%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Stable Diffusion
Lanpaint
LanPaint is an image inpainting plugin for stable diffusion models. Through multiple rounds of iterative inference, it can achieve high-quality image inpainting without additional training. The importance of this technology lies in its provision of a solution that allows users to obtain accurate inpainting results without complex training, greatly reducing the barrier to entry. LanPaint is suitable for any stable diffusion model, including user-defined models, and has wide applicability and flexibility. It is mainly aimed at creators and developers who need high-quality image inpainting, especially those who want to get quick inpainting results without additional training.
Image Editing
56.6K
Animagine XL 4.0
Animagine XL 4.0 is an anime-themed generation model fine-tuned from Stable Diffusion XL 1.0. It has been trained on 8.4 million diverse anime-style images for a total of 2650 hours. The model focuses on generating and modifying anime-themed images based on text prompts, supporting various special tags to control different aspects of image generation. Its main advantages include high-quality image generation, rich anime style details, and precise restoration of specific characters and styles. The model was developed by Cagliostro Research Lab and is licensed under CreativeML Open RAIL++-M, allowing for commercial use and modification.
Image Generation
71.8K
Tryoffdiff
TryOffDiff is a high-fidelity garment reconstruction technology that generates standardized garment images from a single photo of an individual wearing clothing. Unlike traditional virtual try-ons, this technology aims to extract normative garment images, which poses unique challenges in capturing garment shape, texture, and complex patterns. TryOffDiff ensures high fidelity and detail retention by utilizing Stable Diffusion and SigLIP-based visual conditions. Experiments on the VITON-HD dataset demonstrate that its approach outperforms baseline methods based on pose transfer and virtual try-on while requiring fewer preprocessing and postprocessing steps. TryOffDiff not only enhances the quality of e-commerce product images but also advances the evaluation of generative models and inspires future work in high-fidelity reconstruction.
AI design tools
75.1K
SD3.5 Large IP Adapter
The SD3.5-Large-IP-Adapter is an IP adapter developed by the InstantX Team, based on the Stable Diffusion 3.5 Large model. This model analogizes image processing to text processing, boasting strong image generation capabilities and the potential for enhanced quality and effects through adapter technology. Its significance lies in promoting the advancement of image generation technology, particularly in creative work and artistic expression. Background information indicates that the model is a sponsored project by Hugging Face and fal.ai, adhering to the stabilityai-ai-community licensing agreement.
AI Models
75.1K
Bharatdiffusion
BharatDiffusion is an AI-based image generation model specifically fine-tuned to capture the diverse landscapes, cultures, and heritage of India, capable of producing high-quality images that reflect India's rich cultural tapestry. This model employs Stable Diffusion technology for all image generation, ensuring that the content resonates with the diversity and vibrancy of India.
Image Generation
56.6K
Sd Ppp
sd-ppp is a plugin that allows users to communicate between Adobe Photoshop and various Stable Diffusion interfaces such as SD/SDForge/ComfyUI. It supports multi-layer operations, including text and image layers, allows for handling multiple documents and instances of Photoshop, and enables work in specific areas of documents. This plugin is a powerful tool for designers and artists as it streamlines workflows, enhances creative efficiency, and allows them to leverage the robust capabilities of Stable Diffusion to enrich their design and artistic endeavors.
Stable Diffusion
125.9K
Comfyui Object Migration
Comfyui_Object_Migration is an experimental project focused on the Stable Diffusion (SD) model. This project achieves high consistency of the same object or character in a single generated image through the self-attention abilities of the DIT model. It has developed an efficient migration method by simplifying preprocessing logic, enabling the model to focus on the desired content and providing remarkable consistency. A migration model for clothing has been developed, allowing transitions from cartoon-style clothing to real-world styles or vice versa, stimulating design creativity through weight control.
DIT model
50.0K
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Light is an AI model for text-to-image generation that utilizes LoRA (Low-Rank Adaptation) technology. This model can generate high-quality images based on user-provided text prompts, achieving efficient model fine-tuning at a lower computational cost while maintaining diversity and quality in generated images. It is based on the Stable Diffusion 3.5 Large model and has been optimized to meet specific image generation requirements.
Image Generation
63.5K
Realanime
RealAnime - Detailed V1 is a LoRA model based on Stable Diffusion, specifically designed to produce realistic anime-style images. Utilizing advanced deep learning technology, it can understand and generate high-quality anime character images, catering to the needs of both anime fans and professional illustrators. Its significance lies in greatly enhancing the efficiency and quality of anime image generation, providing robust technical support for the anime industry. Currently, this model is available on the Tensor.Art platform, allowing users to utilize it online without the need for installation. Pricing permits users to unlock download rights through the Buffet plan, offering a more flexible usage option.
