%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

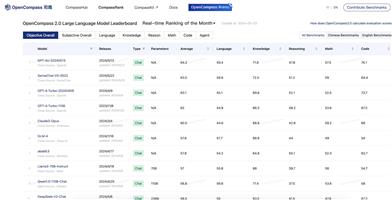
SWE Bench Verified
简介 :
SWE-bench Verified是OpenAI发布的一个经过人工验证的SWE-bench子集,旨在更可靠地评估AI模型解决现实世界软件问题的能力。它通过提供代码库和问题描述,挑战AI生成解决所描述问题的补丁。这个工具的开发是为了提高模型自主完成软件工程任务的能力评估的准确性,是OpenAI准备框架中中等风险级别的关键组成部分。
需求人群 :
SWE-bench Verified主要面向AI研究者和软件开发者,他们需要评估和理解大型语言模型在软件工程任务中的表现和能力。通过这个工具,用户可以更准确地衡量AI模型的编程能力和问题解决技巧,进而优化和提升模型的性能。
使用场景
研究者使用SWE-bench Verified来测试和比较不同AI模型在解决编程问题上的表现。
教育机构利用该工具作为教学辅助,帮助学生理解AI在编程领域的应用。
软件开发团队使用SWE-bench Verified来评估和选择最适合其项目的AI编程助手。
产品特色
从GitHub问题中提取并创建测试样本
提供FAIL_TO_PASS和PASS_TO_PASS测试以验证代码的正确性
人工注释筛选,确保测试样本的质量和问题描述的明确性
使用容器化的Docker环境简化评估过程,提高可靠性
与SWE-bench作者合作开发新的评估工具
GPT-4o在SWE-bench Verified上的表现显著提高,解决了33.2%的样本
使用教程
步骤一:下载并安装SWE-bench Verified工具。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
步骤二:准备或选择一个GitHub代码库以及相关的问题描述。
步骤三:使用SWE-bench Verified提供的环境和测试框架对AI模型进行评估。
步骤四:运行FAIL_TO_PASS和PASS_TO_PASS测试,检查AI模型生成的补丁是否解决了问题并且没有破坏现有功能。
步骤五:根据测试结果分析AI模型的性能,并据此进行模型优化。
步骤六:将评估结果和反馈整合到模型训练和迭代过程中,以提高模型的软件工程能力。