%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

SWE Bench Verified
紹介 :
SWE-bench Verifiedは、OpenAIが公開した、人間による検証済みのSWE-benchサブセットです。現実世界のソフトウェア問題に対するAIモデルの解決能力をより信頼性高く評価することを目的としています。コードリポジトリと問題の説明を提供することで、AIが記述された問題に対する修正プログラムを生成するよう促します。このツールは、モデルがソフトウェアエンジニアリングタスクを自律的に実行する能力の評価精度を高めるために開発され、OpenAI準備フレームワークの中リスクレベルの重要な構成要素です。
ターゲットユーザー :
SWE-bench Verifiedは主に、AI研究者やソフトウェア開発者、大規模言語モデルのソフトウェアエンジニアリングタスクにおける性能と能力を評価?理解する必要がある方を対象としています。このツールを使用することで、AIモデルのプログラミング能力と問題解決能力をより正確に測定し、モデルの性能を最適化?向上させることができます。
使用シナリオ
研究者はSWE-bench Verifiedを使用して、プログラミング問題解決における様々なAIモデルの性能をテスト?比較します。
教育機関は、このツールを教育補助として活用し、学生がプログラミング分野におけるAIの応用を理解するのに役立てています。
ソフトウェア開発チームはSWE-bench Verifiedを使用して、プロジェクトに最適なAIプログラミングアシスタントを評価?選択します。
製品特徴
GitHubのissueからテストサンプルを抽出して作成する
コードの正確性を検証するためのFAIL_TO_PASSおよびPASS_TO_PASSテストを提供する
手動による注釈付けによる選別を行い、テストサンプルの質と問題記述の明確性を確保する
コンテナ化されたDocker環境を使用して評価プロセスを簡素化し、信頼性を向上させる
SWE-benchの開発者と協力して新しい評価ツールを開発する
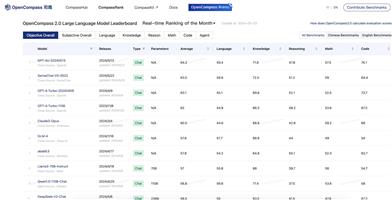
GPT-4oはSWE-bench Verifiedにおいて顕著な性能向上を示し、33.2%のサンプルを解決した
使用チュートリアル
ステップ1:SWE-bench Verifiedツールをダウンロードしてインストールします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
ステップ2:GitHubコードリポジトリと関連する問題の説明を用意するか、選択します。
ステップ3:SWE-bench Verifiedが提供する環境とテストフレームワークを使用して、AIモデルを評価します。
ステップ4:FAIL_TO_PASSおよびPASS_TO_PASSテストを実行し、AIモデルが生成した修正プログラムが問題を解決し、既存機能を壊していないことを確認します。
ステップ5:テスト結果に基づいてAIモデルの性能を分析し、それに基づいてモデルを最適化します。
ステップ6:評価結果とフィードバックをモデルのトレーニングと反復プロセスに統合して、モデルのソフトウェアエンジニアリング能力を向上させます。




おすすめAI製品
Google AI Studio
Google AI Studioは、Google Cloud上でAIアプリケーションを構築およびデプロイするための、Vertex AIを基盤としたプラットフォームです。ノーコードインターフェースを提供することで、開発者、データサイエンティスト、ビジネスアナリストがAIモデルを迅速に構築、デプロイ、管理することを可能にします。
AI開発プラットフォーム
969.3K
Vertex AI
Vertex AIは、機械学習モデルの構築とデプロイに必要な統合プラットフォームとツールを提供します。強力な機能を備え、カスタムモデルのトレーニングとデプロイを高速化し、事前構築済みのAI APIとアプリケーションを提供します。主な機能には、統合ワークスペース、モデルのデプロイと管理、MLOpsサポートなどがあります。データサイエンティストとMLエンジニアの生産性を大幅に向上させることができます。
AI開発プラットフォーム
282.1K