%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
高品質新製品
Deepseek V3/R1 推論システム
DeepSeek-V3/R1推論システムは、DeepSeekチームが開発した高性能推論アーキテクチャであり、大規模なスパースモデルの推論効率を最適化することを目的としています。ノード間エキスパート並列処理(EP)技術により、GPU行列計算の効率を大幅に向上させ、遅延を低減します。このシステムは、二重バッチオーバーラップ戦略と多段階負荷分散メカニズムを採用し、大規模分散環境で効率的に動作することを保証します。主な利点としては、高スループット、低遅延、最適化されたリソース利用率があり、高性能コンピューティングとAI推論のシナリオに適しています。
モデルトレーニングとデプロイ
46.4K
Deepseek Infraにおけるプロファイリングデータ
DeepSeek Profile Dataは、深層学習フレームワークの性能分析に特化したプロジェクトです。PyTorch Profilerを使用して訓練と推論フレームワークの性能データを収集し、研究者や開発者が計算と通信のオーバーラップ戦略および低レベルの実装の詳細をより深く理解するのに役立ちます。これらのデータは大規模な分散型訓練と推論タスクの最適化に不可欠であり、システムの効率と性能を大幅に向上させることができます。このプロジェクトは、DeepSeekチームによる深層学習インフラストラクチャ分野における重要な貢献であり、効率的な計算戦略の探求を促進することを目的としています。
モデルトレーニングとデプロイ
43.3K
高品質新製品
Dualpipe
DualPipeは、DeepSeek-AIチームが開発した革新的な双方向パイプライン並列アルゴリズムです。計算と通信のオーバーラップを最適化することで、パイプラインバブルを大幅に削減し、訓練効率を向上させます。大規模分散型訓練において優れたパフォーマンスを発揮し、特に高効率な並列化を必要とする深層学習タスクに適しています。DualPipeはPyTorchをベースに開発されており、統合と拡張が容易で、高性能計算を必要とする開発者や研究者にとって最適です。
モデルトレーニングとデプロイ
43.1K
高品質新製品
Flashmla
FlashMLAは、可変長シーケンスサービス向けに設計された、Hopper GPU向けに最適化された高効率なMLAデコードカーネルです。CUDA 12.3以降に対応し、PyTorch 2.0以降をサポートしています。FlashMLAの主な利点は、高効率なメモリアクセスと計算性能であり、H800 SXM5上で最大3000 GB/sのメモリ帯域幅と580 TFLOPSの計算性能を実現します。大規模並列計算と高効率なメモリ管理を必要とする深層学習タスク、特に自然言語処理やコンピュータビジョン分野において重要な役割を果たします。FlashMLAの開発はFlashAttention 2&3とCutlassプロジェクトから着想を得ており、研究者や開発者にとって高効率な計算ツールを提供することを目的としています。
モデルトレーニングとデプロイ
48.9K
高品質新製品
ワンショットlora
ワンショットLoRAは、動画からLoRAモデルを迅速に学習することに特化したオンラインプラットフォームです。高度な機械学習技術を活用し、動画コンテンツを効率的にLoRAモデルに変換することで、ユーザーに迅速かつ容易なモデル生成サービスを提供します。この製品の主な利点は、操作がシンプルで、ログイン不要、さらにプライバシーが保護されている点です。ユーザーの個人データのアップロードは不要であり、いかなるユーザー情報も保存または収集しません。ユーザーデータのプライバシーと安全性を確保しています。この製品は、デザイナーや開発者など、LoRAモデルを迅速に生成する必要があるユーザーを主な対象としており、必要なモデルリソースを迅速に取得し、作業効率を向上させるお手伝いをします。
モデルトレーニングとデプロイ
56.9K
Kolosal AI
Kolosal AIは、ローカルデバイスでの大規模言語モデル(LLM)のトレーニングと実行を目的としたツールです。モデルのトレーニング、最適化、デプロイメントのプロセスを簡素化することで、ユーザーはローカルデバイス上で効率的にAI技術を活用できます。様々なハードウェアプラットフォームに対応し、高速な推論速度と柔軟なカスタマイズ機能を提供するため、個人開発者から大企業まで幅広い用途に適しています。オープンソースであるため、ユーザーは自身のニーズに合わせて二次開発を行うことも可能です。
