%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Animagine XL 4.0
Animagine XL 4.0 是一款基于Stable Diffusion XL 1.0微调的动漫主题生成模型。它使用了840万张多样化的动漫风格图像进行训练,训练时长达到2650小时。该模型专注于通过文本提示生成和修改动漫主题图像,支持多种特殊标签,可控制图像生成的不同方面。其主要优点包括高质量的图像生成、丰富的动漫风格细节以及对特定角色和风格的精准还原。该模型由Cagliostro Research Lab开发,采用CreativeML Open RAIL++-M许可证,允许商业使用和修改。
图片生成
94.1K
Latentsync
LatentSync 是由字节跳动开发的一款基于音频条件的潜在扩散模型的唇部同步框架。它能够直接利用 Stable Diffusion 的强大能力,无需任何中间运动表示,即可建模复杂的音视频关联。该框架通过提出的时间表示对齐(TREPA)技术,有效提升了生成视频帧的时间一致性,同时保持了唇部同步的准确性。该技术在视频制作、虚拟主播、动画制作等领域具有重要应用价值,能够显著提高制作效率,降低人工成本,为用户带来更加逼真、自然的视听体验。LatentSync 的开源特性也使其能够被广泛应用于学术研究和工业实践,推动相关技术的发展和创新。
视频生成
62.4K
Tryoffdiff
TryOffDiff是一种基于扩散模型的高保真服装重建技术,用于从穿着个体的单张照片中生成标准化的服装图像。这项技术与传统的虚拟试穿不同,它旨在提取规范的服装图像,这在捕捉服装形状、纹理和复杂图案方面提出了独特的挑战。TryOffDiff通过使用Stable Diffusion和基于SigLIP的视觉条件来确保高保真度和细节保留。该技术在VITON-HD数据集上的实验表明,其方法优于基于姿态转移和虚拟试穿的基线方法,并且需要较少的预处理和后处理步骤。TryOffDiff不仅能够提升电子商务产品图像的质量,还能推进生成模型的评估,并激发未来在高保真重建方面的工作。
AI设计工具
100.5K
SD3.5 Large IP Adapter
SD3.5-Large-IP-Adapter是一个基于Stable Diffusion 3.5 Large模型的IP适配器,由InstantX Team研发。该模型能够将图像处理工作类比于文本处理,具有强大的图像生成能力,并且可以通过适配器技术进一步提升图像生成的质量和效果。该技术的重要性在于其能够推动图像生成技术的发展,特别是在创意工作和艺术创作领域。产品背景信息显示,该模型是由Hugging Face和fal.ai赞助的项目,并且遵循stabilityai-ai-community的许可协议。
AI模型
67.3K
Bharatdiffusion
BharatDiffusion是一个基于AI的图像生成模型,专门针对印度的多样化景观、文化和遗产进行微调,能够生成反映印度丰富文化和特色的高质量图像。该模型使用Stable Diffusion技术处理所有图像生成,确保内容与印度的多样性和活力相呼应。
图像生成
59.3K
Sd Ppp
