%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Flex.1 Alpha
Flex.1-alphaは、80億パラメータの修正流変換器アーキテクチャに基づく強力なテキストから画像生成モデルです。FLUX.1-schnellの特性を受け継ぎ、訓練済み埋め込みを使用することで、CFGなしで画像を生成できます。本モデルはファインチューニングに対応し、オープンソースライセンス(Apache 2.0)のため、DiffusersやComfyUIなど様々な推論エンジンで利用可能です。主な利点として、高品質な画像を効率的に生成できること、柔軟なファインチューニング機能、そしてオープンソースコミュニティによるサポートが挙げられます。開発背景としては、画像生成モデルの圧縮と最適化、そして継続的な訓練による性能向上を目指しています。
画像生成
65.1K
Llm Datasets
mlabonne/llm-datasets は、大規模言語モデル(LLM)のファインチューニングに焦点を当てた、高品質なデータセットとツールの集まりです。研究者や開発者向けに、厳選され最適化されたデータセットを提供し、言語モデルのトレーニングと最適化を支援します。主な利点として、データセットの多様性と高品質が挙げられ、様々な使用事例をカバーすることで、モデルの汎化能力と精度が向上します。さらに、データセットの理解と活用を支援するツールと概念も提供しています。背景としては、mlabonne氏によって作成?保守されており、LLM分野の発展を目指しています。
AIモデル
50.0K
海外精選

Tülu 3
Tülu 3は、より多くのタスクやユーザーに適応するためにファインチューニングされた、一連のオープンソースの先進的な言語モデルです。これらのモデルは、独自のメソッドの一部詳細、新規技術、そして確立された学術研究を組み合わせることで、複雑なトレーニングプロセスを実現しています。Tülu 3の成功は、綿密なデータ管理、厳格な実験、革新的な方法論、そして改良されたトレーニングインフラに根ざしています。データ、レシピ、そして発見を公開することで、Tülu 3はコミュニティに新たな革新的なファインチューニング手法を探求する能力を与えようとしています。
言語モデル
54.6K
Workflowllm
WorkflowLLMは、データ中心のフレームワークであり、大規模言語モデル(LLM)のワークフローオーケストレーション能力の強化を目指しています。その中核となるのはWorkflowBenchです。これは、83個のアプリケーション、28個のカテゴリ、1503個のAPIからなる106763個のサンプルを含む、大規模な教師あり微調整データセットです。WorkflowLLMは、Llama-3.1-8Bモデルを微調整することで、ワークフローオーケストレーションタスク向けに最適化されたWorkflowLlamaモデルを作成します。実験結果から、WorkflowLlamaは複雑なワークフローのオーケストレーションにおいて優れた性能を示し、未知のAPIへの汎化能力も高いことが明らかになっています。
ワークフローオーケストレーション
49.1K
Tablegpt2
TableGPT2は、表データに特化して事前トレーニングとファインチューニングされた大規模マルチモーダルモデルです。実用における表データの統合不足の問題を解決するために開発されました。593,800以上の表データと236万件の高品質クエリ?表?出力タプルを用いて、前例のない規模で事前トレーニングとファインチューニングが行われています。TableGPT2の重要な革新の一つは、パターンレベルとセルレベルの情報を捉えるように設計された新規の表エンコーダーです。これにより、曖昧なクエリ、列名の欠損、不規則な表の処理能力が向上しています。23個のベンチマーク指標において、7Bモデルで平均35.20%、72Bモデルで49.32%の性能向上を実現し、同時に強力な汎用言語処理能力とコーディング能力を維持しています。
AIモデル
70.7K
Phi 3.5 Mini Instruct
Phi-3.5-mini-instructは、Microsoftが高质量データに基づいて構築した、軽量で多言語対応の高度なテキスト生成モデルです。高品質な推論集約型データの提供に重点を置いており、128Kトークンのコンテキスト長をサポートします。教師あり微調整、近位策略最適化、直接選好最適化を含む厳格な強化プロセスを経ており、正確な指示に従うことと強力なセキュリティ対策を確保しています。
AIモデル
57.7K
Ragfoundry
RAGFoundryは、特別に作成されたRAG拡張データセットでモデルをファインチューニングすることにより、大規模言語モデル(LLM)の外部情報活用能力を向上させることを目的としたライブラリです。このライブラリは、パラメータ効率の良いファインチューニング(PEFT)により、ユーザーがモデルを簡単にトレーニングし、RAG固有の指標を使用して性能向上を測定できるようにします。モジュール化された設計になっており、ワークフローは設定ファイルでカスタマイズできます。
AI開発助手
46.4K
海外精選
Finetune
Finetuneは、開発者向けのAI知能エージェントのファインチューニングプラットフォームです。顧客特性を反映した合成ユーザーを作成することで、開発者の知能エージェントをシミュレーション環境でテストおよび学習させることができます。プラットフォームは、セッションレポートと重み付け実行グラフを提供し、開発者がエージェントのパフォーマンスを理解し、最適化することを支援します。さらに、Finetuneは、様々な一般的なAIモデルとフレームワークをサポートしているため、統合と展開のプロセスがより容易になります。