AI image generation
80.0K
FLUX.1 Dev Controlnet Canny Alpha
FLUX.1-dev-Controlnet-Canny-alpha is an image generation model based on control networks, belonging to the Stable Diffusion series. It utilizes advanced Diffusers technology to provide users with high-quality image generation services through text-to-image conversion. This model is particularly suitable for scenarios that require precise control over image details and styles.
AI image generation
70.7K
Flux RealismLora
flux-RealismLora, developed by the XLabs AI team, utilizes LoRA technology based on the FLUX.1-dev model to generate realistic images. This technology generates images from text prompts and supports various styles, including animation, fantasy, and natural cinema styles. XLabs AI provides training scripts and configuration files to facilitate model training and usage.
AI image generation
65.1K
English Picks

Amuse
Amuse 2.0 Beta is a desktop client software launched by AMD, designed specifically for users of AMD Ryzen? AI 300 series processors and Radeon? RX 7000 series graphics cards. It offers an AI image generation and optimization experience that combines the Stable Diffusion model with AMD XDNA? super-resolution technology, enabling high-quality AI image generation without complex installation or configuration.
Image Generation
105.4K
English Picks
Stability Matrix
Stability Matrix is a user-friendly desktop client designed to simplify the image generation process of Stable Diffusion. It helps users easily manage and generate images through one-click installation and seamless model integration, eliminating the need for in-depth technical knowledge. The tool supports multiple operating systems and effectively manages model resources, reducing the user’s learning curve. Stability Matrix offers stability and flexibility, making it especially suitable for image creators, designers, and digital artists.
Image Generation
78.4K
English Picks
Tensor.art
Tensor.Art is a free online image generation and model hosting platform that offers a variety of AI tools and functionalities. It enables users to generate images from text descriptions and customize and fine-tune AI models. Powered by advanced Stable Diffusion technology, the platform supports diverse node and workflow combinations, catering to the needs of users ranging from beginners to professional designers.
Image Generation
138.0K
Asyncdiff
AsyncDiff is a method for accelerating diffusion models through asynchronous denoising parallelization. It divides the noise prediction model into multiple components and distributes them across different devices, enabling parallel processing. This approach significantly reduces inference latency while having a minimal impact on generation quality. AsyncDiff supports a variety of diffusion models, including Stable Diffusion 2.1, Stable Diffusion 1.5, Stable Diffusion x4 Upscaler, Stable Diffusion XL 1.0, ControlNet, Stable Video Diffusion, and AnimateDiff.
AI image generation
51.9K
Easysdxlwebui
EasySdxlWebUi is an open-source project aimed at simplifying the installation and usage of SdxlWebUi, enabling users to more easily leverage tools like Stable Diffusion web UI and forge for image generation. The project supports multiple extended functionalities, allowing users to configure parameters and generate images through a web interface. It also supports customized and automated installation, making it suitable for users who need to quickly get started and efficiently generate images.
AI image generation
61.0K
Consistent Character
cog-consistent-character is an AI-powered image generation model that lets users create images of a given character in various poses. Leveraging Stable Diffusion technology and offering a user-friendly interface through ComfyUI, it enables even those without programming experience to easily generate high-quality images.
AI image generation
79.2K
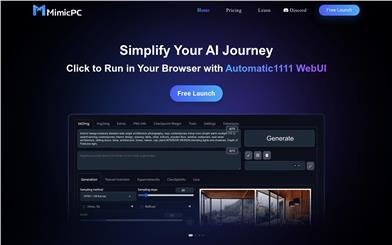
Mimicpc
MimicPC is a platform that runs on any device and browser, giving you access to and the ability to use popular open-source AI applications from around the world without the need for expensive hardware or technical knowledge of installation and maintenance.
AI information platform
56.3K

Https
ComfyFlow is a workflow application creation platform built on top of ComfyUI, enabling you to quickly build and share workflow applications with others. Leveraging the power of Stable Diffusion and ComfyUI technology, it offers simplicity, full hosting, and free usage.
Development & Tools
50.8K
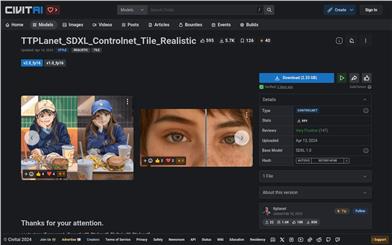
Ttplanet SDXL Controlnet Tile Realistic
This is a SDXL-based ControlNet Tile model trained on the Hugging Face Diffusers dataset and is compatible with Stable Diffusion SDXL ControlNet. It was initially developed for my own realistic model training, used in the ultimate upscaling process to enhance image details. With the right workflow, it can provide good results for high-detail, high-resolution image repair. As most open-source models lack SDXL Tile models, I decided to share this one. This model supports high-resolution repair, style transfer, and image enhancement functions, providing you with a high-quality image processing experience.