sd-ppp是一个允许用户在Adobe Photoshop和各种Stable Diffusion界面(如SD/SDForge/ComfyUI)之间进行通信的插件。它支持多层操作,包括文本层和图像层,能够处理多个文档和多个Photoshop实例,并允许用户在文档的特定区域工作。该插件对于设计师和艺术家来说是一个强大的工具,因为它可以简化工作流程,提高创作效率,并允许他们利用Stable Diffusion的强大功能来增强他们的设计和艺术作品。
Stable Diffusion
214.7K
Comfyui Object Migration
Comfyui_Object_Migration是一个实验性项目,专注于Stable Diffusion (SD)模型。该项目通过使用DIT模型的自注意力能力,实现了在单次生成的图像中,同一对象或角色保持高度一致性。项目通过简化预处理逻辑,开发出了一种高效的迁移方法,能够引导模型关注所需内容,提供惊人的一致性。目前已开发出适用于服装的迁移模型,能够实现卡通服装到现实风格或现实服装到卡通风格的迁移,并通过权重控制激发设计创造力。
DIT模型
53.0K
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Light是一个基于文本到图像生成的AI模型,通过使用LoRA(Low-Rank Adaptation)技术,该模型能够根据用户提供的文本提示生成高质量的图像。这种技术的重要性在于它能够以较低的计算成本实现模型的微调,同时保持生成图像的多样性和质量。该模型基于Stable Diffusion 3.5 Large模型,并在此基础上进行了优化和调整,以适应特定的图像生成需求。
图片生成
69.3K
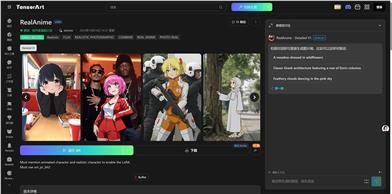
Realanime
RealAnime - Detailed V1 是一个基于Stable Diffusion的LoRA模型,专门用于生成逼真的动漫风格图像。该模型通过深度学习技术,能够理解并生成高质量的动漫人物图像,满足动漫爱好者和专业插画师的需求。它的重要性在于能够大幅度提高动漫风格图像的生成效率和质量,为动漫产业提供强大的技术支持。目前,该模型在Tensor.Art平台上提供,用户可以通过在线方式使用,无需下载安装,方便快捷。价格方面,用户可以通过购买Buffet计划来解锁下载权益,享受更灵活的使用方式。
AI图像生成
72.0K
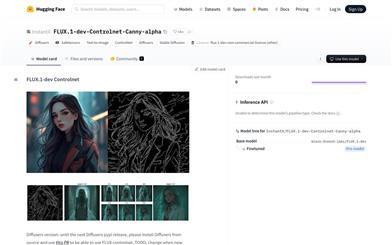
FLUX.1 Dev Controlnet Canny Alpha
FLUX.1-dev-Controlnet-Canny-alpha是一个基于控制网络的图像生成模型,属于Stable Diffusion系列。它使用先进的Diffusers技术,通过文本到图像的转换为用户提供高质量的图像生成服务。此模型特别适用于需要精确控制图像细节和风格的场景。
AI图像生成
75.9K
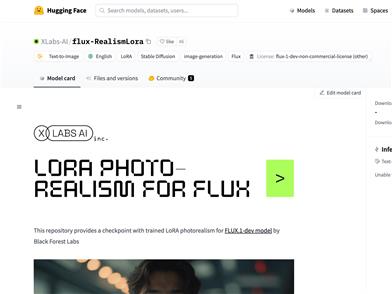
Flux RealismLora
flux-RealismLora是由XLabs AI团队发布的基于FLUX.1-dev模型的LoRA技术,用于生成逼真的图像。该技术通过文本提示生成图像,支持多种风格,如动画风格、幻想风格和自然电影风格。XLabs AI提供了训练脚本和配置文件,以方便用户进行模型训练和使用。
AI图像生成
67.1K
国外精选

