%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Pixelprose
紹介 :
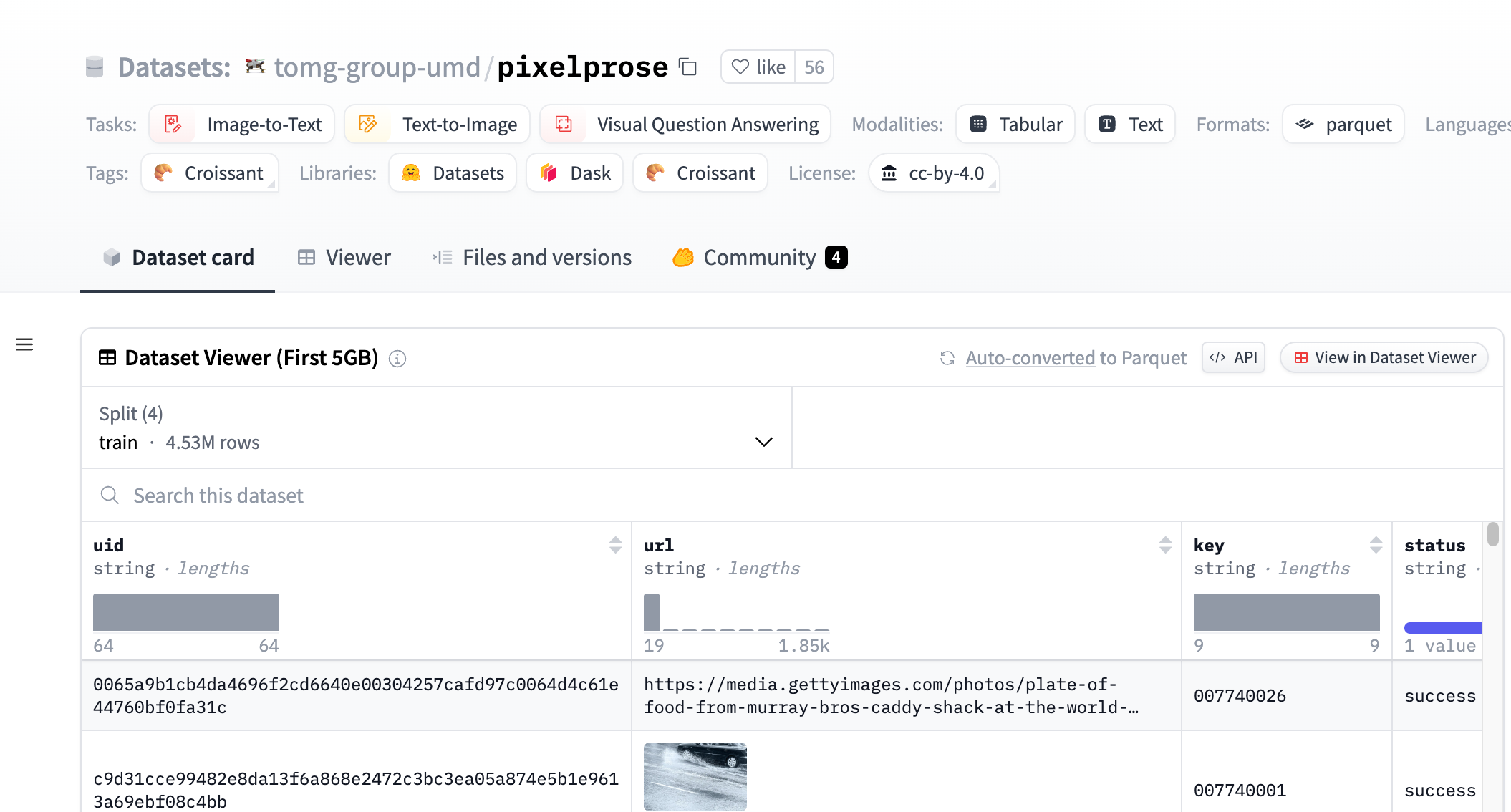
PixelProseは、tomg-group-umdによって作成された大規模データセットであり、最先端の視覚言語モデルGemini 1.0 Pro Visionを用いて、1600万件を超える詳細な画像記述を生成しています。このデータセットは、画像テキスト変換技術の開発と改良に非常に重要であり、画像記述生成、視覚的質問応答などのタスクに使用できます。
ターゲットユーザー :
機械学習および人工知能分野の研究者や開発者、特に画像認識、画像記述生成、視覚的質問応答システムに特化した専門家を対象としています。このデータセットの規模と多様性により、これらのシステムのトレーニングとテストに最適なリソースとなります。
使用シナリオ
研究者はPixelProseデータセットを使用して、ソーシャルメディア上の画像に自動的に記述を生成する画像記述生成モデルをトレーニングしました。
開発者はこのデータセットを利用して、画像の内容に関するユーザーの質問に答えることができる視覚的質問応答アプリケーションを開発しました。
教育機関は、PixelProseを教育リソースとして使用し、学生が画像認識と自然言語処理の基本原理を理解するのに役立てています。
製品特徴
1600万件を超える画像-テキストペアを提供します。
画像からテキストへの変換、テキストから画像への変換など、複数のタスクをサポートします。
表やテキストを含む、複数のモダリティを含みます。
データ形式はparquetで、機械学習モデルによる処理が容易です。
複雑な視覚言語モデルのトレーニングに適した、詳細な画像記述が含まれています。
データセットは、CommonPool、CC12M、RedCapsの3つの部分に分割されています。
データの整合性を確保するために、画像のEXIF情報とSHA256ハッシュ値を提供します。
使用チュートリアル
第一步:Hugging Faceウェブサイトにアクセスし、PixelProseデータセットを検索します。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
第二步:Git LFS、Huggingface API、または直接リンクによるダウンロードなど、適切なダウンロード方法を選択します。
第三步:parquetファイル内のURLを使用して、対応する画像をダウンロードします。
第四步:研究または開発のニーズに応じて、データセットを読み込み、前処理を行います。
第五步:データセットを使用して、視覚言語モデルのトレーニングまたはテストを行います。
第六步:モデルの性能を評価し、必要に応じてモデルパラメータを調整します。
第七步:トレーニング済みのモデルを実問題またはさらなる研究に適用します。










おすすめAI製品

Yolov8
YOLOv8は、YOLOシリーズ物体検出モデルの最新版であり、画像や動画内における複数の物体の正確かつ迅速な識別と位置特定、そしてそれらの移動のリアルタイム追跡が可能です。以前のバージョンと比較して、YOLOv8は検出速度と精度が大幅に向上しており、インスタンスセグメンテーションや姿勢推定など、様々な追加のコンピュータビジョンタスクにも対応しています。YOLOv8は様々なフォーマットで異なるハードウェアプラットフォームに展開でき、エンドツーエンドの物体検出ソリューションを提供します。
AI画像検出識別
229.1K
Lexy
LexyはAI技術に基づいた画像文字抽出ツールです。画像内の文字を自動認識し、抽出することで、ユーザーによる後処理や分析を容易にします。高い精度と高速な認識速度を誇り、あらゆる画像文字抽出シーンに適用可能です。画像から文字を抽出したい個人ユーザーから、大規模な画像文字処理を行う企業ユーザーまで、Lexyは皆様のニーズにお応えします。
AI画像検出識別
218.3K