%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Transformer
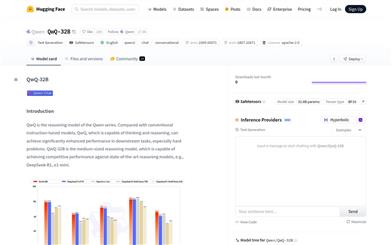
Qwq 32B
QwQ-32B is a reasoning model from the Qwen series, focusing on the ability to think and reason through complex problems. It excels in downstream tasks, especially in solving difficult problems. Based on the Qwen2.5 architecture, it has been optimized through pre-training and reinforcement learning, boasting 32.5 billion parameters and supporting a context length of up to 131,072 tokens. Its main advantages include powerful reasoning capabilities, efficient long-text processing capabilities, and flexible deployment options. This model is suitable for scenarios requiring deep thinking and complex reasoning, such as academic research, programming assistance, and creative writing.
AI Model
50.8K

ART
ART is a deep learning-based image generation technology focused on generating variable multi-layered transparent images. Through anonymous region layout and Transformer architecture, it achieves efficient multi-layered image generation. The main advantages of this technology include efficiency, flexibility, and support for multi-layered image generation. It is suitable for scenarios requiring precise control of image layers, such as graphic design and visual effects. The price and specific positioning are not explicitly mentioned, but its technical characteristics suggest it may be aimed at professional users and enterprise applications.
AI design tools
52.2K
Moba
MoBA (Mixture of Block Attention) is an innovative attention mechanism specifically designed for large language models dealing with long text contexts. It achieves efficient long sequence processing by dividing the context into blocks and allowing each query token to learn to focus on the most relevant blocks. MoBA's main advantage is its ability to seamlessly switch between full attention and sparse attention, ensuring performance while improving computational efficiency. This technology is suitable for tasks that require processing long texts, such as document analysis and code generation, and can significantly reduce computational costs while maintaining high model performance. The open-source implementation of MoBA provides researchers and developers with a powerful tool, driving the application of large language models in long text processing.
Model Training and Deployment
51.6K
Makeanything
MakeAnything is a diffusion transformer-based model focused on multi-domain procedural sequence generation. By combining advanced diffusion models and transformer architecture, it can generate high-quality, step-by-step creative sequences, such as paintings, sculptures, icon designs, and more. Its main advantage lies in its ability to handle generative tasks across multiple domains and quickly adapt to new domains with a small number of samples. Developed by the Show Lab team at the National University of Singapore, this model is currently available as open-source, aiming to promote the development of multi-domain generation technology.
AI design tools
55.5K
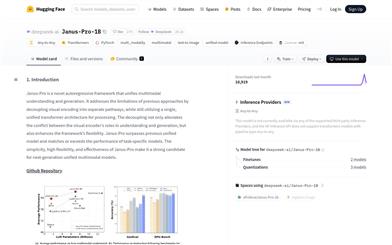
Janus Pro 1B
Janus-Pro-1B is an innovative multi-modal model that focuses on unified multi-modal understanding and generation. By utilizing separate visual encoding paths, it addresses the conflict seen in traditional methods for understanding and generation tasks, all while maintaining a single unified Transformer architecture. This design not only enhances the model’s flexibility but also ensures outstanding performance across multi-modal tasks, often surpassing models tailored for specific tasks. Built on the DeepSeek-LLM-1.5b-base/DeepSeek-LLM-7b-base architectures, the model employs SigLIP-L as its visual encoder, supports 384x384 image inputs, and utilizes a specialized image generation tokenizer. Its open-source nature and flexibility position it as a strong candidate for next-generation multi-modal models.
AI Model
75.3K
Vitpose
ViTPose is a series of human pose estimation models based on the Transformer architecture. It leverages the powerful feature extraction capabilities of Transformers to provide a simple yet effective baseline for human pose estimation tasks. The ViTPose models perform exceptionally well across various datasets, demonstrating high accuracy and efficiency. Maintained and updated by the community at the University of Sydney, the model offers various versions of different scales to meet diverse application needs. The ViTPose models are open-sourced on the Hugging Face platform, allowing users to easily download and deploy these models for human pose estimation research and application development.
