分野に新たなソリューションを提供することなどが挙げられます。
AIエージェント
49.7K

Controlmm
ControlMMは、プラグアンドプレイ式のマルチモーダル制御機能を備えた全身運動生成フレームワークです。テキストからモーション(Text-to-Motion)、音声からジェスチャー(Speech-to-Gesture)、音楽からダンス(Music-to-Dance)など、複数の分野において堅牢なモーションを生成できます。本モデルは、制御性、シーケンシャル性、モーションの自然さに優れた特性を備え、AI分野における新たなモーション生成ソリューションを提供します。
AIモデル
70.1K
海外精選
Aiuni
Aiuniは、3D仮想世界体験を提供するプラットフォームです。ユーザーはここで個性的な3Dモデルを作成し、没入型の宇宙探査の旅を楽しむことができます。Aiuniは革新的な3D技術、豊富なインタラクション性、高度なパーソナライズされたカスタマイズにより、ユーザーに全く新しい仮想体験空間を提供します。
3Dモデリング
463.4K
高品質新製品
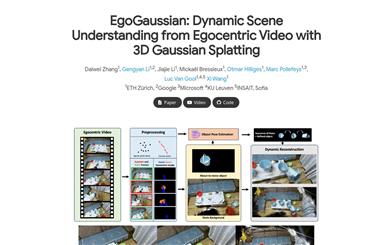
Egogaussian
EgoGaussianは、RGB一人称視点入力のみを用いて、3Dシーンの再構築と物体の動きの動的追跡を同時に行う、高度な3Dシーン再構築と動体追跡技術です。この技術は、ガウス散乱の独自の離散特性を利用して動的インタラクションを背景から分離し、セグメントレベルのオンライン学習プロセスを通じて、人間の活動の動的特性を利用して、時間順序でシーンの進化を再構築し、剛体の運動を追跡します。EgoGaussianは、野外ビデオの課題において、以前のNeRFや動的ガウス法を凌駕し、再構築モデルの質においても優れた性能を示しています。
AI 3Dツール
45.8K
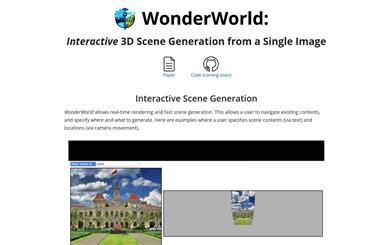
Wonderworld
WonderWorldは革新的な3Dシーン拡張フレームワークです。ユーザーは単一の入力画像とユーザー指定のテキストに基づいて、仮想環境を探求し、形成することができます。高速ガウシアンボクセルとガイド付き拡散による深度推定手法により、計算時間を大幅に削減し、幾何学的に整合性の取れた拡張を生成します。これにより、3Dシーンの生成時間を10秒未満に短縮し、リアルタイムでのユーザーインタラクションと探索を可能にします。これは、仮想現実、ゲーム、クリエイティブデザインなどの分野において、没入型仮想世界の迅速な生成とナビゲーションの可能性を提供します。
AI画像生成
58.2K

Unique3d
Unique3Dは、清華大学チームが開発した技術であり、一枚の画像から高忠実度のテクスチャ付き3Dメッシュモデルを生成できます。この技術は画像処理と3Dモデリングの分野において重要な意味を持ち、ユーザーは2D画像を迅速に3Dモデルに変換できるため、ゲーム開発、アニメーション制作、仮想現実などの分野に強力な技術サポートを提供します。
AI 3Dツール
126.4K
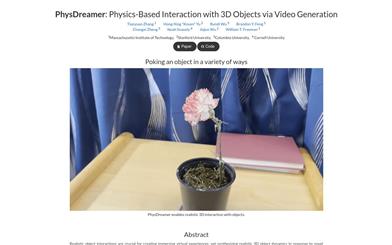
Physdreamer
PhysDreamerは、ビデオ生成モデルによって学習されたオブジェクトの動力学の事前知識を活用することで、静的な3Dオブジェクトにインタラクティブな動力学を与える物理ベースの手法です。この手法により、現実の物体の物理的属性データが不足している場合でも、新たなインタラクション(外力や代理操作など)に対するリアルな反応をシミュレートできます。PhysDreamerは、ユーザー調査によって合成されたインタラクションのリアリティを評価し、より魅力的でリアルな仮想体験の発展を促進します。
AI 3Dツール
95.2K
Champ
Champは、陰関数と畳み込みニューラルネットワークを組み合わせることで、高品質で多様性があり、リアルな3D形状を生成する生成モデルです。動物、乗り物、家具など、様々な種類の形状を生成できます。
AI画像生成
80.9K
VIGGLE
VIGGLEは、JST-1ビデオ3Dベースモデルに基づいた、制御可能なビデオ生成ツールです。あらゆるキャラクターを、ユーザーの指示に従って動かすことができます。JST-1は、現実世界の物理法則を理解する能力を持つ、最初のビデオ3Dベースモデルです。VIGGLEは強力なビデオ生成と制御機能を備え、ユーザーのニーズに合わせて様々なアクションやストーリーのビデオを生成できます。ビデオクリエイター、アニメーター、コンテンツクリエイターなどのプロフェッショナルを対象とし、より効率的なビデオ制作を支援します。現在VIGGLEはテスト段階にあり、将来的には有料サブスクリプション版の提供を予定しています。
映像制作
2.2M
Depthify.ai
Depthify.aiは、RGB画像をApple Vision ProやMeta Questと互換性のある様々な空間フォーマットに変換できるツールです。RGB画像を空間写真に変換することで、様々なコンピュータビジョンや3Dモデリングアプリケーションをサポートします。深度マップ、立体画像、HEICファイルを作成でき、Apple Vision Proで使用可能です。
画像編集
99.6K

