%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Dream 7B
Dream 7Bは、香港大学NLPグループとファーウェイ?ノアの方舟研究所が共同で発表した最新の拡散型大規模言語モデルです。テキスト生成分野において優れた性能を示しており、特に複雑な推論、長期計画、文脈の一貫性などに優れています。本モデルは高度なトレーニング方法を採用しており、強力な計画能力と柔軟な推論能力を備え、様々なAIアプリケーションにより強力なサポートを提供します。
AIモデル
38.4K

Accvideo
AccVideoは、新規開発の高効率蒸留手法であり、合成データセットを用いてビデオ拡散モデルの推論速度を高速化します。本モデルは、動画生成において8.5倍の速度向上を実現しながら、同様の性能を維持します。事前学習済みのビデオ拡散モデルを用いて複数の有効なノイズ除去軌跡を生成することで、データの使用と生成プロセスを最適化しています。AccVideoは、映画制作やゲーム開発など、効率的な動画生成が必要な場面に特に適しており、研究者や開発者にとって有用です。
["ビデオ アップデート, AI モデル]
39.7K
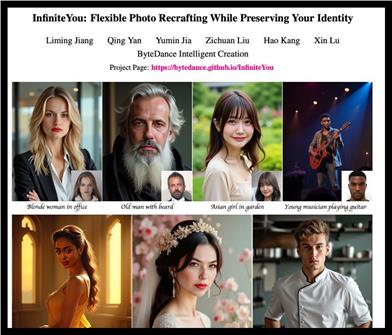
Infiniteyou
InfiniteYou(InfU)は、拡散変換器に基づいた強力なフレームワークであり、柔軟な画像再構成を実現し、ユーザーのアイデンティティを維持することを目的としています。アイデンティティの特徴を導入し、多段階トレーニング戦略を採用することで、画像生成の品質と美学を大幅に向上させ、テキストと画像のアライメントも改善します。この技術は、画像生成の類似性と美観の向上に重要な意味を持ち、様々な画像生成タスクに適用できます。
チャットボット
51.9K
Trajectorycrafter
TrajectoryCrafterは、拡散モデル技術を利用して単眼ビデオ内のカメラモーションを再設計し、ビデオの表現力と視覚的な魅力を高める、高度なカメラ軌跡リダイレクトツールです。この技術は、映画制作や仮想現実などの分野で広く適用でき、効率的で便利で革新的な特徴を備え、ユーザーにより多くの創造的な自由と制御能力を提供することを目的としています。
["ウェディングサプライヤー],["AIデジタルサイネージアプリケーション]
45.0K
海外精選
Inception Labs
Inception Labsは、拡散型大規模言語モデル(dLLMs)の開発に特化した企業です。その技術は、MidjourneyやSoraなどの高度な画像?動画生成システムから着想を得ています。拡散モデルを通じて、Inception Labsは、従来の自己回帰モデルよりも5~10倍高速で、効率性が高く、生成制御能力が優れたものを提供します。そのモデルは並列テキスト生成をサポートし、エラーや幻覚を修正でき、マルチモーダルタスクに適しており、推論と構造化データ生成において優れた性能を発揮します。スタンフォード大学、UCLA、コーネル大学の研究者とエンジニアによって設立され、拡散モデル分野のパイオニアです。
AIモデル
50.0K
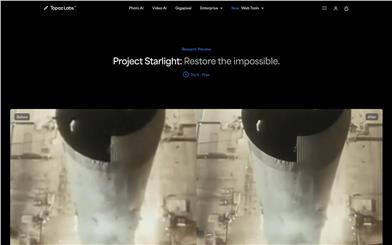
Project Starlight
Project Starlight は、Topaz Labs がリリースした AI ビデオ強化モデルで、低解像度および破損したビデオの品質向上を目的として設計されています。拡散モデル技術を採用することで、ビデオの超解像度、ノイズ除去、ぼけ除去、シャープ化などの機能を実現し、同時に時間的一貫性を維持することで、ビデオフレーム間のスムーズな遷移を確保します。この技術はビデオ強化分野における大きなブレークスルーであり、ビデオ修復と向上にこれまでにない高品質な効果をもたらします。現在、Project Starlight は無料トライアルを提供しており、今後 4K 出力をサポートする予定です。主に高品質なビデオ修復と強化を必要とするユーザーと企業を対象としています。
映像編集
43.9K
海外精選
Mercury Coder
Mercury Coder は、Inception Labs が発表した初の商用レベルの拡散大規模言語モデル(dLLM)で、コード生成向けに最適化されています。このモデルは拡散モデル技術を採用し、「粗から細」への生成方法により、生成速度と品質を大幅に向上させます。従来の自己回帰言語モデルよりも 5~10 倍高速で、NVIDIA H100 ハードウェア上で毎秒 1000 個を超えるトークンの生成速度を実現しながら、高品質のコード生成能力を維持します。この技術の背景には、自己回帰言語モデルが生成速度と推論コストにおいて抱えるボトルネックがあり、Mercury Coder はアルゴリズムの最適化によってこの制限を突破し、企業向けアプリケーションにより効率的で低コストなソリューションを提供します。