AI Model
47.7K
Modernbert Large
ModernBERT-large is a state-of-the-art bidirectional encoder Transformer model (BERT style) pre-trained on 2 trillion tokens of English and code data, with a native context length of up to 8192 tokens. This model incorporates the latest architectural improvements such as Rotary Positional Embeddings (RoPE) for long-context support, local-global alternating attention for enhanced efficiency with long inputs, and padding-free and Flash Attention for improved inference speed. ModernBERT-long is suitable for tasks involving the handling of long documents, such as retrieval, classification, and semantic search within large corpora. The training data primarily consists of English and code, which may result in lower performance with other languages.
AI Search
50.2K
Modernbert
ModernBERT is a next-generation encoder model co-released by Answer.AI and LightOn. It is a comprehensive upgrade of the BERT model, offering longer sequence lengths, better downstream performance, and faster processing speeds. ModernBERT leverages the latest Transformer architecture improvements, with a strong focus on efficiency, trained on modern data scales and sources. As an encoder model, it excels in a variety of natural language processing tasks, particularly in code search and understanding. It is available in two model sizes: a base version (139M parameters) and a large version (395M parameters), suitable for diverse application needs.
AI Model
45.8K
Llama 3.3 70B Instruct
Llama-3.3-70B-Instruct is a large language model with 70 billion parameters developed by Meta, specifically optimized for multilingual dialogue scenarios. This model utilizes an optimized transformer architecture and enhances its utility and safety through supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF). It supports multiple languages and is proficient in handling text generation tasks, making it a significant advancement in the field of natural language processing.
Chatbot
52.2K
Olmo 2 13B
OLMo 2 13B is a transformer-based autoregressive language model developed by the Allen Institute for AI (AI2), focusing on English academic benchmark testing. During training, it utilized up to 50 trillion tokens, demonstrating performance comparable to or even superior to similarly sized open models, and competing with the open-weight models from Meta and Mistral on English academic benchmarks. The release of OLMo 2 13B includes all code, checkpoints, logs, and relevant training details, aimed at advancing scientific research in language models.
AI Model
46.9K
Star Attention
Star-Attention is a novel block-sparse attention mechanism proposed by NVIDIA aimed at improving the inference efficiency of large language models (LLMs) based on Transformers for long sequences. This technology significantly boosts inference speed through a two-stage operation while maintaining an accuracy rate of 95-100%. It is compatible with most Transformer-based LLMs, allowing for direct use without additional training or fine-tuning, and can be combined with other optimization methods such as Flash Attention and KV cache compression techniques to further enhance performance.
Model Training and Deployment
48.0K
Mobilellm 1B
An autoregressive language model developed by Meta with an optimized architecture, making it ideal for resource-constrained devices. It boasts various advantages, including the integration of multiple technologies and support for zero-shot inference. It is free to access, targeting researchers and developers in natural language processing.
AI Model
46.1K
Mobilellm 600M
MobileLLM-600M is an autoregressive language model developed by Meta, employing an optimized Transformer architecture specifically designed for resource-constrained device applications. This model incorporates key technologies such as the SwiGLU activation function, a deep and thin architecture, shared embeddings, and grouped query attention. MobileLLM-600M has shown a significant performance increase in zero-shot common sense reasoning tasks, achieving accuracy improvements of 2.7% and 4.3% compared to previous state-of-the-art models with 125M and 350M parameters, respectively. The design philosophy behind this model can be scaled to larger models, such as MobileLLM-1B and 1.5B, both of which have achieved state-of-the-art results.
AI Model
43.6K
Mobilellm 350M
MobileLLM-350M is an autoregressive language model developed by Meta, utilizing an optimized Transformer architecture tailored for device-side applications to meet the needs of resource-constrained environments. The model integrates key technologies such as SwiGLU activation function, deep thin architecture, embedding sharing, and grouped query attention, resulting in significant accuracy improvements in zero-shot commonsense reasoning tasks. MobileLLM-350M offers performance comparable to larger models while maintaining a small model size, making it an ideal choice for natural language processing applications on devices.
