%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Animagine XL 4.0
Animagine XL 4.0は、Stable Diffusion XL 1.0を微調整したアニメテーマの生成モデルです。840万枚もの多様なアニメ風画像を用いて、2650時間にわたるトレーニングが実施されました。このモデルは、テキストプロンプトによるアニメテーマ画像の生成と修正に特化しており、様々な特殊タグに対応し、画像生成の様々な側面を制御できます。主な利点としては、高品質な画像生成、豊富なアニメスタイルのディテール、特定のキャラクターやスタイルの正確な再現などが挙げられます。Cagliostro Research Labによって開発され、CreativeML Open RAIL++-Mライセンスを採用しているため、商用利用と改変が可能です。
画像生成
109.8K
Latentsync
LatentSyncは、バイトダンスによって開発された音声条件付き潜在拡散モデルに基づくリップシンクフレームワークです。Stable Diffusionの強力な能力を直接活用し、中間モーション表現を一切必要とせずに、複雑な音声?動画の関連付けをモデル化できます。提案された時間表現アライメント(TREPA)技術により、生成された動画フレームの時間的一貫性を効果的に向上させながら、リップシンクの精度を維持します。この技術は、動画制作、バーチャルYouTuber、アニメーション制作などの分野で重要な応用価値を持ち、制作効率の大幅な向上、人件費の削減、よりリアルで自然な視聴体験をもたらします。LatentSyncのオープンソース特性により、学術研究や産業実践で広く利用され、関連技術の発展と革新を促進します。
映像制作
51.6K
Tryoffdiff
TryOffDiffは、拡散モデルに基づく高精細な衣服再構築技術です。着用者の単一の写真から標準化された衣服画像を生成します。従来のバーチャル試着とは異なり、衣服の形状、質感、複雑な模様を正確に捉えるという課題に対処しながら、標準化された衣服画像の抽出を目指しています。Stable DiffusionとSigLIPベースの視覚的条件付けを使用することで、高精細さとディテールの保持を保証します。VITON-HDデータセットでの実験により、姿勢変換やバーチャル試着に基づいた基準手法よりも優れており、前処理と後処理の手順が少ないことが示されています。TryOffDiffは、eコマース製品画像の品質向上だけでなく、生成モデルの評価を推進し、高精細再構築における将来の研究を促進します。
AI設計ツール
74.8K
SD3.5 Large IP アダプター
SD3.5-Large-IP-アダプターは、InstantX Teamが開発したStable Diffusion 3.5 Largeモデルに基づくIPアダプターです。このモデルは、画像処理作業をテキスト処理に例えることができ、強力な画像生成能力を備えています。さらに、アダプター技術により、画像生成の品質と効果を向上させることができます。この技術の重要性は、特にクリエイティブな仕事や芸術創作の分野において、画像生成技術の発展を促進できる点にあります。製品の背景情報として、このモデルはHugging Faceとfal.aiがスポンサーとなり、stabilityai-ai-communityのライセンスに従って提供されています。
AIモデル
61.8K
Bharatdiffusion
BharatDiffusionは、インドの多様な風景、文化、遺産に合わせて微調整されたAIベースの画像生成モデルです。インドの豊かな文化と特徴を反映した高品質な画像を生成できます。このモデルはStable Diffusion技術を用いてすべての画像生成を処理し、インドの多様性と活気に呼応するコンテンツを保証します。
画像生成
54.4K
Sd Ppp
sd-pppは、Adobe Photoshopと様々なStable Diffusionインターフェース(SD/SDForge/ComfyUIなど)間の通信を可能にするプラグインです。テキストレイヤーや画像レイヤーを含む多層操作に対応し、複数のドキュメントや複数のPhotoshopインスタンスを処理でき、ドキュメントの特定領域での作業も可能です。ワークフローの簡素化、制作効率の向上、Stable Diffusionの強力な機能を活用したデザインやアート作品への応用を実現するため、デザイナーやアーティストにとって強力なツールとなります。
Stable Diffusion
127.0K
Comfyuiオブジェクト移行
ComfyUI_Object_Migrationは、Stable Diffusion (SD)モデルに焦点を当てた実験的なプロジェクトです。DITモデルの自己注意機構を活用することで、単一生成画像内での同一オブジェクトまたはキャラクターの高い一貫性を達成します。プリプロセスのロジックを簡素化することで、効率的な転移手法を開発し、モデルに必要な内容に注目させ、驚異的な一貫性を提供します。現在、衣料品に適用可能な転移モデルが開発されており、カートゥーン風の衣料品を現実的なスタイルに、または現実的な衣料品をカートゥーン風のスタイルに移行させることが可能です。また、ウェイト制御によるデザイン創造性の向上も実現しています。