コードアシスタント
45.8K
Videograin
VideoGrainは、時空間的注意機構の調整により多粒度動画編集を実現する、拡散モデルに基づく動画編集技術です。この技術は、従来の方法におけるセマンティックアライメントと特徴量のカップリングの問題を解決し、動画コンテンツを精密に制御できます。主な利点としては、ゼロショット編集機能、効率的なテキストから領域への制御、および特徴量の分離機能が含まれます。映画のポストプロダクション、広告制作など、動画の複雑な編集が必要なシーンに適しており、編集効率と品質を大幅に向上させることができます。
映像編集
43.1K
Makeanything
MakeAnythingは、拡散変換器に基づくモデルであり、多様な分野におけるプログラムによるシーケンス生成に特化しています。高度な拡散モデルとトランスフォーマーアーキテクチャを組み合わせることで、絵画、彫刻、アイコンデザインなど、高品質で段階的な創作シーケンスを生成できます。主な利点として、様々な分野の生成タスクに対応できること、少量のサンプルで新しい分野に迅速に適応できることが挙げられます。シンガポール国立大学Show Labチームによって開発され、現在オープンソースとして提供されており、多様な分野における生成技術の発展を目指しています。
AI設計ツール
50.2K
Pippo
Pippoは、Meta Reality Labsと複数の大学が共同開発した生成モデルであり、一枚の普通の画像から高解像度の複数視点ビデオを生成できます。この技術の最大の強みは、追加の入力(パラメータ化モデルやカメラパラメータなど)なしで、高品質な1K解像度のビデオを生成できる点です。多視点拡散トランスフォーマーアーキテクチャに基づいており、仮想現実、映画制作など、幅広い応用が期待できます。Pippoのコードはオープンソースですが、事前学習済みウェイトは含まれておらず、ユーザーは自分でモデルをトレーニングする必要があります。
映像制作
66.5K
デバイス上sora
デバイス上Soraはオープンソースプロジェクトであり、線形比例ジャンプ(LPL)、時間次元マーキングマージ(TDTM)、動的ロード並列推論(CI-DL)などの技術を用いて、iPhone 15 Proなどのモバイルデバイス上での効率的な動画生成を実現することを目指しています。本プロジェクトはOpen-Soraモデルに基づいて開発されており、テキスト入力に基づいて高画質動画を生成できます。主な利点としては、高効率性、低消費電力、モバイルデバイスへの最適化などが挙げられます。この技術は、短動画作成、広告制作など、モバイルデバイス上で迅速に動画コンテンツを生成する必要があるシナリオに適しています。現在オープンソースとして公開されており、ユーザーは無料で利用できます。
映像制作
47.2K

Diffsplat
DiffSplatは、テキストプロンプトと単一視点画像から3Dガウシアン点群を高速に生成できる革新的な3D生成技術です。大規模に事前学習されたテキストツーイメージ拡散モデルを活用することで、効率的な3Dコンテンツ生成を実現しています。従来の3D生成手法におけるデータセットの限定性や、2D事前学習モデルの有効活用が難しいという問題を解決しつつ、3Dの一貫性を維持しています。DiffSplatの主な利点としては、高速な生成速度(1~2秒で完了)、高品質な3D出力、そして多様な入力条件への対応が挙げられます。本モデルは、特に高品質な3Dモデルの高速生成が必要な場面において、学術研究や産業用途で幅広い将来性を持っています。
3Dモデリング
49.4K

Go With The Flow
Go with the Flowは、従来の高斯ノイズの代わりにツイストノイズを用いることで、ビデオ拡散モデルのモーションモードを効率的に制御する革新的なビデオ生成技術です。元のモデルアーキテクチャを変更することなく、計算コストを増やすことなく、ビデオ内の物体やカメラの動きを正確に制御できます。主な利点として、効率性、柔軟性、拡張性が挙げられ、画像からビデオへの生成、テキストからビデオへの生成など、幅広いシーンで活用できます。Netflix Eyeline Studiosなどの研究者によって開発され、高い学術的価値と商業的応用可能性を備えており、現在オープンソースとして無料で公開されています。