AI Model
44.7K

Oasis
Oasis is the first playable, real-time, open-world AI model developed by Decart AI. It is an interactive video game entirely generated end-to-end using a Transformer, based on frame-by-frame generation. Oasis can receive user keyboard and mouse inputs to generate gameplay in real-time, internally simulating physics, game rules, and graphics. The model learns from direct gameplay observations, enabling users to move, jump, pick up items, destroy blocks, and more. Oasis is viewed as the first step toward researching more complex interactive worlds and may potentially replace traditional game engines in the future. Its implementation requires improvements in model architecture and breakthroughs in inference technology to facilitate real-time interaction with users. Decart AI employs the latest diffusion training and Transformer modeling methods, combining them with large language models (LLMs) to train an autoregressive model capable of generating video based on user actions. In addition, Decart AI has developed a proprietary inference framework to maximize the utilization of the NVIDIA H100 Tensor Core GPU and support the upcoming Sohu chip from Etched.
Game Production
101.6K
SLM Survey
SLM_Survey is a dedicated research project focused on small language models (SLMs), aiming to provide an in-depth understanding and technical assessment of these models through research and measurement. The project covers transformer-based, decoder-only language models with parameter sizes ranging from 100M to 5B. By investigating 59 state-of-the-art open-source SLMs, it analyzes their technological innovations and evaluates their capabilities across multiple domains, including common-sense reasoning, context learning, mathematics, and programming. Additionally, runtime costs such as inference latency and memory usage have been benchmarked. This research is of significant value in advancing the study of SLMs.
AI Science Research
46.1K

ACE: All Round Creator And Editor Following Instructions Via Diffusion Transformer
ACE is a diffusion transformer-based all-in-one creator and editor that facilitates joint training of multiple visual generation tasks using a unified input format known as Long-context Condition Unit (LCU). ACE addresses the challenge of insufficient training data through efficient data collection methods and generates accurate textual instructions using multimodal large language models. It demonstrates significant performance advantages in the realm of visual generation, enabling the creation of chat systems that seamlessly respond to any image creation request, thus circumventing the cumbersome workflows typically employed by visual agents.
AI image generation
53.3K
Fresh Picks
Llama 3.2 1B
Llama-3.2-1B is a multilingual large language model released by Meta, focusing on text generation tasks. The model utilizes an optimized Transformer architecture and is fine-tuned through supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) to align with human preferences for usefulness and safety. It supports eight languages, including English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai, and demonstrates excellent performance across various conversational use cases.
AI Model
51.1K
Opencity
OpenCity is an open-source spatiotemporal foundation model focused on the field of traffic prediction. The model effectively captures and standardizes complex spatiotemporal dependencies in traffic data by integrating the Transformer architecture and graph neural networks, enabling zero-shot generalization across different urban environments. It is pre-trained on large-scale, heterogeneous traffic datasets to learn rich, generalizable representations that can be seamlessly applied to various traffic prediction scenarios.
AI Model
46.6K

Bailing TTS
Bailing-TTS is a series of large-scale text-to-speech (TTS) models developed by Giant Network's AI Lab, focused on generating high-quality Chinese dialect voices. The model employs continuous semi-supervised learning and a specific Transformer architecture, effectively aligning text and speech markers through a multi-stage training process to achieve high-quality dialect speech synthesis. Bailing-TTS has demonstrated speech synthesis results that closely resemble natural human expression, holding significant relevance in the field of dialect speech synthesis.
AI Speech Synthesis
151.2K
Fresh Picks
Mindsearch
MindSearch is a multi-agent network search engine framework based on large language models (LLM), with performance akin to Perplexity.ai Pro. Users can easily deploy their own search engines, supporting both proprietary large language models (such as GPT and Claude) and open-source large language models (like InternLM2.5-7b-chat). It features the ability to tackle any real-world problem by utilizing internet knowledge to provide in-depth and comprehensive knowledge base answers; displays detailed solution pathways to improve the credibility and usability of final responses; offers an optimized UI experience with various interface options including React, Gradio, Streamlit, and Terminal; and dynamically constructs graphs that break down user queries into atomic sub-problems within the graph, progressively expanding it based on WebSearcher results.
AI search engine
159.0K
Tele FLM 1T
Tele-FLM-1T is an open-source 1T multilingual large language model, based on a decoder-only Transformer architecture, trained on approximately 2 trillion tokens. The model demonstrates outstanding performance at scale, sometimes even surpassing larger models. In addition to sharing the model weights, it also provides core design, engineering practices, and training details, with the expectation of benefiting both the academic and industrial communities.