モデルトレーニングとデプロイ
52.2K
中国語精選

MNN
MNNは、アリババ淘系技術がオープンソースで提供するディープラーニング推論エンジンです。TensorFlow、Caffe、ONNXなど主要なモデル形式に対応し、CNN、RNN、GANなど一般的なネットワークと互換性があります。演算子性能を極限まで最適化し、CPU、GPU、NPUを全面的にサポートすることで、デバイスの計算能力を最大限に活用し、アリババの70以上の場面におけるAIアプリケーションに広く利用されています。MNNは、高性能、使いやすさ、汎用性で知られ、AI導入のハードルを下げ、エッジAIの発展を促進することを目的としています。
モデルトレーニングとデプロイ
66.8K

ASAP
ASAP(Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills)は、シミュレーションと現実世界の動的な不一致問題を解決し、ヒューマノイドロボットの敏捷な全身技能を実現するための革新的な二段階フレームワークです。この技術は、事前にトレーニングされたモーショントラッキング戦略と、現実世界のデータでトレーニングされた残差動作モデルを組み合わせることで、複雑な動的環境におけるロボットの適応性と協調性を大幅に向上させます。ASAPの主な利点には、効率的なデータ活用、パフォーマンスの顕著な向上、複雑な動作の正確な制御が含まれます。この技術は、特に高い柔軟性と適応性が求められるアプリケーションシナリオにおいて、将来のヒューマノイドロボット開発に新たな方向性を提供します。
モデルトレーニングとデプロイ
45.3K
Deepseek R1 Distill Qwen 32B
DeepSeek-R1-Distill-Qwen-32Bは、DeepSeekチームが開発した高性能言語モデルであり、Qwen-2.5シリーズを基に蒸留最適化されています。このモデルは複数のベンチマークテストで優れた性能を示しており、特に数学、コード、推論タスクにおいて顕著です。主な利点として、効率的な推論能力、強力な多言語サポート、そしてオープンソースである点が挙げられ、研究者や開発者による二次開発や応用が容易です。このモデルは、スマートカスタマーサービス、コンテンツ作成、コードアシストなど、高性能なテキスト生成が必要な場面に適しており、幅広い応用が期待できます。
モデルトレーニングとデプロイ
112.1K
中国語精選
Kimi K1.5
Kimi k1.5は、MoonshotAIによって開発されたマルチモーダル言語モデルです。強化学習とロングコンテキスト拡張技術により、複雑な推論タスクにおけるモデルのパフォーマンスが大幅に向上しました。AIMEやMATH-500などの数学的推論タスクにおいて、GPT-4oやClaude Sonnet 3.5を上回るなど、複数のベンチマークテストで業界トップレベルの成果を達成しています。主な利点としては、効率的なトレーニングフレームワーク、強力なマルチモーダル推論能力、ロングコンテキストのサポートなどが挙げられます。Kimi k1.5は、プログラミング支援、数学の問題解決、コード生成など、複雑な推論と論理分析を必要とするアプリケーションシナリオを主に対象としています。
モデルトレーニングとデプロイ
219.1K
Minirag
MiniRAGは、小型言語モデル用に設計された検索強化生成システムであり、RAGプロセスの簡素化と効率化を目指しています。意味を理解する異種グラフ索引メカニズムと軽量なトポロジ拡張検索手法により、従来のRAGフレームワークにおける小型モデルの性能制限の問題を解決します。このモデルは、モバイルデバイスやエッジコンピューティング環境など、リソースの限られた環境で顕著な利点を発揮します。また、MiniRAGはオープンソースであるため、開発者コミュニティによる容易な採用と改良が可能です。
モデルトレーニングとデプロイ
47.7K

Bakery