映像制作
52.2K

Tokenverse
TokenVerseは、革新的な多概念パーソナライズ手法です。事前学習済みテキストツーイメージ拡散モデルを活用し、単一画像から複雑な視覚要素と属性を分離し、シームレスな概念組み合わせ生成を実現します。この手法は、概念の種類や広さに関する既存技術の限界を突破し、物体、アクセサリー、材質、ポーズ、照明など、多様な概念をサポートします。TokenVerseの重要性は、画像生成分野により柔軟でパーソナライズされたソリューションを提供し、様々な場面におけるユーザーの多様なニーズを満たせる点にあります。現在、TokenVerseのコードは公開されていませんが、パーソナライズされた画像生成における潜在能力は、広く注目を集めています。
画像生成
53.5K
X Dyna
X-Dynaは、革新的なゼロショットの人物画像アニメーション生成技術です。駆動ビデオの表情や動作を一枚の人物画像に移転することで、リアルで表現力豊かな動画効果を生み出します。この技術は拡散モデルに基づいており、Dynamics-Adapterモジュールにより、参照外観コンテキストを拡散モデルの空間的注意機構に効果的に統合し、同時に運動モジュールが滑らかで複雑な動きのディテールを合成する能力を維持します。身体の姿勢制御だけでなく、ローカル制御モジュールによって顔の表情を人物のアイデンティティに依存せず捉え、正確な表情の伝達を実現します。X-Dynaは、多様な人物やシーンを含むビデオの混合データで学習されており、物理的な人体運動や自然なシーンのダイナミクスを学習し、高度にリアルで表現力豊かなアニメーションを生成します。
映像制作
46.1K
中国語精選
Hunyuan 3D 2.0
HunYuan-3D 2.0は、テンセントが開発した、高解像度でテクスチャ付きの3Dアセット生成に特化した、高度な大規模3D合成システムです。このシステムは、大規模形状生成モデルHunYuan-3D-DiTと大規模テクスチャ合成モデルHunYuan-3D-Paintという2つの基本コンポーネントで構成されています。形状とテクスチャの生成を分離することで、柔軟性の高い3Dアセット制作プラットフォームを提供します。幾何学的詳細、条件整合性、テクスチャ品質において、既存のオープンソースおよびクローズドソースモデルを凌駕しており、高い実用性と革新性を備えています。現在、推論コードと事前トレーニング済みモデルはオープンソース化されており、公式サイトまたはHugging Faceスペースから簡単に体験できます。
3Dモデリング
141.9K
シェーダとしての拡散 (Diffusion As Shader)
Diffusion as Shader (DaS) は、3D認識に基づく拡散プロセスを通じてビデオ生成の多様な制御を実現することを目指した、革新的なビデオ生成制御モデルです。3Dトラッキングビデオを制御入力として利用し、メッシュからビデオ生成、カメラ制御、モーション転移、オブジェクト操作など、様々なビデオ制御タスクを統一アーキテクチャ内でサポートします。DaSの主な利点は、その3D認識能力であり、生成ビデオの時間的一貫性を効果的に向上させ、少量のデータで短時間で微調整することで強力な制御能力を発揮します。本モデルは、香港科技大学を始めとする複数の大学研究チームが共同で開発し、ビデオ生成技術の発展を促進し、映画制作、仮想現実などの分野に、より柔軟で効率的なソリューションを提供することを目指しています。
映像制作
51.9K
Seedvr
SeedVRは、現実世界の動画修復タスクに特化した、革新的な拡散トランスフォーマーモデルです。独自のシフトウィンドウアテンションメカニズムにより、任意の長さと解像度の動画シーケンスを効率的に処理できます。SeedVRは、生成能力とサンプリング効率の両面で顕著な向上を達成しており、従来の拡散モデルと比較して、合成および現実世界のベンチマークテストで優れたパフォーマンスを示します。さらに、因果的ビデオ自己符号化器、混合画像と動画のトレーニング、段階的トレーニングなどの最新の技術を取り入れることで、動画修復分野における競争力をさらに高めています。最先端の動画修復技術として、SeedVRは動画制作者やポストプロダクション担当者にとって強力なツールとなり、特に低画質または破損した動画素材の処理において、動画品質の向上に大きく貢献します。
映像編集
50.8K
Creatilayout