AI Image Generation
102.4K
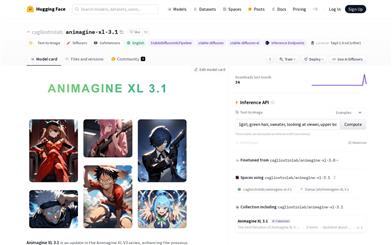
Animagine XL 3.1
Animagine XL 3.1 is a text-to-image generation model capable of producing high-quality anime-style images from text prompts. Built upon the foundation of Stable Diffusion XL, it has been specifically optimized for anime aesthetics. The model boasts an expanded knowledge base of anime characters, an optimized dataset, and new aesthetic tags, resulting in improved image quality and accuracy. It aims to provide a valuable resource for anime enthusiasts, artists, and content creators.
AI dynamic image generation
243.7K
Ip Composition Adapter
This adapter is designed for Stable Diffusion 1.5 to inject general image compositions into the model while largely ignoring style and content. For example, a portrait of a person raising their hand will generate an image of a completely different person raising their hand. The advantage of this adapter is that it allows for more flexible control, unlike Control Nets, which strictly match the control image. The product was conceived by POM with BANODOCO, trained by ostris, and released by them.
AI image generation
151.5K
Diffusion Client
The diffusion-client is an Android client for Stable Diffusion, offering robust image generation capabilities including text-to-image, image-to-image, and image repair features. The app supports various models and includes controls for fine-tuning the generation effects. Additionally, it features advanced functions such as history record management and tag extraction, and supports expansion plugins that can connect to models like Civitai.
AI image generation
423.7K
Creative Upscaler
Creative Upscaler is an AI-based image generator that allows anyone to quickly and easily create high-quality artworks. It integrates a variety of cutting-edge machine learning algorithms such as Stable Diffusion, DALL-E 2, VQGAN+CLIP, and supports generating images in various styles. Users simply provide a text description, and Creative Upscaler can automatically generate the images. Additionally, it features a Creative Image Aerator, which can convert low-resolution images into high-definition images. Creative Upscaler is completely free to use, boasts a large and active community, and is the best choice for exploring AI art.
Image Generation
284.8K
Diffusionhub
DiffusionHub is a stable Diffusion cloud platform that enables users to easily launch instances, store generation results, and create without the need for a GPU. Explore Automatic1111, Comfy, and Kohya for a seamless creative experience.
AI Model
50.8K
Stable Diffusion WebUI Forge
Stable Diffusion WebUI Forge, developed with Stable Diffusion WebUI and Gradio, aims to optimize resource management and accelerate inference. Compared to the original WebUI, Forge can boost SDXL inference speed by 30-75% at 1024px resolution, increase the maximum resolution by 2-3 times, and enlarge the maximum batch size by 4-6 times. Forge retains all the functionalities of the original WebUI while adding samplers like DDPM, DPM++, and LCM, enabling algorithms such as Free U, SVD, and Zero123. Its UNet Patcher allows developers to implement algorithms with minimal code. Forge also optimizes control network usage, achieving true zero-memory occupancy calls.
AI image generation
805.4K
Stable Cascade
Stable Cascade is a text-to-image generation model based on the Würstchen architecture. Compared to other models, it uses a smaller latent space for training and inference, resulting in significant improvements in both training and inference speed. The model can run on consumer-grade hardware, lowering the barrier to entry. Stable Cascade has shown outstanding performance in human evaluations, outperforming other models in both prompt alignment and image quality. Overall, it is an efficient, user-friendly, and powerful text-to-image AI model.
AI image generation
159.0K
Segmoe
SegMoE is a powerful framework that can dynamically combine Stable Diffusion models into expert mixtures within minutes, without requiring any training. It enables the instant creation of larger models, providing more knowledge, better adherence, and improved image quality. Inspired by mergekit's mixtral branch, SegMoE is specifically designed for Stable Diffusion models. It is easy to install and use, making it ideal for image generation and synthesis tasks.
AI image generation
104.1K
Taiyi Diffusion XL
Taiyi-Diffusion-XL is an open-source text-to-image generation model based on the Stable Diffusion framework, supporting both English and Chinese text-to-image generation. It represents a significant advancement over previous Chinese text-to-image models. The model can generate photo-realistic images based on textual descriptions, supports various image styles, and boasts high quality and diversity in generated images. It adopts an innovative training approach, extends vocabulary and position encoding to support long texts and Chinese, and is trained on large-scale bilingual datasets, ensuring its robust English and Chinese generation capabilities.
AI image generation
120.1K

Comfy Textures
Comfy Textures is a Unreal Engine plugin that integrates the editor with ComfyUI, allowing for the quick creation and adjustment of scene textures using generative diffusion models. Supports single-viewpoint and multi-viewpoint texture projection and is suitable for both perspective and orthographic cameras. It also offers texture editing and image-to-image workflows. It can seamlessly work with Unreal Engine versions 5.x and 4.x.
AI image generation
102.4K
- 1
- 2
- 3
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.2K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.0K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.7K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.2K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M