Bakeryは、オープンソースAIモデルの微調整と収益化に特化したオンラインプラットフォームです。AIスタートアップ企業、機械学習エンジニア、研究者の方々に、AIモデルの微調整と市場での収益化を容易にする便利なツールを提供します。シンプルで使いやすいインターフェースと強力な機能が主な特長で、ユーザーは迅速にデータセットを作成またはアップロードし、モデル設定を微調整して、市場で収益化できます。BakeryはオープンソースAI技術の発展と開発者へのビジネスチャンス拡大を目指しています。具体的な価格設定はページに明示されていませんが、AI分野のプロフェッショナルに効率的なツールを提供することを目指しています。
モデルトレーニングとデプロイ
56.3K
高品質新製品
NVIDIA Cosmos
NVIDIA Cosmosは、自動運転車やロボットなどの物理AIシステムの開発を加速させるための、高度な世界基礎モデルプラットフォームです。事前にトレーニングされた生成モデル、高度なトークナイザー、高速データ処理パイプラインを提供することで、開発者は物理AIアプリケーションの構築と最適化を容易に行えます。オープンなモデルライセンスにより開発コストを削減し、開発効率を向上させるため、あらゆる規模の企業や研究機関に適しています。
モデルトレーニングとデプロイ
54.4K
Brag AI
bRAG AIは、ユーザーが独自のAIモデルを作成およびトレーニングして、正確でリアルタイムな回答を得ることができる革新的なAIプラットフォームです。最大の利点は、ユーザー提供のデータに基づいてパーソナライズされたトレーニングが可能であり、回答の正確性と信頼性を確保できる点です。本製品は、カスタマイズされたAIソリューションを必要とする企業や個人に適しており、価格は未定ですが、様々なユーザーのニーズを満たせる柔軟な価格戦略を提供予定です。
モデルトレーニングとデプロイ
49.4K
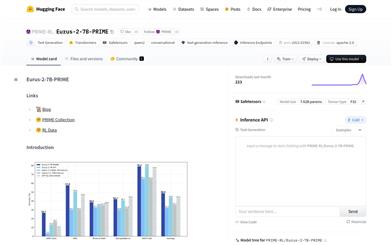
Eurus 2 7B PRIME
PRIME-RL/Eurus-2-7B-PRIMEは、PRIME手法を用いて訓練された70億パラメーターの言語モデルで、オンライン強化学習によって言語モデルの推論能力を向上させることを目的としています。本モデルはEurus-2-7B-SFTから訓練を開始し、Eurus-2-RL-Dataデータセットを用いて強化学習を行いました。PRIME手法は、暗黙的な報酬メカニズムを通じて、モデルが生成プロセスにおいて結果だけでなく推論プロセスにも重点を置くようにします。本モデルは複数の推論ベンチマークテストで優れた性能を示し、SFT版と比較して平均16.7%向上しました。主な利点としては、推論能力の効率的な向上、データとモデル資源の低消費、数学とプログラミングタスクにおける優れた性能が挙げられます。本モデルは、プログラミング問題解答や数学問題解決など、複雑な推論能力が求められる場面に適しています。
モデルトレーニングとデプロイ
48.0K
Eurusprm Stage2
EurusPRM-Stage2は、生成モデルの推論過程を最適化するために、暗黙的過程報酬を用いた高度な強化学習モデルです。このモデルは、因果言語モデルの対数尤度比を用いて過程報酬を計算することにより、追加の注釈コストをかけることなくモデルの推論能力を向上させます。主な利点としては、応答レベルのラベルのみを用いて暗黙的に過程報酬を学習できるため、生成モデルの精度と信頼性を向上させることができます。数学問題解答などのタスクで優れた性能を示し、複雑な推論と意思決定が必要な場面に適しています。
モデルトレーニングとデプロイ
43.9K
PRIME RL
PRIMEは、暗黙的過程報酬を用いて言語モデルの推論能力を強化するオープンソースのオンライン強化学習ソリューションです。この技術の主な利点は、明示的な過程ラベルに依存することなく、密度の高い報酬信号を効果的に提供できることであり、これによりモデルのトレーニングと推論能力の向上が加速されます。PRIMEは数学コンテストのベンチマークテストで優れた成果を収め、既存の大規模言語モデルを凌駕しています。複数の研究者によって開発され、GitHubで関連コードとデータセットが公開されています。PRIMEは、複雑な推論タスクを必要とするユーザーに強力なモデルサポートを提供することを目的としています。
モデルトレーニングとデプロイ
45.5K
Flagai