開発とツール
45.5K
LLMマスターコース
Mastering LLMsは、25名以上の業界ベテランが講師を務める無料コースです。評価、検索拡張生成(RAG)、ファインチューニングなどのトピックを網羅しています。情報検索、機械学習、レコメンデーションシステム、MLOps、データサイエンスなどの分野の専門家によって作成された本コースは、これらの分野の既存技術をLLMに適用し、ユーザーに実質的なメリットを提供することを目指しています。AI製品の改善方法の指導を必要とする技術担当者(エンジニアやデータサイエンティストを含む)を対象としています。
学習教育
47.5K
Lmms Finetune
lmms-finetuneは、大規模マルチモーダルモデル(LMMs)のファインチューニングプロセスを簡素化することを目的とした統一的なコードベースです。最新のLMMsを容易に統合し、ファインチューニングを行うための構造化されたフレームワークを提供します。フルファインチューニングやLoRAなどの戦略をサポートしています。コードベースはシンプルで軽量に設計されており、理解と変更が容易です。LLaVA-1.5、Phi-3-Vision、Qwen-VL-Chat、LLaVA-NeXT-Interleave、LLaVA-NeXT-Videoなど、様々なモデルをサポートしています。
AI開発助手
51.3K
Amchat
AMchatは、数学知識と高等数学习題とその解答を統合した大規模言語モデルです。InternLM2-Math-7Bモデルをベースに、xtunerを用いた微調整を行い、高等数学問題の解答に特化して設計されています。2024浦源大模型シリーズチャレンジ(春季賽)においてTop12と革新創意賞を受賞し、高等数学分野における専門性と革新性を証明しています。
AI数学助手
51.3K
Emollm
EmoLLMは、LLMをファインチューニングした心理健康大規模言語モデルです。個人、集団、そして社会全体の心理健康状態の理解と促進を目指しています。認知、感情、行動、社会環境、生理的健康、心理的レジリエンス、予防?介入策、評価?診断ツールなど、複数の重要な要素を包含しています。EmoLLMは、ファインチューニングされた設定により、心理相談タスクにおいてサポートを提供し、ユーザーが心理的問題をより良く理解し、対処するのに役立ちます。
AI心の健康
78.4K
高品質新製品
Lazyllm
LazyLLMは、人工知能アプリケーション構築プロセスを簡素化することに特化した開発ツールです。低コードソリューションを提供することで、大規模言語モデルの知識がなくても、複数のエージェントを含むAIアプリケーションを簡単に構築できます。LazyLLMは、ワンクリックで全てのモジュールをデプロイし、クロスプラットフォーム互換性、自動グリッドサーチによるパラメータ最適化、そして効率的なモデル微調整をサポートすることで、アプリケーションの効果を向上させます。
AI開発助手
55.2K
Higgs Llama 3 70B
Higgs-Llama-3-70Bは、Meta-Llama-3-70Bを基盤としたファインチューニングモデルです。ロールプレイングに特化して最適化されており、一般的な指示実行や推論においても高い競争力を維持しています。本モデルは、教師ありファインチューニングと、人間のアノテーターと独自の巨大言語モデルを用いて構築された選好ペアによる反復的選好最適化を通じて、モデルの挙動をシステムメッセージにより近づけ、整合性を高めています。他の指示型モデルと比較して、Higgsモデルは役割をより忠実に遵守します。
AI会話機械人間
81.7K
Mistral Finetune
mistral-finetuneは、LoRAトレーニングパラダイムに基づいた軽量コードライブラリです。大部分の重みを凍結したまま、追加の重みの1~2%のみを、低ランク行列摂動の形でファインチューニングできます。多GPU単一ノードのトレーニング設定に最適化されており、7Bモデルのような比較的小さいモデルであれば、単一のGPUでも十分です。このコードライブラリは、特にデータフォーマットに関して、シンプルで分かりやすいファインチューニングの入り口を提供することを目的としており、多様なモデルアーキテクチャやハードウェアタイプを網羅することを目的としていません。
AIモデル
48.3K
Llama Recipes
llama-recipesはMeta Llamaモデルの付随リポジトリであり、Meta Llamaモデルのファインチューニングのための拡張可能なライブラリを提供することを目的としています。いくつかのサンプルスクリプトとノートブックを提供することで、ドメイン適応型ファインチューニングやLLMベースのアプリケーション構築など、様々なユースケースにおいてモデルを迅速に使い始めることができます。
AIモデル
50.0K
![Llama-3[8B] Meditron V1.0](https://p1.chinaz.com/ai-2024-04-30-202404301629054000.jpg/392/259/W/jpg)
Llama 3[8B] Meditron V1.0
