%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

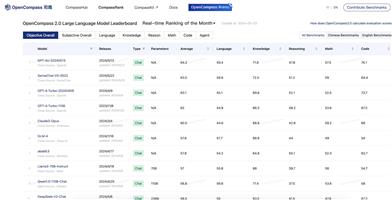
SWE Bench Verified
簡介 :
SWE-bench Verified是OpenAI發佈的一個經過人工驗證的SWE-bench子集,旨在更可靠地評估AI模型解決現實世界軟件問題的能力。它通過提供代碼庫和問題描述,挑戰AI生成解決所描述問題的補丁。這個工具的開發是為了提高模型自主完成軟件工程任務的能力評估的準確性,是OpenAI準備框架中中等風險級別的關鍵組成部分。
需求人群 :
SWE-bench Verified主要面向AI研究者和軟件開發者,他們需要評估和理解大型語言模型在軟件工程任務中的表現和能力。通過這個工具,用戶可以更準確地衡量AI模型的編程能力和問題解決技巧,進而優化和提升模型的性能。
使用場景
研究者使用SWE-bench Verified來測試和比較不同AI模型在解決編程問題上的表現。
教育機構利用該工具作為教學輔助,幫助學生理解AI在編程領域的應用。
軟件開發團隊使用SWE-bench Verified來評估和選擇最適合其項目的AI編程助手。
產品特色
從GitHub問題中提取並創建測試樣本
提供FAIL_TO_PASS和PASS_TO_PASS測試以驗證代碼的正確性
人工註釋篩選,確保測試樣本的質量和問題描述的明確性
使用容器化的Docker環境簡化評估過程,提高可靠性
與SWE-bench作者合作開發新的評估工具
GPT-4o在SWE-bench Verified上的表現顯著提高,解決了33.2%的樣本
使用教程
步驟一:下載並安裝SWE-bench Verified工具。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
步驟二:準備或選擇一個GitHub代碼庫以及相關的問題描述。
步驟三:使用SWE-bench Verified提供的環境和測試框架對AI模型進行評估。
步驟四:運行FAIL_TO_PASS和PASS_TO_PASS測試,檢查AI模型生成的補丁是否解決了問題並且沒有破壞現有功能。
步驟五:根據測試結果分析AI模型的性能,並據此進行模型優化。
步驟六:將評估結果和反饋整合到模型訓練和迭代過程中,以提高模型的軟件工程能力。