%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Pixelprose
Overview :
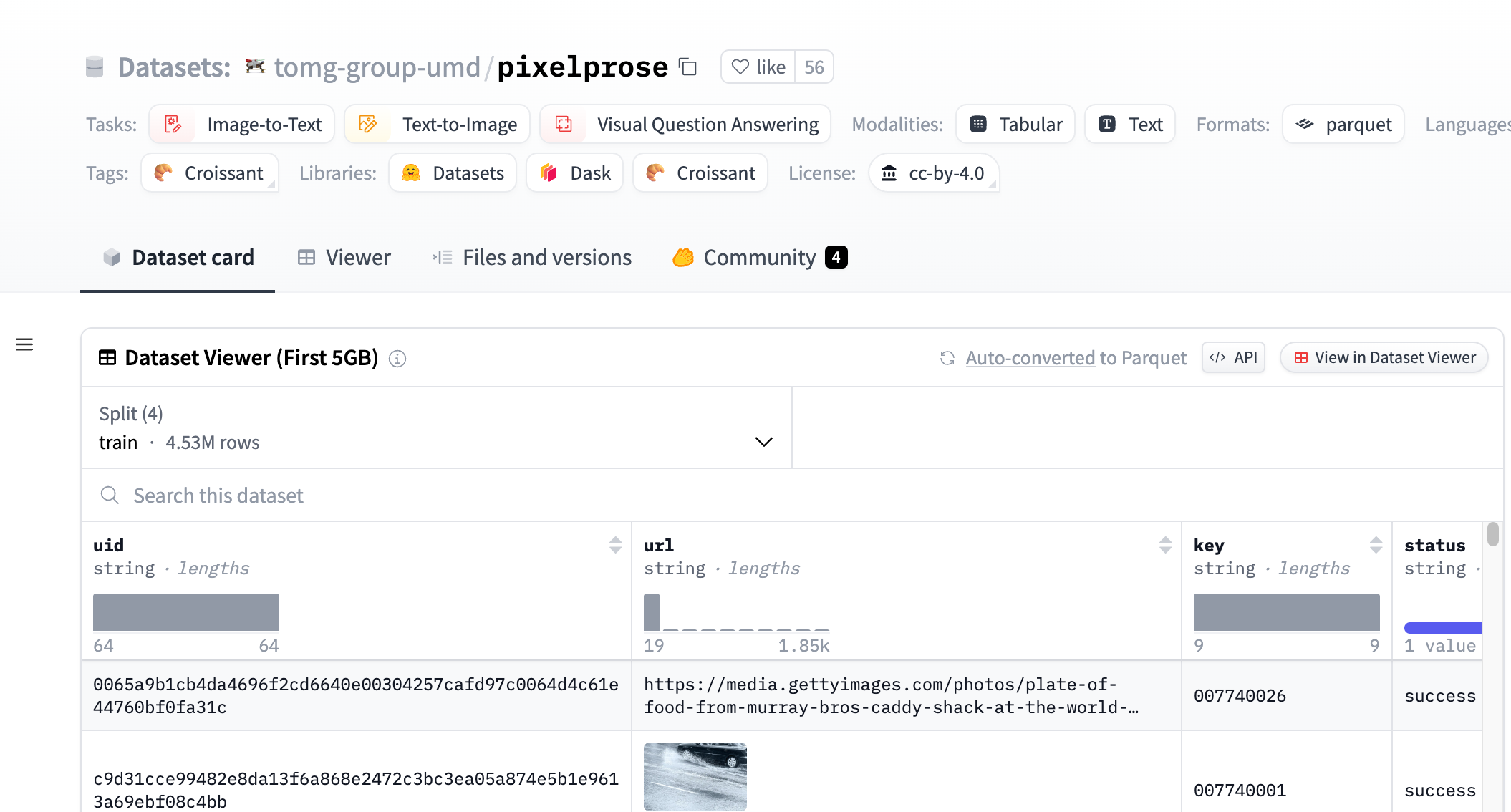
PixelProse, created by the tomg-group-umd, is a large-scale dataset generating over 16 million detailed image descriptions using the advanced vision-language model Gemini 1.0 Pro Vision. This dataset is crucial for developing and improving image-to-text conversion technologies and can be used for tasks like image captioning and visual question answering.
Target Users :
This dataset is aimed at researchers and developers in the field of machine learning and artificial intelligence, particularly those specializing in image recognition, image captioning, and visual question answering systems. The scale and diversity of this dataset make it an ideal resource for training and testing these systems.
Use Cases
Researchers use the PixelProse dataset to train an image captioning model to automatically generate descriptions for pictures on social media.
Developers utilize this dataset to develop a visual question answering application capable of answering user questions about image content.
Educational institutions use PixelProse as a teaching resource to help students understand the fundamentals of image recognition and natural language processing.
Features
Provides over 16M image-text pairs.
Supports multiple tasks, such as image-to-text and text-to-image.
Includes multiple modalities, including tables and text.
Data format is parquet, easily processed by machine learning models.
Contains detailed image descriptions suitable for training complex vision-language models.
Dataset is divided into three parts: CommonPool, CC12M, and RedCaps.
Provides EXIF information and SHA256 hash values for images, ensuring data integrity.
How to Use
Step 1: Visit the Hugging Face website and search for the PixelProse dataset.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
Step 2: Choose the appropriate download method, such as through Git LFS, Huggingface API, or directly downloading the parquet file.
Step 3: Use the URL in the parquet file to download the corresponding images.
Step 4: Load the dataset and preprocess it according to research or development needs.
Step 5: Train or test a vision-language model using the dataset.
Step 6: Evaluate model performance and adjust model parameters as needed.
Step 7: Apply the trained model to real-world problems or further research.











Featured AI Tools

Yolov8
YOLOv8 is the latest version of the YOLO (You Only Look Once) family of object detection models. It can accurately and rapidly identify and locate multiple objects in images or videos, and track their movements in real time. Compared to previous versions, YOLOv8 has significantly improved detection speed and accuracy, while also supporting a variety of additional computer vision tasks, such as instance segmentation and pose estimation. YOLOv8 can be deployed on various hardware platforms in different formats, providing a one-stop end-to-end object detection solution.
AI image detection and recognition
228.3K
Lexy
Lexy is an AI-powered image text extraction tool. It can automatically recognize text in images and extract it for user convenience in subsequent processing and analysis. Lexy boasts high accuracy and fast recognition speed, suitable for various image text extraction scenarios. Whether you are an individual user needing to extract text from images or an enterprise user requiring large-scale image text processing, Lexy can meet your needs.
AI image detection and recognition
221.6K