Amuse
Amuse 2.0 Beta是一款由AMD推出的桌面客户端软件,专为AMD Ryzen™ AI 300系列处理器和Radeon™ RX 7000系列显卡用户设计,提供AI图像生成和优化体验。它结合了Stable Diffusion模型和AMD XDNA™超级分辨率技术,无需复杂安装和配置,即可实现高质量的AI图像生成。
图片生成
97.2K
国外精选
Stability Matrix
Stability Matrix 是一个用户友好的桌面客户端,旨在简化 Stable Diffusion 的图像生成过程。它通过一键安装和无缝的模型集成,帮助用户轻松管理和生成图像,无需深入的技术知识。该工具支持多种操作系统,并能有效管理模型资源,降低用户的学习曲线。Stability Matrix 提供稳定性和灵活性,特别适合图像创作者、设计师及数字艺术家使用。
图片生成
72.9K
国外精选
Tensor.art
Tensor.Art是一个免费的在线图像生成器和模型托管平台,提供多种AI工具和功能,支持用户通过文本描述生成图像,以及自定义和微调AI模型。平台背景强大,拥有先进的Stable Diffusion技术,支持多种节点和工作流的复杂组合,适用于从初学者到专业设计师的不同需求。
图片生成
83.1K
Easysdxlwebui
EasySdxlWebUi是一个开源项目,旨在简化SdxlWebUi的安装和使用过程,使得用户可以更加方便地利用Stable Diffusion web UI和forge等工具进行图像生成。项目支持多种扩展功能,允许用户通过web界面进行参数设置和图像生成,同时也支持自定义和自动化安装,适合需要快速上手和高效生成图像的用户。
AI图像生成
66.0K
Consistent Character
cog-consistent-character 是一个基于 AI 的图像生成模型,允许用户创建给定角色在不同姿势下的图像。它利用了 Stable Diffusion 技术,通过 ComfyUI 提供了一个用户友好的界面,使得即使是没有编程背景的用户也能轻松生成高质量的图像。
AI图像生成
72.0K
Ttplanet SDXL Controlnet Tile Realistic
这是一个基于SDXL的ControlNet Tile模型,使用Hugging Face Diffusers训练集,适用于Stable Diffusion SDXL ControlNet。它最初是为我自己的逼真模型训练,用于终极放大过程以提高图像细节。使用合适的工作流程,它可以为高细节、高分辨率的图像修复提供良好的结果。由于大多数开源没有SDXL Tile模型,我决定分享这个模型。该模型支持高分辨率修复、风格迁移和图像修复等功能,可以为你提供高质量的图像处理体验。
AI图像生成
110.1K
Ip Composition Adapter
该适配器为Stable Diffusion 1.5设计,用于将一般图像组合注入到模型中,同时大部分忽略风格和内容。例如一个人摆手的肖像会生成一个完全不同的人在摆手的图像。该适配器的优势是允许控制更加灵活,不像Control Nets那样会严格匹配控制图像。产品由POM with BANODOCO构思,ostris训练并发布。
AI图像生成
147.7K
Diffusion Client
diffusion-client是一个用于安卓的Stable Diffusion客户端。它提供了强大的图像生成能力,包括文本到图像、图像到图像、图像修复等功能。该APP支持多种模型,内置控制网调节生成效果。另外,该APP具有历史记录管理、标签提取等高级功能,同时支持扩展插件,可链接到Civitai等模型。
AI图像生成
452.1K
Creative Upscaler
Creative Upscaler是一个基于AI的图片生成器,可以让任何人快速轻松地创建高质量的艺术作品。它整合了多种前沿的机器学习算法,如Stable Diffusion、DALL-E 2、VQGAN+CLIP等,支持生成各种风格的图像。用户只需要提供文字描述,Creative Upscaler就可以自动生成图片。同时,它还有创造性的图像上样器功能,可以把低分辨率图片转换成高清大图。Creative Upscaler完全免费使用,拥有庞大活跃的社区,是探索AI艺术的最佳选择。
图片生成
287.0K
Stable Diffusion WebUI Forge
Stable Diffusion WebUI Forge基于Stable Diffusion WebUI和Gradio开发,旨在优化资源管理、加速推理。相比原版WebUI在1024px分辨率下的SDXL推理,Forge可提升30-75%的速度,最大分辨率提升2-3倍,最大batch size提升4-6倍。Forge保持了原版WebUI的所有功能,同时新增了DDPM、DPM++、LCM等采样器,实现了Free U、SVD、Zero123等算法。使用Forge的UNet Patcher,开发者可以用极少的代码实现算法。Forge还优化了控制网络的使用,实现真正的零内存占用调用。
AI图像生成
819.7K
Stable Cascade
Stable Cascade是一个基于Würstchen架构的文本到图像生成模型,相比其他模型使用更小的潜在空间进行训练和推理,因此在训练和推理速度上都有显著提升。该模型可以在消费级硬件上运行,降低了使用门槛。Stable Cascade在人类评估中表现突出,无论是在提示对齐还是图像质量上都超过了其他模型。总体而言,这是一个高效、易用、性能强劲的文生图AI模型。
AI图像生成
161.2K
Taiyi Diffusion XL
Taiyi-Diffusion-XL是一个开源的基于Stable Diffusion训练的双语文生图生成模型,支持英文和中文的文本到图像生成,相比之前的中文文生图模型有了显著提升。它可以根据文本描述生成照片般逼真的图像,支持多种图像风格,具有较高的生成质量和多样性。该模型采用创新的训练方式,扩展了词表、位置编码以支持长文本和中文,并在大规模双语数据集上进行训练,确保了其强大的中英文生成能力。
AI图像生成
126.4K