AI Model
45.3K
Fresh Picks
DCLM 7B
DCLM-Baseline-7B is a 700 million parameter language model developed by the DataComp for Language Models (DCLM) team, primarily in English. The model aims to improve the performance of language models by using systematic data organization technology. The model training uses PyTorch and the OpenLM framework, the optimizer is AdamW, the learning rate is 2e-3, the weight decay is 0.05, the batch size is 2048 sequences, the sequence length is 2048 tokens, and the total training tokens has reached 2.5 trillion. The training hardware uses the H100 GPU.
AI Model
58.2K
Fresh Picks
Mamba Codestral 7B V0.1
Mamba-Codestral-7B-v0.1 is an open-source code model developed by the Mistral AI Team based on the Mamba2 architecture. It has comparable performance to cutting-edge Transformer-based code models. It performs well in multiple industry-standard benchmark tests and provides advanced code generation and comprehension capabilities, suitable for programming and software development.
AI code generation
53.8K
Flashattention
FlashAttention is an open-source attention mechanism library designed specifically for Transformer models in deep learning to enhance computational efficiency and memory usage. It optimizes attention calculation using IO-aware methods, reducing memory consumption while maintaining precise computational results. FlashAttention-2 further improves parallelism and workload distribution, while FlashAttention-3 is optimized for Hopper GPUs, supporting FP16 and BF16 data types.
AI Model
46.9K
Videollama2 7B 16F Base
VideoLLaMA2-7B-16F-Base is a large video language model developed by the DAMO-NLP-SG team, focusing on Visual Question Answering (VQA) and video subtitling generation. Combining advanced space-time modeling and audio understanding capabilities, it provides strong support for multi-modal video content analysis. It demonstrates excellent performance in visual question answering and video subtitling generation tasks, capable of handling complex video content and generating accurate descriptions and answers.
AI video generation
54.4K
Fresh Picks

Spacebyte
SpaceByte is a brand new byte-level decoding architecture designed to address some drawbacks associated with the widely used Tokenization technique in large-scale language models. While Tokenization can significantly enhance model performance, it also introduces various defects such as performance bias, increased vulnerability to adversarial attacks, reduced character-level modeling effectiveness, and increased model complexity. Building upon the advantages of Tokenization, SpaceByte effectively resolves these issues. It leverages byte-level Transformers as the foundation and inserts larger Transformer blocks at model layers, particularly when encountering bytes that typically mark word boundaries such as spaces. Under the same training and inference computational resource budget, this architecture not only outperforms other byte-level models but also matches the performance of Tokenization-based Transformer models.
AI Model
45.8K
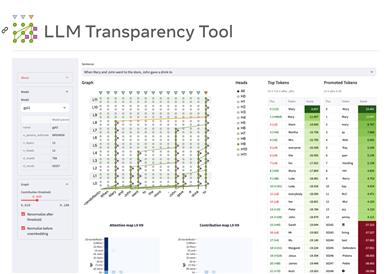
LLM Transparency Tool
The LLM Transparency Tool (LLM-TT) is an open-source, interactive toolkit for analyzing the inner workings of Transformer-based language models. It allows users to select a model, add prompts, and run inference, visualizing the model's attention flow and information transfer paths. This tool aims to increase model transparency, helping researchers and developers better understand and improve language models.
AI Model
60.7K
Infini Attention
Google's Infini-attention technology aims to extend Transformer-based large language models to handle infinitely long inputs. It achieves this by utilizing a compressed memory mechanism and has demonstrated excellent performance on multiple long-sequence tasks. The technique includes a compressed memory mechanism, the combination of local and long-range attention, and streaming capabilities. Experimental results show performance advantages in long-context language modeling, key-context block retrieval, and book summarization tasks.
AI Model
51.1K
Qwen1.5 32B
Qwen1.5 is a decoder language model series based on the Transformer architecture, including models of various sizes. It features SwiGLU activation, attention QKV bias, and group query attention. It supports multiple natural languages and code. Fine-tuning is recommended, such as SFT, RLHF, etc. Pricing is free.
AI Model
55.5K
- 1
- 2
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M