CreatiLayoutは、双子型多モーダル拡散トランスフォーマー(Siamese Multimodal Diffusion Transformer)を用いて、高品質かつ細粒度で制御可能な画像生成を実現する革新的なレイアウトから画像生成技術です。この技術は、色、テクスチャ、形状、数量、テキストなど、複雑な属性を正確にレンダリングでき、正確なレイアウトと画像生成が必要なアプリケーションシナリオに適しています。主な利点としては、効率的なレイアウト誘導統合、強力な画像生成能力、大規模データセットのサポートなどが挙げられます。CreatiLayoutは、復旦大学とByteDance社が共同で開発し、クリエイティブデザイン分野における画像生成技術の推進を目指しています。
AI設計ツール
56.9K
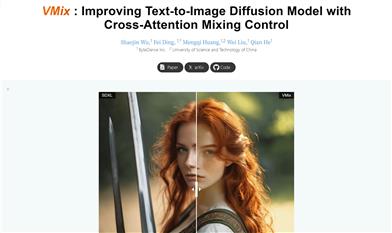
Vmix
VMixは、テキストツーイメージ拡散モデルの美的品質を向上させる技術です。革新的な条件制御手法であるValue-Mixed Cross-Attentionにより、画像の美的表現を体系的に強化します。プラグアンドプレイ型の美的アダプターとして、視覚的な概念の汎用性を維持しながら、生成画像の品質を向上させます。VMixの重要な洞察は、既存の拡散モデルの美的表現を強化しつつ、画像とテキストの整合性を維持するために、優れた条件制御手法を設計することです。VMixは十分に柔軟性があり、再トレーニングなしでより優れた視覚的性能を実現するために、コミュニティモデルにも適用できます。
画像生成
46.6K
Diffsensei
DiffSenseiは、多モーダル大規模言語モデル(LLM)と拡散モデルを組み合わせた、カスタマイズ可能な漫画生成モデルです。ユーザーが提供するテキストプロンプトとキャラクター画像に基づき、制御可能な白黒漫画パネルを生成し、柔軟なキャラクター適応性を備えています。この技術の重要性は、自然言語処理と画像生成を組み合わせることで、漫画制作とパーソナライズされたコンテンツ生成に新たな可能性を提供することにあります。DiffSenseiモデルは、高品質な画像生成、多様な応用シナリオ、そしてリソースの効率的な利用で注目されています。現在、GitHubで公開されており、無料でダウンロードして使用できますが、使用には一定の計算リソースが必要となる可能性があります。
AI設計ツール
90.3K

Dynamiccontrol
DynamicControlは、テキストから画像への拡散モデルの制御力を向上させるためのフレームワークです。多様な制御信号を動的に組み合わせることで、様々な数と種類の条件を適応的に選択し、より信頼性が高く詳細な画像合成を可能にします。このフレームワークはまず、事前学習済みの条件生成モデルと識別モデルを用いた二重ループコントローラーを使用して、すべての入力条件に対する初期の真偽スコア順序を生成します。次に、多様なモダリティを持つ大規模言語モデル(MLLM)を用いて効率的な条件評価器を構築し、条件の順序を最適化します。DynamicControlはMLLMと拡散モデルを統合的に最適化し、MLLMの推論能力を活用して多条件テキストから画像へのタスクを促進し、最終的に順位付けされた条件を入力として並列マルチコントロールアダプターに渡し、動的な視覚条件の特徴マップを学習し、それらを統合してControlNetを調整することで、生成画像の制御を強化します。
AIモデル
47.7K
Invsr
InvSRは、拡散逆転に基づく画像超解像技術です。大規模な事前学習済み拡散モデルに含まれる豊富な画像事前知識を利用して、超解像性能を向上させます。部分ノイズ予測戦略を用いて拡散モデルの中間状態を構築し、それを開始サンプリング点として用います。そして、深層ノイズ予測器を用いて最適なノイズマップを推定することで、前方拡散過程におけるサンプリングを初期化し、高解像度な結果を生成します。InvSRは、1ステップから5ステップまで、任意のステップ数のサンプリングをサポートしており、1ステップのサンプリングだけでも、既存の最先端手法と同等以上の性能を示します。
画像強化
49.7K

Colorflow
ColorFlowは、画像シーケンスの彩色を目的としたモデルであり、彩色処理においてキャラクターやオブジェクトの識別情報を保持することに特に重点を置いています。このモデルはコンテキスト情報を利用し、参照画像プールに基づいて、白黒画像シーケンス内の異なる要素(キャラクターの髪や服装など)に正確に色を生成し、参照画像の色の一貫性を確保します。ColorFlowは3段階の拡散モデルフレームワークを通じて、各識別の微調整や明示的な識別埋め込みの抽出を行うことなく、関連する色の参照による画像彩色を実現する、斬新な検索強化彩色処理を提案しています。ColorFlowの主な利点には、識別情報を保持しつつ高品質な彩色効果を提供できることが挙げられ、これは漫画やアニメーションシリーズの彩色において重要な市場価値を持ちます。