DITモデル
49.1K
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Lightは、テキストから画像を生成するAIモデルです。LoRA(Low-Rank Adaptation)技術を用いることで、ユーザーが提供するテキストプロンプトに基づき、高品質な画像を生成できます。この技術の重要性は、計算コストを抑えつつモデルのファインチューニングを実現し、生成画像の多様性と品質を維持できる点にあります。本モデルはStable Diffusion 3.5 Largeモデルをベースに、特定の画像生成ニーズに合うよう最適化?調整されています。
画像生成
61.0K
Realanime
RealAnime - Detailed V1は、Stable DiffusionベースのLoRAモデルで、リアルなアニメスタイルの画像生成に特化しています。深層学習技術により、高品質なアニメ風の人物画像を生成し、アニメ愛好家やプロのイラストレーターのニーズに応えます。アニメスタイル画像の生成効率と品質を大幅に向上させ、アニメ業界に強力な技術サポートを提供することが重要です。現在、Tensor.Artプラットフォームで提供されており、オンラインで利用でき、ダウンロードやインストールは不要で、手軽に利用できます。料金については、Buffetプランを購入することでダウンロード権限をアンロックし、より柔軟な使用方法を楽しむことができます。
AI画像生成
69.0K
FLUX.1 Dev Controlnet Canny Alpha
FLUX.1-dev-Controlnet-Canny-alphaは、Stable Diffusionシリーズに属する制御ネットワークベースの画像生成モデルです。高度なDiffusers技術を用いて、テキストから画像への変換により、高品質な画像生成サービスを提供します。特に、画像の細部とスタイルを正確に制御する必要があるシナリオに適しています。
AI画像生成
64.9K
Flux RealismLoRA
flux-RealismLoRAは、XLabs AIチームによって公開されたFLUX.1-devモデルに基づくLoRA技術で、リアルな画像を生成するために使用されます。テキストプロンプトから画像を生成し、アニメスタイル、ファンタジー、自然映画風など、様々なスタイルに対応しています。XLabs AIは、ユーザーがモデルのトレーニングと使用を容易に行えるよう、トレーニングスクリプトと設定ファイルを提供しています。
AI画像生成
63.5K
海外精選

Amuse
Amuse 2.0 Betaは、AMDが提供するデスクトップクライアントソフトウェアです。AMD Ryzen? AI 300シリーズプロセッサとRadeon? RX 7000シリーズグラフィックカードユーザー向けに設計されており、AI画像生成と最適化の体験を提供します。Stable DiffusionモデルとAMD XDNA?超解像度技術を組み合わせることで、複雑なインストールや設定なしに、高品質なAI画像生成を実現します。
画像生成
88.3K
海外精選
Stability Matrix
Stability Matrixは、Stable Diffusionによる画像生成プロセスを簡素化することを目的とした、ユーザーフレンドリーなデスクトップクライアントです。ワンクリックインストールとシームレスなモデル統合により、高度な技術知識がなくても、ユーザーは簡単に画像を管理および生成できます。このツールは複数のオペレーティングシステムに対応しており、モデルリソースを効率的に管理することで、ユーザーの学習曲線を軽減します。Stability Matrixは安定性と柔軟性を提供し、特に画像クリエイター、デザイナー、デジタルアーティストに最適です。
画像生成
75.6K
海外精選
Tensor.art
Tensor.Artは、無料で利用できるオンライン画像生成器およびモデルホスティングプラットフォームです。様々なAIツールと機能を提供しており、テキストによる画像生成や、AIモデルのカスタマイズ、微調整をサポートしています。高度なStable Diffusion技術を基盤としており、複数のノードとワークフローの複雑な組み合わせにも対応できるため、初心者からプロのデザイナーまで幅広いニーズに対応可能です。
画像生成
71.8K
Asyncdiff
AsyncDiffは、ノイズ予測モデルを複数のコンポーネントに分割し、異なるデバイスに割り当てることで、拡散モデルの並列処理を実現する非同期ノイズ除去による高速化ソリューションです。この手法により、推論遅延を大幅に削減しつつ、生成品質への影響を最小限に抑えます。AsyncDiffは、Stable Diffusion 2.1、Stable Diffusion 1.5、Stable Diffusion x4 Upscaler、Stable Diffusion XL 1.0、ControlNet、Stable Video Diffusion、AnimateDiffなど、複数の拡散モデルをサポートしています。
