%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
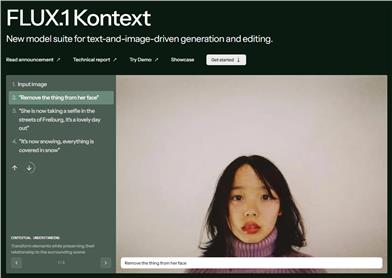
FLUX.1 Kontext
Black Forest Labs がリリースした最新の画像生成?編集モデルである FLUX.1 Kontext は、テキストや画像の入力を組み合わせて、フレキシブルな画像変更を可能にします。高速な推論処理と高品質な画像生成により、デザインやクリエイティブなワークフローの効率を大幅に向上させます。その主な強みは、コンテキストに基づく画像生成?編集をサポートすることで、コンセプト設計やスケッチの作成など多様なシナリオで活躍します。また、迅速編集版や高性能選択版などの複数のバージョンが提供され、クリエイティブ分野の専門家や開発者に適しています。
画像編集
37.3K
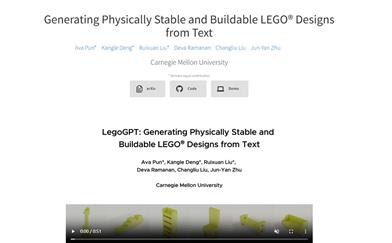
Legogpt
LegoGPT は、テキストによるプロンプトで物理的に安定したレゴモデルを生成する最初の方法です。この技術は、大規模なレゴデザインデータセットを活用し、自己回帰型言語モデルを使用して次のレゴブロックを生成します。また、物理的な制約条件を適用することでモデルの安定性を確保しています。その主な特長には、多様で美しいデザインを生成できる機能や、人間とロボットによる組み立てをサポートする機能、自動生成とテクスチャーや色付け機能などがあります。
デザイン
38.1K

Liquid
Liquidは、画像を離散コードに分解し、テキストトークンと特徴空間を共有することで、視覚理解とテキスト生成のシームレスな統合を促進する自己回帰生成モデルです。このモデルの主な利点は、外部で事前にトレーニングされた視覚埋め込みを必要とせず、リソースへの依存を削減し、スケール則を通じて理解と生成タスク間の相互促進効果を発見したことです。
衣服
37.8K

UNO
UNOは、拡散変換器に基づいたマルチイメージ条件付き生成モデルです。漸進的なクロスモーダルアライメントと汎用回転位置埋め込みを導入することで、高一貫性の画像生成を実現します。主な利点として、単一または複数の主題の生成に対する制御性の向上が挙げられ、様々なクリエイティブな画像生成タスクに適しています。
チャットボット
38.4K

Easycontrol
EasyControlは、Diffusion Transformer(拡散変換器)に効率的で柔軟な制御を提供するフレームワークであり、現在のDiTエコシステムにおける効率のボトルネックやモデルの適合性の不足といった問題に対処することを目的としています。主な利点としては、様々な条件の組み合わせに対応、生成の柔軟性と推論効率の向上があります。本製品は最新の研究成果に基づいて開発されており、画像生成、スタイル変換などの分野で使用できます。
AIモデル
38.1K
IMM
Inductive Moment Matching (IMM)は、高品質な画像生成を目的とした、最先端の生成モデル技術です。この技術は革新的な帰納的モーメントマッチング手法を用いることで、生成画像の品質と多様性を大幅に向上させます。主な利点としては、効率性、柔軟性、そして複雑なデータ分布に対する強力なモデリング能力が挙げられます。IMMはLuma AIとスタンフォード大学の研究チームによって開発され、生成モデル分野の発展を促進し、画像生成、データ拡張、創造的なデザインなどのアプリケーションに強力な技術サポートを提供することを目的としています。このプロジェクトはコードと事前学習済みモデルをオープンソース化しており、研究者や開発者が迅速に使い始めることができます。
チャットボット
50.0K
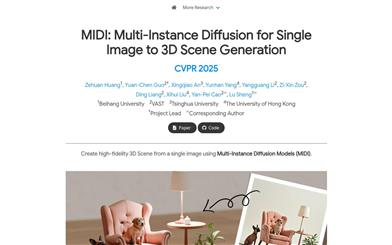
MIDI