Llama-3[8B] Meditron V1.0は、生物医学分野向けに設計された8億パラメーターの大規模言語モデル(LLM)です。MetaがLlama-3を公開してから24時間以内にファインチューニングが完了しました。このモデルは、MedQAやMedMCQAなどの標準ベンチマークテストにおいて、同規模のパラメーターを持つ既存のオープンモデルをすべて上回り、700億パラメーターレベルの医学分野における最先端のオープンモデルであるLlama-2[70B]-Meditronの性能に匹敵する結果を示しました。この研究は、オープンな基礎モデルの革新的な可能性を示しており、資源の少ない地域におけるこの技術への公平なアクセスを確保するためのより大きな取り組みの一環です。
AIモデル
72.3K
オープンソース大規模言語モデル活用ガイド
本プロジェクトは、環境設定、モデル展開、効率的なファインチューニングなどを含む、オープンソース大規模言語モデルに関する包括的なガイドチュートリアルです。オープンソース大規模言語モデルの利用と応用を簡素化し、より多くの学習者がオープンソース大規模言語モデルを使用できるようにすることを目的としています。オープンソース大規模言語モデルに関心があり、自ら実践したい学習者を対象に、詳細な環境設定、モデル展開、ファインチューニングの方法を提供します。
AI教程
116.7K
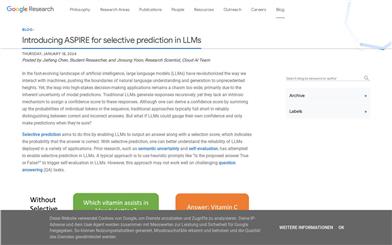
ASPIRE
ASPIREは、大規模言語モデル(LLM)の選択的予測能力を高めるために設計された洗練されたフレームワークです。パラメータ効率の良い微調整によってLLMに自己評価能力を持たせ、生成された回答に対する信頼度スコアを出力できるようにします。実験結果によると、ASPIREは様々な質問応答データセットにおいて、既存の選択的予測手法を大幅に上回ることが示されました。
AIモデル
44.4K
Reft
ReFTは、大規模言語モデル(LLM)の推論能力を強化するためのシンプルかつ効果的な手法です。まず、教師ありファインチューニング(SFT)によってモデルを事前学習させ、その後、オンライン強化学習、具体的には本稿で用いられているPPOアルゴリズムを用いて、モデルをさらに微調整します。ReFTは、与えられた問題に対して多数の推論経路を自動的にサンプリングし、正解から自然に報酬を導き出すことで、SFTを大幅に上回る性能を実現します。ReFTの性能は、推論時の戦略(多数決やランキング再評価など)を組み合わせることで、さらに向上させる可能性があります。注目すべき点は、ReFTは追加の、あるいは拡張された訓練データに依存することなく、SFTと同じ訓練問題を用いて改善を達成する点です。これは、ReFTがより強力な汎化能力を持つことを示唆しています。
AIモデル推論訓練
48.9K
Astraios
Astraiosは、大規模言語モデルのファインチューニングを提供するプラットフォームです。様々なパラメータ効率的なファインチューニング手法と、複数の規模のモデルを選択できます。ユーザーは本プラットフォーム上で大規模言語モデルのファインチューニングを行い、最適なコストパフォーマンスを実現できます。豊富なモデル、データセット、ドキュメントも提供しており、研究開発を容易にします。柔軟な価格設定により、様々な規模のユーザーニーズに対応可能です。
AIモデル
46.6K
中国語精選
Modihand
Modihandは、あなただけのテキスト大規模言語モデルをトレーニングできるプラットフォームです。専門知識は不要で、トレーニングデータさえ準備すれば、あなた専用のテキスト大規模言語モデルをトレーニングできます。市場に出回っているほとんどのオープンソースモデルを内蔵し、様々なファインチューニング方式に対応しています。コストパフォーマンスに優れ、独立してデプロイでき、推論APIをサポートしており、さらに充実したサポートを提供します。
モデルトレーニングとデプロイ
88.9K
Automorphic
Automorphicは、安全で自己改善型の言語モデルプラットフォームです。ファインチューニング技術を用いて知識を言語モデルに注入し、コンテキストウィンドウの制限を回避します。特定の動作や知識を実現するアダプターをトレーニングし、ランタイムで動的に組み合わせたり切り替えたりできます。同時に、Automorphicは人と機械のインタラクションによるフィードバックを提供し、モデルの迅速な反復と本番環境への展開を可能にします。また、Automorphic Hub上の公開モデルを使用して推論することもできます。
開発プラットフォーム
65.1K
ファインチューナーAI
ファインチューナーは、AIのパフォーマンスを最適化するノーコードのファインチューニングツールです。高度なファインチューニング技術を使用することで、より少ないデータと時間でより良い結果を得ることができます。ファインチューナーは、コードを記述することなく、NLPモデルのパフォーマンスを向上させるのに役立ちます。既存のモデルを改良し、パフォーマンスを最適化することで、時間とリソースを節約できます。ファインチューナーは、様々なシナリオに適した豊富な機能も提供しています。
AI開発助手
43.9K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
41.4K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.8K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.3K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.7K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.7K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M