%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Zerosearch
ZeroSearch は、実際の検索エンジンとの相互作用なしに、大規模な言語モデル(LLMs)の検索能力を促進する新しいタイプの強化学習フレームワークです。教師あり微調整を通じて、ZeroSearch は LLM を関連する無関係なドキュメントを生成できる検索モジュールに変換します。また、モデルの推論能力を段階的に促進するコースウェアメカニズムを導入しています。この技術の主な利点は、実際の検索エンジンに基づくモデルよりもパフォーマンスが高いことに加え、API 成本が発生しないことです。さまざまな規模の LLM に対応しており、異なる強化学習アルゴリズムをサポートしています。これは、効率的な検索能力を持つ必要のある研究や開発チームに最適です。
検索能力
37.5K

Search R1
Search-R1は、推論を行い、検索エンジンを呼び出すことができる大規模言語モデル(LLM)をトレーニングすることを目的とした強化学習フレームワークです。veRLをベースに構築されており、様々な強化学習手法と異なるLLMアーキテクチャをサポートしており、ツール拡張推論の研究開発において、効率性と拡張性を備えています。
モバイルアプリケーションと周辺機器
38.1K

D1
このモデルは、強化学習と高品質な推論軌跡のマスクされた自己教師あり微調整により、拡散型大規模言語モデルの推論能力の向上を実現しました。この技術の重要性は、モデルの推論プロセスを最適化し、計算コストを削減しながら、学習ダイナミクスの安定性を維持できる点にあります。ライティングや推論タスクで効率を向上させたいユーザーに適しています。
レクチャー資料
37.8K
Deepcoder
DeepCoder-14B-Previewは、強化学習に基づくコード推論の大規模言語モデルであり、長いコンテキストを処理でき、60.6%の合格率を達成しており、プログラミングタスクやコード生成の自動化に適しています。本モデルの強みは、その革新的なトレーニング方法により、他のモデルよりも優れた性能を提供し、完全にオープンソースであるため、幅広いコミュニティアプリケーションや研究をサポートしている点です。
コーディング
38.1K
中国語精選
混元T1
混元T1はテンセントが発表した超大規模推論モデルであり、強化学習技術に基づいており、大量の後訓練によって推論能力を大幅に向上させています。長文処理とコンテキストの把握において優れた性能を発揮し、計算資源の消費も最適化されており、効率的な推論能力を備えています。あらゆる種類の推論タスクに適用でき、特に数学、論理推論などの分野で優れた性能を発揮します。本製品は深層学習をベースとしており、実際のフィードバックを参考に継続的に最適化されており、研究、教育など複数の分野での応用に向いています。
AIモデル
42.0K
中国語精選
混元T1
混元T1は、テンセントが開発した強化学習に基づく深層推論大規模モデルです。大規模な事後学習と人間の好みの調整により、推論能力と効率が大幅に向上しています。大規模なHybrid-Transformer-Mamba MoEアーキテクチャに基づいており、長文の処理において優れたパフォーマンスを発揮します。複雑な推論と論理的な解決策を必要とするあらゆるユーザーに適しており、科学研究や技術開発を支援します。
AIモデル
47.2K
混元T1
混元T1は、強化学習に基づく超大規模推論モデルであり、事後学習によって推論能力を大幅に向上させ、人間の好みと整合性をとっています。本モデルは長文の処理と複雑な推論タスクに特化しており、顕著な性能上の優位性を示しています。
人工知能
41.4K
Light R1 14B DS
Light-R1-14B-DSは、北京奇虎科技有限公司が開発したオープンソースの数学モデルです。DeepSeek-R1-Distill-Qwen-14Bをベースに強化学習で訓練され、AIME24とAIME25の数学コンテストベンチマークテストでそれぞれ74.0と60.2の高得点を達成し、多くの320億パラメーターのモデルを凌駕しています。軽量な予算で、既に長鎖推論微調整モデルの強化学習を試行することに成功し、オープンソースコミュニティに強力な数学モデルツールを提供しています。このモデルのオープンソース化は、特に数学問題解決における教育分野での自然言語処理の進歩を促進し、研究者や開発者にとって貴重な研究基盤と実践ツールとなります。