FlagAIは、北京智源人工智能研究院が提供する、高品質な一元化オープンソースプロジェクトです。世界中で広く利用されている様々な大規模言語モデルアルゴリズム技術と、複数の大規模言語モデルの並列処理およびトレーニング加速技術を統合しています。効率的なトレーニングと微調整をサポートし、大規模言語モデルの開発と応用のハードルを下げ、開発効率の向上を目指しています。FlagAIは、言語大規模モデルOPT、T5、ビジョン大規模モデルViT、Swin Transformer、マルチモーダル大規模モデルCLIPなど、複数の分野の代表的なモデルを網羅しています。「悟道2.0」「悟道3.0」大規模モデルプロジェクトの成果もFlagAIにオープンソース化されており、現在Linux Foundationに参加し、世界中の研究者による共同イノベーションと貢献を促進しています。
モデルトレーニングとデプロイ
48.3K
Astris AI
Astris AIは、ロッキード?マーティン社の子会社として設立され、高い保証要件を満たす人工知能ソリューションの採用を、米国国防産業基盤と商業分野で推進することを目的としています。ロッキード?マーティン社が保有する人工知能と機械学習における最先端技術と専門家チームを提供することにより、安全で、弾力性があり、拡張性の高いAIソリューションの開発と展開を支援します。Astris AIの設立は、21世紀の安全保障強化、国防産業基盤と国家安全保障の強化に対するロッキード?マーティン社のコミットメントを示すとともに、増大する脅威環境に対処するために商業技術を統合する同社のリーダーシップを明確に示しています。
モデルトレーニングとデプロイ
51.1K
Nexa
Nexa AIは、企業向けのデバイス搭載型スマートAIソリューションを提供します。Tiny Multimodal Modelsとシームレスなエッジ展開ソリューションを含み、プライバシー保護、コスト効率、信頼性の高いデバイス上AI構築を目指しています。インターネット接続がない環境でも信頼性の高い機能を提供できる点が特長で、遠隔地、油田?ガス田、インターネット接続が制限された職場、極端な状況など、さまざまな困難な環境に適しています。Nexa AIは、企業向けにカスタマイズされたデバイス上モデルとローカル展開ソリューションを提供し、オンプレミスでもあらゆるデバイス上でも、制御と速度を向上させます。
モデルトレーニングとデプロイ
45.0K
AMD ROCm 6.3
AMD ROCm? 6.3は、AMDのオープンソースプラットフォームにおける重要なマイルストーンであり、AMD Instinct GPUアクセラレーター上でのAI、機械学習(ML)、高性能コンピューティング(HPC)ワークロードのパフォーマンス向上のための高度なツールと最適化が導入されています。ROCm 6.3は、革新的なAIスタートアップからHPCを駆使する業界まで、幅広い顧客の開発者生産性を強化することを目的としています。
モデルトレーニングとデプロイ
45.8K
Mlperf Client
MLPerf Clientは、MLCommonsが共同開発した新しいベンチマークテストであり、ノートパソコン、デスクトップ、ワークステーションなど、パーソナルコンピュータ上での大規模言語モデル(LLM)およびその他のAIワークロードのパフォーマンスを評価することを目的としています。本ベンチマークテストは、現実世界のAIタスクをシミュレートすることにより、システムが生成AIワークロードをどのように処理するかを理解するための明確な指標を提供します。MLPerf Clientワーキンググループは、このベンチマークテストが、イノベーションと競争を促進し、パーソナルコンピュータがAI駆動の将来の課題に対応できるようにすることを期待しています。
モデルトレーニングとデプロイ
44.7K
Trillium TPU
Trillium TPUは、Google Cloudの第6世代Tensor Processing Unit(TPU)であり、AIワークロード向けに設計されており、強化された性能と費用対効果を提供します。Google Cloud AI Hypercomputerの主要コンポーネントとして、統合されたハードウェアシステム、オープンソースソフトウェア、最先端の機械学習フレームワーク、柔軟な消費モデルを通じて、大規模AIモデルのトレーニング、ファインチューニング、推論をサポートします。Trillium TPUは、性能、コスト効率、持続可能性の面で大幅な向上を実現し、AI分野における重要な進歩です。