Comfy Textures
Comfy Textures是一个Unreal Engine插件,它将编辑器与ComfyUI集成,允许您使用生成式扩散模型快速创建和调整场景的纹理。支持单视点和多视点纹理投影,可以用于透视和正交摄像机。还支持纹理编辑和图像到图像工作流。可以无缝工作于Unreal Engine 5.x和4.x。
AI图像生成
94.9K
Flush AI
Flush AI是一个端到端的AI艺术创作云工作室,提供稳定扩散模型托管、模型微调、多模态工作流构建等功能,让用户无需关心GPU配置,即可轻松创建AI艺术作品。用户可以免费试用,并按需选择定价计划,灵活快速地进行AI创作。
AI设计工具
91.6K

Diffusionlight
DiffusionLight是一项利用扩散模型在单张输入图像中估算照明效果的技术。它利用训练好的Stable Diffusion XL模型绘制一个镜面反射球,然后将球体展开得到全景照明图。该技术解决了现有基于神经网络的方法依赖有限HDR全景数据集导致在真实复杂场景下效果不佳的问题。关键创新在于发现了扩散噪声图和镜面反射球生成质量之间的关系,迭代生成高质量镜面球;以及通过LoRA 进行多曝光训练,使LDR模型也可以输出HDR格式。该技术可产生逼真的照明估计,特别适用于野外场景。
AI图像生成
69.0K
Vibeprompts
VibePrompts是一个AI prompt在线交易平台。用户可以在这里购买和出售针对不同AI模型优化过的prompts,如Midjourney、Stable Diffusion等。平台提供了大量经过专业打磨的高质量prompts,能够帮助用户快速获得想要的创意结果。平台易于使用,提供直观的搜索和自定义功能,让prompt的选择和购买过程变得无缝而高效。VibePrompts已帮助大量用户实现创意目的,是提升项目质量的绝佳平台。
AI设计工具
54.4K
Sd4j
sd4j是一个使用ONNX Runtime的Stable Diffusion推理Java实现,以C#实现进行了优化移植,带有重复生成图像的图形界面,并支持负面文本输入。 旨在演示如何在Java中使用ONNX Runtime,以及获得良好性能的ONNX Runtime的最佳实践。 我们将使其与ONNX Runtime的最新版本保持同步,并随着通过ONNX Runtime Java API提供的性能相关ONNX Runtime功能的出现进行适当更新。 所有代码都可能会发生变化,因为这是一个代码示例,任何API都不应该被视为稳定的。
AI图像生成
57.1K
Aiemojigenerator
AI Emoji Generator利用Stable Diffusion的强大能力,将文本转化为独特的表情符号,这一创新工具免费供大家使用,支持任意文本输入快速创作个性化表情符号,一次点击即可轻松制作独特表情符号。它完美结合了科技和创造力,支持个性化表情符号的无障碍生产。无论是增强数字交流还是探索表情符号的艺术,AI Emoji Generator都开拓了创意表达的新可能。
图片生成
52.7K
NVIDIA FREE Stable Diffusion XL
Stable Diffusion XL(SDXL)是一个生成对抗网络模型,能够用更短的提示生成富有表现力的图像,并在图像中插入文字。它基于 Stability AI 开发的 Stable Diffusion 模型进行了改进,使图像生成更加高质量和可控,支持用自然语言进行本地化图像编辑。该模型可用于各种创意设计工作,如概念艺术、平面设计、视频特效等领域。
AI图像生成
66.2K
- 1
- 2
精选AI产品推荐
中文精选