AIモデル
51.1K

Light R1
Light-R1は、Qihoo360が開発したオープンソースプロジェクトであり、コース形式の教師あり微調整(SFT)、直接選好最適化(DPO)、強化学習(RL)によって長鎖推論モデルを訓練することを目指しています。このプロジェクトは、データセットの浄化と効率的な訓練方法によって、ゼロから長鎖推論能力を実現しました。主な利点としては、オープンソースの訓練データ、低コストの訓練方法、そして数学的推論分野における優れた性能が挙げられます。プロジェクトの背景は、現在の長鎖推論モデルの訓練ニーズに基づいており、透明性があり再現可能な訓練方法を提供することを目指しています。プロジェクトは現在無料でオープンソースとなっており、研究機関や開発者による利用に適しています。
モバイルアクセサリーと周辺機器
50.8K
R1 Omni
R1-Omniは、強化学習によってモデルの推論能力と汎化能力を向上させた、革新的なマルチモーダル感情認識モデルです。HumanOmni-0.5Bを基に開発され、感情認識タスクに特化しており、視覚および音声モーダル情報から感情分析を行うことができます。主な利点としては、強力な推論能力、感情認識性能の顕著な向上、および分布外データにおける優れたパフォーマンスが挙げられます。感情分析、スマートカスタマーサービスなどの分野でマルチモーダルな理解が必要なシナリオに適用でき、重要な研究および応用価値を有しています。
家庭用サービス
53.5K
Steiner 32b Preview
Steinerは、Yichao 'Peak' Jiによって開発された推論モデルシリーズであり、強化学習による合成データ上でのトレーニングに焦点を当てており、推論時に複数の経路を探索し、自律的に検証または遡ることができます。このモデルの目標は、OpenAI o1の推論能力を再現し、推論時の拡張曲線を検証することです。Steiner-previewは進行中のプロジェクトであり、オープンソースとする目的は知識を共有し、より多くのリアルユーザーからのフィードバックを得ることです。このモデルはいくつかのベンチマークテストで優れたパフォーマンスを示していますが、OpenAI o1の推論拡張能力を完全に実現しているわけではなく、開発段階にあります。
AIモデル
45.5K
Notagen
NotaGen は、事前学習、ファインチューニング、強化学習の3段階を経て音楽生成の品質を向上させる革新的な記号音楽生成モデルです。大規模言語モデル技術を利用して、高品質のクラシック音楽楽譜を生成し、音楽創作に新たな可能性をもたらします。このモデルの主な利点には、効率的な生成、多様なスタイル、高品質の出力などが含まれます。音楽創作、教育、研究などの分野に適用でき、幅広い応用が期待できます。
コンピューター
54.4K
SWE RL
SWE-RLは、Facebook Researchが提案した、強化学習に基づく大規模言語モデルの推論技術です。オープンソースソフトウェアの進化データを利用して、ソフトウェアエンジニアリングタスクにおけるモデルのパフォーマンスを向上させることを目的としています。ルール駆動型の報酬メカニズムにより、モデルの推論能力を最適化し、より高品質なコードの理解と生成を可能にします。SWE-RLの主な利点は、革新的な強化学習手法とオープンソースデータの有効活用であり、ソフトウェアエンジニアリング分野に新たな可能性をもたらします。本技術は現在研究段階にあり、商業的な価格設定はまだ明確ではありませんが、開発効率とコード品質の向上に大きな可能性を秘めています。
コードアシスタント
43.6K
Mlgym
MLGymは、MetaのGenAIチームとUCSB NLPチームによって開発された、AI研究エージェントの訓練と評価のためのオープンソースのフレームワークとベンチマークです。多様なAI研究タスクを提供することにより、強化学習アルゴリズムの発展を促進し、研究者が現実世界の研究シナリオにおいてモデルを訓練および評価するのに役立ちます。このフレームワークは、コンピュータビジョン、自然言語処理、強化学習など、複数のタスクをサポートしており、AI研究のための標準化されたテストプラットフォームを目指しています。