AI画像生成
49.1K
Easysdxlwebui
EasySdxlWebUiはオープンソースプロジェクトであり、SdxlWebUiのインストールと使用プロセスを簡素化することを目的としています。これにより、ユーザーはStable Diffusion web UIやforgeなどのツールを用いて、より簡単に画像を生成できます。本プロジェクトは複数の拡張機能に対応しており、Webインターフェースからパラメーター設定や画像生成を行うことができます。また、カスタムインストールや自動インストールにも対応しており、迅速な導入と効率的な画像生成が必要なユーザーに最適です。
AI画像生成
62.7K
一貫性のあるキャラクター
cog-consistent-characterは、AIによる画像生成モデルです。ユーザーは、指定したキャラクターの様々なポーズの画像を作成できます。Stable Diffusion技術を活用し、ComfyUIを通じてユーザーフレンドリーなインターフェースを提供することで、プログラミングの知識がないユーザーでも高品質な画像を簡単に生成できます。
AI画像生成
66.5K

Https
ComfyFlowは、ComfyUIベースのワークフローアプリ作成プラットフォームです。ワークフローアプリを迅速に作成し、他の人と共有できます。Stable DiffusionとComfyUI技術を用いて構築されており、シンプルで使いやすく、完全にホストされ、無料で利用できます。
開発とツール
48.9K
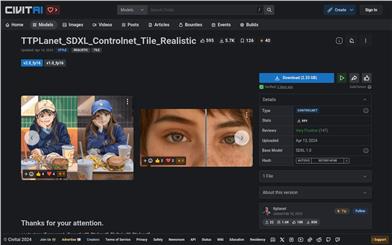
Ttplanet SDXL ControlNet Tile Realistic
これはSDXLベースのControlNet Tileモデルで、Hugging Face Diffusersのトレーニングセットを使用して訓練されました。Stable Diffusion SDXL ControlNetに対応しています。元々は、私自身のリアルなモデルのトレーニングのために、究極のアップスケーリングプロセスで画像の詳細を向上させるために作成されました。適切なワークフローを使用することで、高詳細で高解像度の画像修復に良好な結果を提供します。ほとんどのオープンソースにSDXL Tileモデルがないため、このモデルを共有することにしました。このモデルは、高解像度修復、スタイル転送、画像修復などの機能をサポートし、高品質の画像処理体験を提供します。
AI画像生成
102.1K
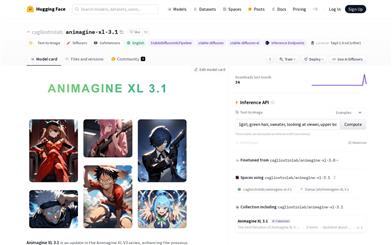
Animagine XL 3.1
Animagine XL 3.1は、テキストプロンプトに基づいて高品質なアニメスタイルの画像を生成するテキストツーイメージ生成モデルです。Stable Diffusion XLをベースに構築されており、アニメスタイルに特化して最適化されています。より広範なアニメキャラクターに関する知識、最適化されたデータセット、新しい美的タグを備えているため、生成される画像の品質と精度が向上しています。アニメ愛好家、アーティスト、コンテンツクリエイターにとって貴重なリソースとなることを目指しています。
AI動画画像生成
242.1K
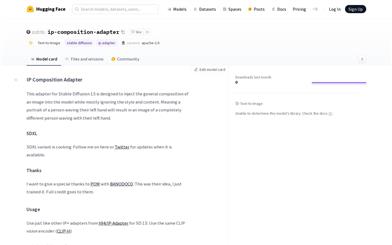
Ip Composition Adapter
このアダプターはStable Diffusion 1.5向けに設計されており、一般的な画像の構成をモデルに注入するために使用されます。スタイルやコンテンツの大部分は無視されます。例えば、手を振る人物の肖像画から、全く異なる人物が手を振っている画像が生成されます。このアダプターの利点は、Control Netsのように制御画像に厳密に一致する必要がないため、より柔軟な制御が可能になることです。POM with BANODOCOによって構想され、ostrisによってトレーニングおよび公開されました。
AI画像生成
147.1K
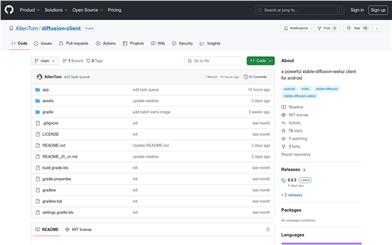
Diffusion Client
diffusion-clientは、Android向けのStable Diffusionクライアントです。テキストから画像生成、画像から画像生成、画像修復など、強力な画像生成機能を提供します。様々なモデルに対応し、制御ネットによる生成効果の調整も可能です。さらに、履歴管理、タグ抽出などの高度な機能を搭載しており、Civitaiなどのモデルへの接続を可能にする拡張プラグインにも対応しています。
AI画像生成
423.1K
Creative Upscaler
Creative Upscalerは、AIを活用した画像生成ツールです。誰でも簡単に、高品質の芸術作品を迅速に作成できます。Stable Diffusion、DALL-E 2、VQGAN+CLIPなど、複数の最先端機械学習アルゴリズムを統合しており、様々なスタイルの画像生成に対応しています。ユーザーはテキストによる説明を入力するだけで、Creative Upscalerが自動的に画像を生成します。さらに、低解像度の画像を高解像度画像に変換するクリエイティブな画像アップスケーラー機能も備えています。Creative Upscalerは完全に無料で使用でき、活気のある大規模なコミュニティも擁しており、AIアートを探求するのに最適な選択肢です。