画像編集
47.2K
Leffa
Leffaは、人物画像の生成を制御できる統合フレームワークです。人物の外観(バーチャル試着など)やポーズ(ポーズ転送など)を正確に制御できます。本モデルは、トレーニング中に目標クエリが参照画像の対応する領域に注目するように誘導することで、ディテール歪みを軽減しつつ、高画質の画像を維持します。Leffaの主な利点としては、モデル非依存性があり、他の拡散モデルの性能向上に利用できる点が挙げられます。
AI設計ツール
75.3K
Comfyui HelloMeme
HelloMemeは、高レベルで詳細な条件を埋め込むために空間編組注意力(Spatial Knitting Attentions)を統合した拡散モデルです。画像と動画の生成をサポートし、生成動画と駆動動画間の表情の一貫性の向上、VRAM使用量の削減、アルゴリズムの最適化などの利点があります。HelloVisionチームによって開発され、HelloGroup Inc.に属するHelloMemeは、最先端の画像?動画生成技術であり、商業的および教育的な価値を有しています。
映像制作
67.1K
Color Diffusion
Color-diffusionは、拡散モデルに基づいた画像着色プロジェクトです。LAB色空間を用いて白黒画像を着色します。主な利点は、既存のグレースケール情報(Lチャネル)を利用し、学習済みモデルで色情報(AチャネルとBチャネル)を予測できる点です。この技術は、特に古い写真の修復や芸術創作において、画像処理分野で重要な意味を持ちます。Color-diffusionはオープンソースプロジェクトであり、作者の好奇心と拡散モデルをゼロから学習する体験を目的として迅速に構築されました。現在は無料で利用可能ですが、改善の余地は大きいです。
画像編集
51.3K

Anchorcrafter
AnchorCrafterは、目標となる人物とカスタマイズ可能なオブジェクトを含む2D動画を生成するための革新的な拡散モデルシステムです。人物と物体間のインタラクション(HOI)を統合することにより、高い視覚的忠実度と制御可能なインタラクションを実現します。本システムは、HOI-外観知覚向上により、任意の多視点からオブジェクトの外観を認識し、人物と物体の外観を分離します。また、HOI-モーション注入により、オブジェクトの軌跡条件と相互遮蔽管理の課題を克服し、複雑な人物と物体間のインタラクションを実現します。さらに、HOI領域の再重み付け損失を学習目標とすることで、オブジェクトの詳細な学習を強化します。この技術は、オブジェクトの外観と形状を維持しながら、人物の外観とモーションの一貫性も維持するため、オンラインビジネス、広告、消費者エンゲージメントなどの分野で重要な意味を持ちます。
映像制作
197.3K
Text To Pose
text-to-poseは、テキスト記述から人物のポーズを生成し、そのポーズを用いて画像を生成することを目的とした研究プロジェクトです。自然言語処理とコンピュータビジョンの技術を融合し、拡散モデルの制御と品質を向上させることで、テキストから画像への生成を実現しています。NeurIPS 2024 Workshopで発表された論文に基づいており、革新的かつ最先端の技術です。主な利点としては、画像生成の精度と制御性の向上、ならびに芸術創作や仮想現実などの分野における応用可能性が挙げられます。
画像生成
47.7K
Diffusiondrive
DiffusionDriveは、リアルタイムのエンドツーエンド自動運転のための遮断拡散モデルです。拡散ノイズ除去ステップを削減することで計算速度を向上させながら、高い精度と多様性を維持します。このモデルは人間のデモンストレーションから直接学習するため、複雑な前処理や後処理手順が不要で、リアルタイムの自動運転判断を実現します。DiffusionDriveはNAVSIMベンチマークテストにおいて88.1 PDMSという画期的な成果を達成し、45 FPSで動作します。
AIモデル
46.1K
- 1
- 2
- 3
- 4
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
37.8K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.6K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M