モデルトレーニングとデプロイメント
44.2K
VLM R1
VLM-R1は、参照式理解(Referring Expression Comprehension, REC)などの画像理解タスクに特化した、強化学習に基づくビジュアル言語モデルです。R1(Reinforcement Learning)とSFT(Supervised Fine-Tuning)を組み合わせることで、ドメイン内およびドメイン外のデータにおいて優れた性能を示します。VLM-R1の主な利点としては、安定性と汎化能力があり、様々なビジュアル言語タスクで高いパフォーマンスを発揮します。Qwen2.5-VLを基盤として構築され、Flash Attention 2などの高度な深層学習技術を活用することで、計算効率を向上させています。VLM-R1は、正確な画像理解が求められるアプリケーションシナリオに適した、効率的で信頼性の高いソリューションを提供することを目指しています。
AIモデル
49.7K
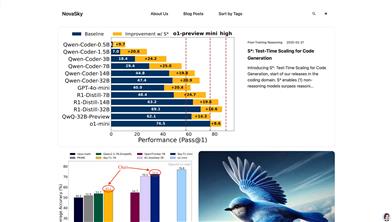
Novasky
NovaSkyは、コード生成と推論モデルの性能向上に特化したAI技術プラットフォームです。革新的なテスト時拡張技術(S*など)や強化学習蒸留推論などの技術により、非推論モデルの性能を大幅に向上させ、コード生成分野で優れた成果を上げています。開発者に効率的で低コストなモデルのトレーニングと最適化ソリューションを提供し、プログラミングタスクにおける効率性と正確性の向上を支援することに尽力しています。NovaSkyの技術的背景はSky Computing Lab @ Berkeleyに由来し、強力な学術的支援と最先端の技術研究基盤を備えています。現在、NovaSkyは推論コスト最適化やモデル蒸留技術など、様々なモデル最適化手法を提供しており、様々な開発者のニーズに対応しています。
開発とツール
44.7K
Alphamaze
AlphaMazeは、視覚推論タスクの解決のために設計されたデコーダー言語モデルです。迷路解法タスクのトレーニングを通じて、言語モデルの視覚推論における可能性を示しています。このモデルは、15億パラメーターのQwenモデルをベースに構築されており、教師ありファインチューニング(SFT)と強化学習(RL)によってトレーニングされています。主な利点は、視覚タスクをテキスト形式に変換して推論できることであり、従来の言語モデルが空間理解において不足していた点を補っています。このモデルの開発背景は、特に段階的な推論が必要な状況において、AIの視覚タスクにおけるパフォーマンス向上にあります。現在、AlphaMazeは研究プロジェクトとして、商業化価格や市場ポジショニングは明確にされていません。
AIモデル
44.2K
Homietele
HOMIEは、強化学習と低コストの外骨格ハードウェアシステムを通じて、正確な歩行と操作タスクを実現することを目的とした、革新的なヒューマノイドロボット遠隔操作ソリューションです。本技術の重要性は、従来の遠隔操作システムの非効率性と不安定性を解決することにあります。人体運動捕捉と強化学習トレーニングフレームにより、ロボットはより自然に複雑なタスクを実行できます。主な利点としては、効率的なタスク遂行能力、複雑なモーションキャプチャ機器が不要なこと、そして迅速なトレーニング時間などが挙げられます。本製品は主に、ロボット研究機関、製造業、物流業界を対象としており、価格は公表されていませんが、ハードウェアシステムのコストは低く、高いコストパフォーマンスを備えています。
機械人
46.9K
Deepscaler 1.5B Preview