モデルトレーニングとデプロイ
44.2K
Olmo 2 1124 7B SFT
OLMo-2-1124-7B-SFTは、アレン人工知能研究所(AI2)によって公開された英語テキスト生成モデルです。これはOLMo 2 7Bモデルの教師ありファインチューニング版であり、TüLu 3データセットに合わせて最適化されています。TüLu 3データセットは、チャット、数学問題解答、GSM8K、IFEvalなど、多様なタスクにおいて最先端の性能を提供することを目指しています。このモデルの主な利点としては、強力なテキスト生成能力、多様なタスク処理能力、そしてオープンソースのコードとトレーニングの詳細があり、研究や教育分野において強力なツールとなっています。
モデルトレーニングとデプロイ
46.4K
Prime
PrimeIntellect-ai/primeは、インターネット上でAIモデルを高効率かつグローバルに分散して訓練するためのフレームワークです。技術革新により、地域を跨いでのAIモデル訓練を実現し、計算資源の利用率向上、訓練コスト削減に貢献します。大規模な計算資源を必要とするAI研究やアプリケーション開発にとって非常に重要です。
モデルトレーニングとデプロイ
47.7K
Dolmino Mix 1124
DOLMino dataset mix for OLMo2 stage 2 annealing trainingは、OLMo2モデルの第2段階アニーリングトレーニング用に、様々な高品質データを混合したデータセットです。このデータセットは、ウェブページ、STEM論文、百科事典など、多様なデータタイプを含んでおり、テキスト生成タスクにおけるモデルのパフォーマンス向上を目指しています。よりスマートで正確な自然言語処理モデルの開発に役立つ、豊富なトレーニングリソースを提供するという点で重要です。
モデルトレーニングとデプロイ
45.0K
Learning To Fly
Learning to Fly (L2F)は、深層強化学習を用いてエンドツーエンドの制御戦略を学習し、消費者向けノートパソコンで迅速にトレーニングを完了することを目的としたオープンソースプロジェクトです。このプロジェクトの主な利点は、トレーニング速度が速く数秒で完了し、学習した戦略の汎化能力が高く、実際の4旋翼無人機に直接展開できることです。L2FプロジェクトはRLtools深層強化学習ライブラリに依存し、詳細なインストールと展開ガイドを提供することで、研究者や開発者が迅速に開始して実験できるようにします。
モデルトレーニングとデプロイ
42.5K
Foundry AI
Foundry AIは、AIエージェントの構築、評価、改善に特化したプラットフォームであり、信頼性の高い結果を提供することを目指しています。リアルタイムのフィードバックによる継続的な改善、人的介入のカスタマイズ制御、パフォーマンス最適化のためのA/Bテストが可能です。業界の専門家によって構築されたFoundry AIは、従来の自動化と比較して、よりインテリジェントなAI管理システムを提供し、高品質なAI結果、迅速かつ効果的な改善、そしてインテリジェントな人間とAIの協働を実現します。
モデルトレーニングとデプロイ
46.9K

フィジカルインテリジェンス
Physical Intelligence (π)は、エンジニア、科学者、ロボティクス研究者、企業家からなるチームです。最新のロボットや将来の物理駆動デバイスを駆動するための基礎モデルと学習アルゴリズムの開発に尽力しています。本チームは汎用人工知能技術を物理世界に応用し、ロボット工学の発展とイノベーションを推進することを目指しています。
モデルトレーニングとデプロイ
51.1K
D FINE
D-FINEは、DETRにおける境界ボックス回帰タスクを細粒度分布細化(FDR)として再定義し、グローバル最適位置自己蒸留(GO-LSD)を導入することで、追加の推論やトレーニングコストなしに優れた性能を実現する、強力なリアルタイム物体検出モデルです。中国科学院の研究者によって開発され、物体検出の精度と効率の向上を目指しています。
モデルトレーニングとデプロイ
45.5K
- 1
- 2
- 3
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M