Ultravatar
UltrAvatarは、仮想世界と現実世界の体験のギャップを縮めることを目指した、リアルで動きの自然な3Dアバター生成モデルです。スコア蒸留サンプリング(SDS)損失、微分可能なレンダラー、およびテキスト条件を用いて拡散モデルによる3Dアバター生成を導きます。既存の作品と比較して、UltrAvatarは幾何学的忠実度と優れた物理レンダリングによるテクスチャ品質を向上させることで、革新的な3Dアバター生成手法を実現しています。拡散カラー抽出モデルとリアルタイム誘導テクスチャ拡散モデルを用いることで、不要な照明効果を除去し、現実的な拡散カラーを実現し、生成されたアバターは様々な照明条件下でも自然な表現が可能です。実験を通して、本手法の有効性と堅牢性を証明し、既存の最先端手法を大きく上回る結果を得ています。
AI顔画像生成
80.9K

DL3DV 10K
DL3DV-10Kは、1万本を超える高品質ビデオを含む大規模な実写データセットです。各ビデオには、シーンのキーポイントと複雑さが手動でアノテーションされており、カメラポーズ、NeRF推定深度、点群、3Dメッシュなども提供されています。本データセットは、汎用NeRF研究、シーンの一貫性トラッキング、ビジョン言語モデルなど、コンピュータビジョン研究に利用できます。
AI画像生成
50.0K

Zeronvs
ZeroNVSは、単一の実画像からゼロショットで360度全景合成を行うツールです。3D SDS蒸留コード、評価コード、および訓練済みモデルを提供します。ユーザーはこれを使用して独自のNeRFモデルの蒸留と評価を行い、様々なデータセットで実験できます。ZeroNVSは高品質な合成効果を備え、カスタム画像データにも対応しています。仮想現実、拡張現実、パノラマ動画制作などの分野で活用できます。
AI 3Dツール
91.6K

Lumaai Genie
Genieは、Lumaの3D生成基礎モデルの研究プレビュー版です。デザイン、創作、エンターテインメントなど様々な分野で活用できる、多様な3Dモデルを生成できます。形状生成、テクスチャ作成、アニメーション作成など、豊富な機能を提供しています。ゲーム開発、仮想現実、映画の特殊効果など、幅広い分野への応用が可能です。Genieの価格と位置付けは正式リリース前に決定されます。
AI 3Dツール
600.3K
Illusion Diffusion
Illusion Diffusionは、ユーザーが自分のアバターを作成し、他のユーザーとソーシャルインタラクションを楽しめる仮想現実ソーシャルプラットフォームです。ヘッドマウントディスプレイやスマートフォンなど、様々なVRデバイスに対応しており、ジェスチャーや音声操作が可能です。多様な仮想空間やゲームを提供し、ユーザーは仮想世界を自由に探索し、体験することができます。Illusion Diffusionは柔軟な価格設定を採用しており、無料プランと有料プランを用意しています。
AIバーチャルフレンド
57.4K
Every Anyone
Every Anyoneは、人工知能技術を用いて構築された超リアルなメタバースです。無限の可能性を秘めた仮想空間を提供し、ユーザーはそこで創造、交流、体験を楽しむことができます。個人用仮想アバターの作成、ソーシャルアクティビティへの参加、デジタル資産の売買、そしてVRアプリケーションのカスタマイズや開発など、多様な機能を備えています。現実世界の枠を超え、誰もが自分だけの仮想世界を持つことを目指しています。価格に関する詳細は、公式ウェブサイトをご覧ください。
AI画像生成
45.3K
Pix2pix Video
Pix2Pix Videoは、画像をリアルな動画に変換できる小さなプログラムです。Pix2Pixモデルを使用し、高品質な動画を生成することで、静止画に命を吹き込みます。シンプルで使いやすいインターフェースを備え、ユーザーは画像をアップロードしてパラメーターを設定するだけで、驚くほど美しい動画を作成できます。アニメーション制作、仮想現実、特殊効果の追加など、様々なシーンで活用可能です。Pix2Pix Videoは、無限の可能性を秘めた強力な画像処理ツールです。
AI動画生成
88.0K

Teachr
teachrは、インタラクティブで魅力的なオンラインコースの作成と販売を支援する、ユーザーフレンドリーなプラットフォームです。AIサポート、Stripe統合、収益化機能を提供しています。teachrを使えば、オンラインコースを迅速かつ簡単に作成し、世界中の人々とあなたの知識を共有できます。
学習教育
45.5K
In3d
in3Dは、スマートフォンカメラだけで1分以内に人物をリアルな全身3Dアバターに変換します。in3DアバターSDKを使用して、お好みの製品に統合できます。
AI顔色生成
54.4K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
42.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
41.7K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.3K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
40.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
41.7K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
40.0K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M