MIDIは、多インスタンス拡散モデルを利用した革新的な画像から3Dシーン生成技術です。正確な空間関係を持つ複数の3Dインスタンスを、単一画像から直接生成できます。この技術の中核は多インスタンスアテンションメカニズムであり、複雑な複数ステップ処理を必要とせずに、物体間の相互作用と空間的一貫性を効果的に捉えることができます。MIDIは画像からシーン生成分野で優れた性能を示し、合成データ、現実世界のシーンデータ、そしてテキストから画像への拡散モデルによって生成されたスタイル化されたシーン画像に適しています。主な利点として、効率性、高忠実度、そして強力な汎化能力が挙げられます。
3Dモデリング
49.4K

SRM
SRMは、連続変数の集合の推論タスクを処理するために使用される、ノイズ除去生成モデルに基づく空間推論フレームワークです。各未観測変数に独立したノイズレベルを割り当てることで、これらの変数の連続表現を段階的に推論します。この技術は、複雑な分布を処理する際に優れた性能を示し、生成プロセスにおける幻覚現象を効果的に削減します。SRMは、ノイズ除去ネットワークが生成順序を予測できることを初めて実証し、特定の推論タスクの精度を大幅に向上させました。このモデルはドイツのマックス?プランク情報学研究所によって開発され、空間推論と生成モデルの研究を推進することを目的としています。
モデルトレーニングとデプロイメント
42.2K
Microsoft Muse
Museは、マイクロソフトリサーチチームとXbox Games Studiosが共同開発した生成AIモデルであり、ゲームのアイデア構想を支援することを目的としています。大規模な人間のゲームデータに基づいてトレーニングされており、一貫性のあるゲームビジュアルと操作シーケンスを生成できます。この技術は、ゲームデザインにおけるAIの可能性を示しており、将来のゲーム開発に新たな創作方法と体験を提供します。
ゲーム開発
48.0K
Bioemu
BioEmuは、Microsoftが開発した、タンパク質の平衡系アンサンブルをシミュレートするための深層学習モデルです。生成型深層学習手法を用いることで、タンパク質構造サンプルを効率的に生成し、研究者がタンパク質の動的挙動と構造多様性をより深く理解するのに役立ちます。このモデルの主な利点は、拡張性と効率性が高く、複雑な生体分子系を処理できる点です。生化学、構造生物学、創薬などの分野の研究に適用でき、科学者にとってタンパク質の動的特性を探求するための強力なツールとなります。
研究機器
45.0K
Splineによるspell
Spellは、Splineが開発したAIモデルであり、一枚の画像から完全な3Dシーンを生成できます。拡散モデル技術に基づき、実データと合成データの両方を使用してトレーニングされています。そのため、数分以内に多視点で整合性のある3Dワールドを生成できます。この技術の主な利点は、高品質の3Dシーンを迅速に生成し、ガウシアンレンダリングやニューラルラジオシティなどの様々なレンダリング技術に対応できる点です。Spellの登場は、3Dデザイン分野に革命的な変化をもたらし、クリエイターはより効率的に3Dシーンの生成と探索を行うことができるようになりました。現在、Spellは開発段階にあり、チームは品質と整合性を向上させるため、頻繁なモデル更新を予定しています。
3Dモデリング
46.4K
Eurusprm Stage2
EurusPRM-Stage2は、生成モデルの推論過程を最適化するために、暗黙的過程報酬を用いた高度な強化学習モデルです。このモデルは、因果言語モデルの対数尤度比を用いて過程報酬を計算することにより、追加の注釈コストをかけることなくモデルの推論能力を向上させます。主な利点としては、応答レベルのラベルのみを用いて暗黙的に過程報酬を学習できるため、生成モデルの精度と信頼性を向上させることができます。数学問題解答などのタスクで優れた性能を示し、複雑な推論と意思決定が必要な場面に適しています。
