%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
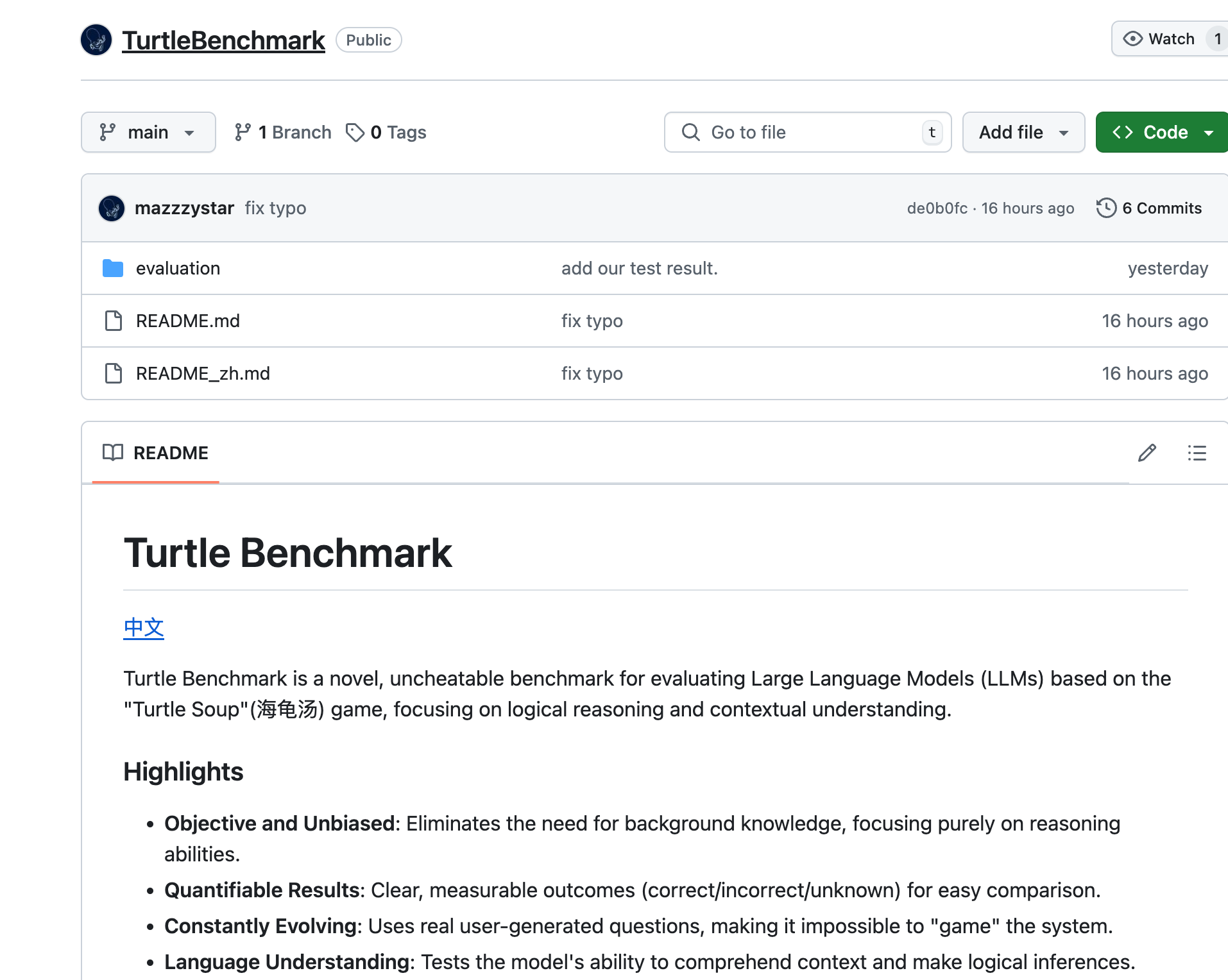
Turtle Benchmark
简介 :
Turtle Benchmark是一款基于'Turtle Soup'游戏的新型、无法作弊的基准测试,专注于评估大型语言模型(LLMs)的逻辑推理和上下文理解能力。它通过消除对背景知识的需求,提供了客观和无偏见的测试结果,具有可量化的结果,并且通过使用真实用户生成的问题,使得模型无法被'游戏化'。
需求人群 :
Turtle Benchmark适用于需要评估和比较大型语言模型性能的研究者和开发者。它特别适合那些专注于模型的逻辑推理和上下文理解能力的专业人士,帮助他们更准确地了解模型在中文语境下的表现。
使用场景
研究者使用Turtle Benchmark评估不同大型语言模型在特定逻辑推理任务上的表现。
开发者利用Turtle Benchmark测试他们的语言模型是否能够准确理解并回答用户的问题。
教育机构使用Turtle Benchmark作为教学工具,帮助学生理解大型语言模型的工作原理和性能评估方法。
产品特色
目标明确、无偏见:专注于推理能力,无需背景知识。
结果可量化:提供清晰、可测量的结果(正确/错误/未知),便于比较。
持续进化:使用真实用户生成的问题,防止系统被操纵。
语言理解:测试模型理解上下文和进行逻辑推断的能力。
使用简单:通过简单的命令行操作即可进行评估。
数据丰富:包含32个独特的'Turtle Soup'故事和1537个人工标注的标签。
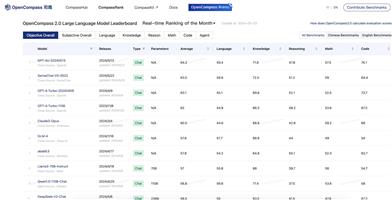
结果解读:通过散点图比较不同模型在2-shot学习场景下的整体准确率和故事平均准确率。
使用教程
1. 进入Turtle Benchmark项目目录。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 将.env.example文件重命名为.env并添加API密钥。
3. 执行`python evaluate.py`命令以进行2-shot学习评估。
4. 如需进行零样本(Zero-shot)评估,执行`python evaluate.py --shot 0`命令。
5. 查看评估结果,包括整体准确率和故事平均准确率。
6. 通过散点图分析不同模型的性能差异。