DeepScaleR-1.5B-Previewは、強化学習によって最適化された大規模言語モデルであり、数学問題解決能力の向上に特化しています。このモデルは分散型強化学習アルゴリズムを用いることで、長文推論における精度を大幅に向上させています。主な利点としては、効率的なトレーニング戦略、顕著な性能向上、そしてオープンソースによる柔軟性などが挙げられます。このモデルはカリフォルニア大学バークレー校のSky Computing LabとBerkeley AI Researchチームによって開発され、特に数学教育や競技数学の分野における人工知能の応用を推進することを目的としています。MITオープンソースライセンスを採用しており、研究者や開発者は無料で利用できます。
学習教育
59.9K
R1 V
R1-Vは、視覚言語モデル(VLM)の汎化能力に特化したプロジェクトです。検証可能な報酬による強化学習(RLVR)技術を用いることで、特に分布外(OOD)テストにおいて、VLMの視覚カウントタスクにおける汎化能力を大幅に向上させました。この技術の重要性は、わずか2.62ドルのトレーニングコストで、大規模モデルを効率的に最適化できる点にあり、視覚言語モデルの実用化に新たな道を切り開きます。プロジェクトの背景は、既存のVLMトレーニング方法の改善に基づいており、革新的なトレーニング戦略を通じて、複雑な視覚タスクにおけるモデルのパフォーマンス向上を目指しています。R1-Vのオープンソース性も、研究者や開発者が高度なVLM技術を探求し、応用するための重要なリソースとなっています。
AIモデル
54.4K
高品質新製品

Tülu 3 405B
Tülu 3 405Bは、Allen Institute for AIによって開発された、4050億パラメータを持つオープンソース言語モデルです。革新的な強化学習フレームワーク(RLVR)により性能が向上しており、特に数学と指示追従タスクにおいて優れた成果を示します。Llama-405Bモデルをベースに、教師ありファインチューニングや選好最適化などの技術を用いて最適化されています。Tülu 3 405Bのオープンソース性は、高性能な言語モデルを必要とする様々なアプリケーションシナリオにおいて、研究開発分野における強力なツールとしての利用を可能にします。
AIモデル
70.7K
CUA
Computer-Using Agent(CUA)は、OpenAIが開発した高度なAIモデルです。GPT-4oのビジョン能力と、強化学習による高度な推論能力を組み合わせることで、人間のようにグラフィカルユーザーインターフェース(GUI)と対話できます。特定のOSのAPIやネットワークインターフェースに依存することなく、フォームへの入力やウェブページの閲覧など、様々なデジタル環境でタスクを実行できます。この技術の登場はAI発展の次のステップを示しており、日常的なツールにおけるAIの応用可能性を大きく広げます。CUAは現在、研究プレビュー段階にあり、Operatorを通じて米国のProユーザーに提供されています。
個人補助
59.9K
Deepseek R1 Distill Qwen 1.5B
DeepSeek-R1-Distill-Qwen-1.5Bは、DeepSeekチームが開発したオープンソース言語モデルであり、Qwen2.5シリーズを蒸留?最適化して作成されました。大規模な強化学習とデータ蒸留技術により、推論能力と性能を大幅に向上させながら、モデルサイズを小さく抑えています。複数のベンチマークテストで優れた成果を示しており、特に数学、コード生成、推論タスクにおいて顕著な優位性を発揮します。本モデルは商用利用が可能で、ユーザーによる修正や派生作品の作成も許可されています。研究機関や企業による高性能自然言語処理アプリケーション開発に最適です。
AIモデル
216.1K
Deepseek R1 Distill Qwen 7B
DeepSeek-R1-Distill-Qwen-7Bは、Qwen-7Bを蒸留最適化し、強化学習によって最適化された推論モデルです。数学、コード、推論タスクにおいて優れた性能を発揮し、高品質な推論チェーンと解決策を生成できます。大規模な強化学習とデータ蒸留技術により、推論能力と効率性が大幅に向上しており、複雑な推論と論理分析が必要なシナリオに適しています。
モデルトレーニングとデプロイメント
137.2K
Deepseek R1 Distill Llama 8B