モデルトレーニングとデプロイ
43.9K
Eurusprm Stage1
EurusPRM-Stage1はPRIME-RLプロジェクトの一部であり、暗黙的過程報酬によって生成モデルの推論能力を強化することを目指しています。このモデルは、暗黙的過程報酬メカニズムを利用することで、追加のプロセスラベルの注釈なしに、推論過程で過程報酬を得ることができます。主な利点は、複雑なタスクにおける生成モデルのパフォーマンスを効果的に向上させながら、注釈コストを削減できることです。数学問題解答や自然言語生成など、複雑な推論と生成能力を必要とするシナリオに適しています。
AIモデル
42.5K
Flexrag
FlexRAGは、検索拡張型生成(RAG)タスクのための柔軟で高性能なフレームワークです。マルチモーダルデータ、シームレスなコンフィグレーション管理、およびすぐに使用できるパフォーマンスをサポートしており、研究やプロトタイプ開発に最適です。Pythonで記述されており、軽量で高性能なため、RAGワークフローの速度を大幅に向上させ、遅延を削減できます。主な利点としては、様々なデータタイプへの対応、統一的なコンフィグレーション管理、容易な統合と拡張などが挙げられます。
開発とツール
46.1K
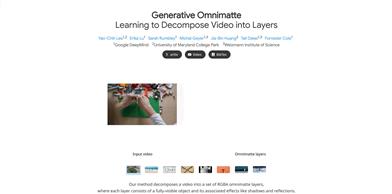
Generative Omnimatte
Generative Omnimatteは、動画を複数のRGBAレイヤーに分解する高度な動画処理技術です。各レイヤーには、可視オブジェクトとその効果(影や反射など)が含まれます。この技術は、動画編集や特殊効果制作において重要な役割を果たし、制作の柔軟性と効率性を向上させます。
映像編集
37.8K
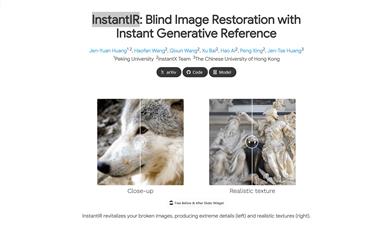
Instantir
InstantIRは、拡散モデルに基づいた盲画像復元手法です。テスト時に未知の劣化問題に対処し、モデルの汎化能力を向上させます。この技術は、推論過程で参照画像を生成することで生成条件を動的に調整し、堅牢な生成条件を提供します。InstantIRの主な利点には、極端に劣化している画像の詳細の復元、リアルなテクスチャの提供、そしてテキストによる記述で参照画像の調整を行い、創造的な画像復元を実現できることが挙げられます。この技術は、北京大学、InstantXチーム、香港中文大学の研究者によって共同開発され、Hugging Faceとfal.aiの支援を受けています。
画像編集
63.8K
Longrag
LongRAGは、大規模言語モデル(LLM)に基づく、双方向で堅牢な検索強化型生成システムパラダイムです。複雑な長文知識の理解と検索能力の向上を目指しています。特に長文質問応答(LCQA)に適しており、グローバルな情報と事実の詳細を処理できます。製品の背景情報によると、LongRAGは検索と生成技術を組み合わせることで、特に複数ステップの推論が必要なシナリオにおいて、長文質問応答タスクのパフォーマンスを向上させています。このモデルはオープンソースであり、無料で使用でき、主に研究者と開発者を対象としています。
研究機器
48.6K
Stable Diffusion 3.5 Medium
Stable Diffusion 3.5 Mediumは、Stability AIによって開発されたテキストから画像を生成するモデルです。画像品質、レイアウト、複雑なプロンプトの理解、そしてリソース効率が向上しています。このモデルは、3つの固定された事前学習済みテキストエンコーダを使用し、QK正規化によって訓練の安定性を高め、最初の12の変換層にデュアルアテンションブロックを導入しています。高解像度画像生成、一貫性、そして様々なテキストから画像へのタスクへの適応性において優れた性能を発揮します。
画像生成
59.3K

Scm