Nocode
NoCode 是一款无需编程经验的平台,允许用户通过自然语言描述创意并快速生成应用,旨在降低开发门槛,让更多人能实现他们的创意。该平台提供实时预览和一键部署功能,非常适合非技术背景的用户,帮助他们将想法转化为现实。
开发平台
97.2K
优质新品

Listenhub
ListenHub 是一款轻量级的 AI 播客生成工具,支持中文和英语,基于前沿 AI 技术,能够快速生成用户感兴趣的播客内容。其主要优点包括自然对话和超真实人声效果,使得用户能够随时随地享受高品质的听觉体验。ListenHub 不仅提升了内容生成的速度,还兼容移动端,便于用户在不同场合使用。产品定位为高效的信息获取工具,适合广泛的听众需求。
音频生成
81.1K
国外精选

Lovart
Lovart 是一款革命性的 AI 设计代理,能够将创意提示转化为艺术作品,支持从故事板到品牌视觉的多种设计需求。其重要性在于打破传统设计流程,节省时间并提升创意灵感。Lovart 当前处于测试阶段,用户可加入等候名单,随时体验设计的乐趣。
AI设计工具
100.2K

Fastvlm
FastVLM 是一种高效的视觉编码模型,专为视觉语言模型设计。它通过创新的 FastViTHD 混合视觉编码器,减少了高分辨率图像的编码时间和输出的 token 数量,使得模型在速度和精度上表现出色。FastVLM 的主要定位是为开发者提供强大的视觉语言处理能力,适用于各种应用场景,尤其在需要快速响应的移动设备上表现优异。
AI模型
82.8K
国外精选

Smart PDFs
Smart PDFs 是一个在线工具,利用 AI 技术快速分析 PDF 文档,并生成简明扼要的总结。它适合需要快速获取文档要点的用户,如学生、研究人员和商务人士。该工具使用 Llama 3.3 模型,支持多种语言,是提高工作效率的理想选择,完全免费使用。
文章摘要
51.1K

Keysync
KeySync 是一个针对高分辨率视频的无泄漏唇同步框架。它解决了传统唇同步技术中的时间一致性问题,同时通过巧妙的遮罩策略处理表情泄漏和面部遮挡。KeySync 的优越性体现在其在唇重建和跨同步方面的先进成果,适用于自动配音等实际应用场景。
视频编辑
78.7K

Anyvoice
AnyVoice是一款领先的AI声音生成器,采用先进的深度学习模型,将文本转换为与人类无法区分的自然语音。其主要优点包括超真实的声音效果、多语言支持、快速生成能力以及语音定制功能。该产品适用于多种场景,如内容创作、教育、商业和娱乐制作等,旨在为用户提供高效、便捷的语音生成解决方案。目前产品提供免费试用,适合不同层次的用户。
音频生成
650.8K
中文精选

Liblibai
LiblibAI是一个中国领先的AI创作平台,提供强大的AI创作能力,帮助创作者实现创意。平台提供海量免费AI创作模型,用户可以搜索使用模型进行图像、文字、音频等创作。平台还支持用户训练自己的AI模型。平台定位于广大创作者用户,致力于创造条件普惠,服务创意产业,让每个人都享有创作的乐趣。
AI模型
8.0M