画像生成
274.1K
Stable Diffusion WebUI Forge
Stable Diffusion WebUI Forgeは、Stable Diffusion WebUIとGradioを用いて開発されており、リソース管理の最適化と推論速度の向上を目指しています。1024px解像度でのSDXL推論において、オリジナルのWebUIと比較して30~75%の速度向上を実現し、最大解像度は2~3倍、最大バッチサイズは4~6倍に向上しています。ForgeはオリジナルWebUIの全機能を維持しつつ、DDPM、DPM++、LCMなどのサンプラーを追加し、Free U、SVD、Zero123などのアルゴリズムに対応しています。ForgeのUNet Patcherを使用することで、開発者は最小限のコードでアルゴリズムを実装できます。さらに、制御ネットワークの使用を最適化し、真のゼロメモリ占有での呼び出しを実現しています。
AI画像生成
797.9K
Stable Cascade
Stable Cascadeは、Würstchenアーキテクチャに基づくテキストツーイメージ生成モデルです。他のモデルと比べて、より小さな潜在空間を用いて訓練と推論を行うため、訓練と推論速度が大幅に向上しています。このモデルは一般消費者向けハードウェアで動作するため、使用障壁が低くなっています。Stable Cascadeは、ヒューマンエバリュエーションにおいて、プロンプトの一致性と画像品質の両方で他のモデルを上回っています。総じて、効率的で使いやすく、高性能なテキストツーイメージAIモデルです。
AI画像生成
156.5K
太乙扩散XL
Taiyi-Diffusion-XLは、Stable Diffusionを基に訓練されたオープンソースのバイリンガルテキストツーイメージ生成モデルです。英語と中国語のテキストによる画像生成に対応しており、以前の中国語テキストツーイメージモデルと比べて大幅な性能向上を実現しています。テキストの説明に基づいて写真のように写実的な画像を生成でき、様々な画像スタイルに対応し、高い生成品質と多様性を備えています。本モデルは革新的な訓練方法を採用し、単語表と位置符号を拡張することで長文と中国語に対応させ、大規模バイリンガルデータセットで訓練することで、強力な中国語と英語の生成能力を確保しています。
AI画像生成
117.0K

Comfy Textures
Comfy TexturesはUnreal Engineプラグインで、エディタとComfyUIを統合し、生成拡散モデルを使用してシーンのテクスチャを迅速に作成?調整できます。シングルビューとマルチビューのテクスチャ投影に対応し、パースペクティブカメラとオーソグラフィックカメラの両方に使用可能です。テクスチャ編集や画像から画像へのワークフローにも対応しています。Unreal Engine 5.xおよび4.xでシームレスに動作します。
AI画像生成
87.8K
AI万華鏡
AI万華鏡は、GPT、Stable Diffusion、AIペイントなどのオンラインAIツールを網羅したAIクリエイティブプラットフォームです。クリエイターはこれらのツールを無料で使用して、創造的な素材を生成できます。無料版と有料版があり、有料ユーザーはGPUアクセラレーションや利用回数の増加などのサービスを利用できます。本プラットフォームは、高品質で便利なAI創作ツールを提供し、クリエイターの作業効率向上を支援することを目指しています。
AI設計ツール
300.8K
Flush AI
Flush AIは、エンドツーエンドのAIアート制作クラウドスタジオです。Stable Diffusionモデルのホスティング、モデルファインチューニング、マルチモーダルワークフロー構築などの機能を提供し、ユーザーはGPU構成を気にすることなく、簡単にAIアート作品を作成できます。無料トライアルをご利用いただけ、必要に応じて価格プランを選択できます。柔軟かつ迅速にAI制作を進められます。
AI設計ツール
86.9K

Diffusionlight
DiffusionLightは、単一の入力画像から拡散モデルを用いて照明効果を推定する技術です。訓練済みのStable Diffusion XLモデルを使用して鏡面反射球を描画し、それを展開することでパノラマ照明図を得ます。本技術は、既存のニューラルネットワークベースの方法が限られたHDRパノラマデータセットに依存するため、現実世界における複雑なシーンで効果が不十分となる問題を解決します。主要な革新としては、拡散ノイズマップと鏡面反射球の生成品質間の関係を発見し、高品質な鏡面反射球を反復的に生成すること、そしてLoRAを用いた多重露光学習により、LDRモデルでもHDRフォーマットの出力が可能になった点が挙げられます。本技術はリアルな照明推定を生成し、特に屋外シーンに適しています。
AI画像生成
70.4K
- 1
- 2
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M