OpenAIが提案する連続時間整合性モデル(sCM)は、高品質なサンプル生成にわずか2回のサンプリングステップしか必要としない生成モデルです。主要な拡散モデルと比較して、著しい速度優位性を持ちます。sCMは理論式を簡略化することで、大規模データセットの訓練を安定化および拡張し、サンプル品質を維持しながらサンプリング時間を大幅に削減します。これにより、リアルタイムアプリケーションの可能性が開けます。
モデルトレーニングとデプロイ
45.0K
Stable Diffusion 3.5 Large Turbo
Stable Diffusion 3.5 Large Turboは、テキストから画像を生成するマルチモーダル拡散変換器(MMDiT)モデルです。敵対的拡散蒸留(ADD)技術を採用することで、画像品質、レイアウト、複雑なプロンプトの理解、リソース効率が向上し、特に推論ステップの削減に重点が置かれています。このモデルは画像生成において優れた性能を発揮し、複雑なテキストプロンプトを理解して生成できます。様々な画像生成シーンに適しています。Hugging Faceプラットフォームで公開されており、Stability Community Licenseに従い、研究、非商業利用、および年間収益が100万ドル未満の組織または個人は無料で使用できます。
画像生成
69.0K
Lfms
Liquid Foundation Models (LFMs)は、様々な規模において最先端の性能を達成しながら、より小さなメモリ使用量と高い推論効率を維持する、新型の生成AIモデルシリーズです。LFMsは、動的システム理論、信号処理、数値線形代数の計算ユニットを活用し、ビデオ、オーディオ、テキスト、時系列データ、信号など、あらゆる種類のシーケンスデータを処理できます。これらのモデルは汎用的なAIモデルであり、大規模なシーケンス多様なデータの処理、高度な推論の実行、信頼性の高い意思決定を目指しています。
モデルトレーニングとデプロイ
48.9K
Stability AI
Stability AIは、テキストから画像、動画、音声、3D、言語モデルなど、様々なAIモデルを提供する生成AI技術に特化した企業です。これらのモデルは複雑な指示にも対応し、リアルな画像や動画、高品質の音楽やサウンドエフェクトを生成します。自ホスティングライセンスやプラットフォームAPIなど、柔軟なライセンスオプションを提供し、様々なユーザーのニーズに対応しています。Stability AIは、オープンモデルを通じて世界中の人々に高品質なAIサービスを提供することに尽力しています。
画像生成
75.6K
Fluxmusic
FluxMusicは、PyTorchを用いて実装されたテキストから音楽を生成するモデルです。拡散的修正流変換器を用いて、シンプルながらも効果的なテキストから音楽への生成手法を探求しています。このモデルは、テキストプロンプトに基づいて音楽片段を生成することができ、高い革新性と技術的複雑さを併せ持っています。音楽生成分野における最先端技術の代表であり、音楽創作に新たな可能性をもたらします。
AI音楽生成
55.2K
Viper
ViPerは、ユーザーの視覚的嗜好に基づいて、個人の好みに合った画像を生成できるパーソナライズされた生成モデルです。本モデルはStable Diffusion XL技術を用いており、画像品質を維持しながらパーソナライズされた生成を実現します。ViPerの主な利点は、ユーザーにパーソナライズされた画像生成サービスを提供し、個々のニーズを満たすことができる点です。
AI画像生成
55.8K

Maskvat
MaskVATは、動画の視覚的特徴を利用してシーンに合ったリアルな音声を生成する動画から音声(V2A)生成モデルです。特に、音声の開始点と視覚的な動作の同期性に重点を置いており、不自然な同期の問題を回避します。MaskVATは、フルバンドの高品質汎用オーディオコーデックとシーケンスツーシーケンスのマスキング生成モデルを組み合わせることで、高音質、意味の一致、時間同期性を確保しながら、コーデックを使用しない音声生成モデルと同等の競争力を実現しています。