DeepSeek-R1-Distill-Llama-8Bは、DeepSeekチームが開発した高性能言語モデルであり、Llamaアーキテクチャをベースに、強化学習と蒸留によって最適化されています。このモデルは、推論、コード生成、多言語タスクにおいて優れた性能を発揮し、純粋な強化学習によって推論能力を向上させた、オープンソースコミュニティにおける初のモデルです。商用利用、修正、派生作品の作成を許可しており、学術研究や企業アプリケーションに適しています。
AIモデル
138.8K
Deepseek R1 Distill Qwen 14B
DeepSeek-R1-Distill-Qwen-14Bは、DeepSeekチームがQwen-14Bを基に開発した蒸留モデルであり、推論とテキスト生成タスクに特化しています。大規模な強化学習とデータ蒸留技術により、推論能力と生成品質を大幅に向上させながら、計算資源の消費を削減しています。主な利点として、高性能、低リソース消費、幅広い適用性があり、効率的な推論とテキスト生成を必要とする場面に適しています。
AIモデル
261.6K
Deepseek R1 Distill Qwen 32B
DeepSeek-R1-Distill-Qwen-32Bは、DeepSeekチームが開発した高性能言語モデルであり、Qwen-2.5シリーズを基に蒸留最適化されています。このモデルは複数のベンチマークテストで優れた性能を示しており、特に数学、コード、推論タスクにおいて顕著です。主な利点として、効率的な推論能力、強力な多言語サポート、そしてオープンソースである点が挙げられ、研究者や開発者による二次開発や応用が容易です。このモデルは、スマートカスタマーサービス、コンテンツ作成、コードアシストなど、高性能なテキスト生成が必要な場面に適しており、幅広い応用が期待できます。
モデルトレーニングとデプロイ
112.1K
Deepseek R1 Distill Llama 70B
DeepSeek-R1-Distill-Llama-70Bは、DeepSeekチームが開発した大規模言語モデルで、Llama-70Bアーキテクチャをベースに強化学習によって最適化されています。このモデルは、推論、対話、多言語タスクにおいて優れた性能を発揮し、コード生成、数学的推論、自然言語処理など、多様なアプリケーションシナリオに対応しています。主な利点として、効率的な推論能力と複雑な問題解決能力があり、オープンソースと商用利用の両方をサポートしています。高性能な言語生成と推論能力が必要な企業や研究機関に適しています。
AIモデル
75.6K
Pasa
PaSaは、バイトダンスが開発した高度な学術論文検索エージェントです。大規模言語モデル(LLM)技術に基づいており、検索ツールを自律的に呼び出し、論文を読み、関連参考文献を絞り込むことで、複雑な学術的な検索クエリに対して包括的で正確な結果を取得します。この技術は強化学習によって最適化され、合成データセットAutoScholarQueryを用いて訓練されており、実世界のクエリデータセットRealScholarQueryにおいて優れた性能を示し、従来の検索エンジンやGPTベースの方法を大幅に上回っています。PaSaの主な利点は、高い再現率と精度であり、研究者に効率的な学術検索体験を提供します。
AI検索
59.6K
中国語精選
Kimi K1.5
Kimi k1.5は、MoonshotAIによって開発されたマルチモーダル言語モデルです。強化学習とロングコンテキスト拡張技術により、複雑な推論タスクにおけるモデルのパフォーマンスが大幅に向上しました。AIMEやMATH-500などの数学的推論タスクにおいて、GPT-4oやClaude Sonnet 3.5を上回るなど、複数のベンチマークテストで業界トップレベルの成果を達成しています。主な利点としては、効率的なトレーニングフレームワーク、強力なマルチモーダル推論能力、ロングコンテキストのサポートなどが挙げられます。Kimi k1.5は、プログラミング支援、数学の問題解決、コード生成など、複雑な推論と論理分析を必要とするアプリケーションシナリオを主に対象としています。
モデルトレーニングとデプロイ
219.1K
- 1
- 2
- 3
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M