AI画像生成
47.5K
高品質新製品
SV4D
Stable Video 4D (SV4D) は、Stable Video Diffusion (SVD) と Stable Video 3D (SV3D) をベースとした生成モデルです。単一視点の動画を入力として受け取り、そのオブジェクトの複数の新しい視点の動画(4D画像マトリックス)を生成します。このモデルは、5つの同じサイズの参照フレームを与えられた場合、576x576ピクセルの解像度で40フレーム(5つの動画フレーム x 8つのカメラ視点)を生成するように学習されています。SV3Dを使用して軌道動画を生成し、その軌道動画をSV4Dの参照ビューとして使用し、入力動画を参照フレームとして使用して4Dサンプリングを行います。また、生成された最初のフレームをアンカーとして使用し、残りのフレームを密集サンプリング(補間)することで、より長い新しい視点の動画を生成します。
AI動画生成
60.7K
Auraflow
AuraFlow v0.1は、完全にオープンソースの流に基づくテキストから画像生成モデルで、GenEvalにおいて最先端の結果を達成しました。現在ベータ版であり、継続的に改良されています。コミュニティからのフィードバックは非常に重要です。このプロジェクトを実現してくださった@cloneofsimo氏と@isidentical氏、そしてこのプロジェクトの基礎となる研究を行ってくださった研究者の皆様に感謝いたします。
AI画像生成
91.1K
Gaussiancube
GaussianCubeは、構造化され明示的な表現方法を用いることで、3D生成モデリングを飛躍的に進歩させる革新的な3D放射表現手法です。この技術は、新規な密度制約付きガウス近似アルゴリズムと最適輸送法を用いて、ガウス関数を事前に定義されたボクセルグリッドに再配置することで、高精度な近似を実現します。従来の陰的特徴復号器や空間的に非構造化された放射表現と比較して、GaussianCubeはより少ないパラメータ数でより高品質な結果を得ることができ、3D生成モデリングを容易にします。
AI 3Dツール
54.9K
海外精選

PROTEUS
PROTEUSは、Apparate Labsが提供する次世代基盤モデルであり、リアルタイムで表情豊かな人間モデルを生成します。最先端のTransformerアーキテクチャを採用した潜在拡散モデルを用いており、革新的な潜在空間設計によりリアルタイム処理を実現。更なるアーキテクチャとアルゴリズムの改善により、毎秒100フレーム以上のビデオストリームを実現します。PROTEUSは、音声制御による視覚表現を提供し、人工会話エンティティに直感的なインターフェースを提供することを目指しており、様々な大規模言語モデルとの互換性があり、様々な用途に合わせてカスタマイズ可能です。
AI顔色生成
52.2K
高品質新製品
クックブック
クックブックは、Cohereが提供するオンラインドキュメントプラットフォームです。開発者やユーザーがCohereの生成AIプラットフォームを活用して様々なアプリケーションを構築する方法を学ぶことを目的としています。代理の構築、オープンソースソフトウェアの統合、意味検索、クラウドサービス、検索拡張生成(RAG)、要約生成など、様々なユースケースのガイドが含まれています。これらのガイドはベストプラクティスを提供し、ユーザーがCohereのモデルを最大限に活用できるよう支援します。すべてのコンテンツは設定済みで、ユーザーはすぐにテストを開始できます。
AI開発助手
49.1K
- 1
- 2
- 3
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M