%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Camerabench
CameraBenchは、ビデオ内のカメラの動きを分析するモデルであり、ビデオの解釈を通じてカメラの動きパターンを理解することを目指しています。その主な強みは、生成型の視覚言語モデルを使用してカメラの動きパターンを分類し、ビデオ-テキスト検索を行うことです。従来の方法である構造化運動(SfM)や同時位置姿勢推定(SLAM)と比較し、このモデルはシーンのセマンティックをよりよく捉えています。モデルはオープンソースであり、研究者や開発者向けに適しており、後日、さらなる改良版がリリースされます。
研究ツール
37.5K

Describe Anything
Describe Anythingモデル(DAM)は、画像または動画の特定の領域を処理し、詳細な記述を生成できます。主な利点は、単純なマーキング(点、枠、落書き、またはマスク)によって高品質の局所的な記述を生成できることであり、コンピュータビジョン分野における画像理解能力を大幅に向上させます。このモデルは、NVIDIAと複数の大学が共同で開発したもので、研究、開発、および実用アプリケーションに適しています。
家庭用品
38.1K

Easycontrol
EasyControlは、Diffusion Transformer(拡散変換器)に効率的で柔軟な制御を提供するフレームワークであり、現在のDiTエコシステムにおける効率のボトルネックやモデルの適合性の不足といった問題に対処することを目的としています。主な利点としては、様々な条件の組み合わせに対応、生成の柔軟性と推論効率の向上があります。本製品は最新の研究成果に基づいて開発されており、画像生成、スタイル変換などの分野で使用できます。
AIモデル
38.1K
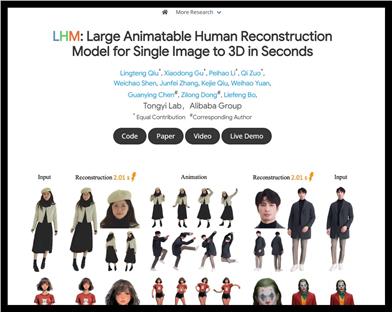
LHM
LHM(大規模アニメーション可能人間再構築モデル)は、マルチモーダル?トランスフォーマーアーキテクチャを利用して高精細な3Dアバターを再構築し、単一画像からアニメーション可能な3D人間像の生成をサポートします。本モデルは、衣服の形状とテクスチャを詳細に保持でき、特に顔の識別とディテールの復元において優れた性能を発揮し、3D再構築精度が高い要求されるアプリケーションシーンに適しています。
3Dモデリング
44.2K

Thera
Theraは、さまざまな尺度で高品質な画像を生成できる高度な超解像度技術です。主な利点として、物理的な観測モデルが組み込まれており、エイリアシング現象を効果的に回避できる点が挙げられます。この技術はETH Zurichの研究チームによって開発され、画像強調とコンピュータビジョン分野、特にリモートセンシングと測量で幅広く応用されています。
チャットボット
47.7K
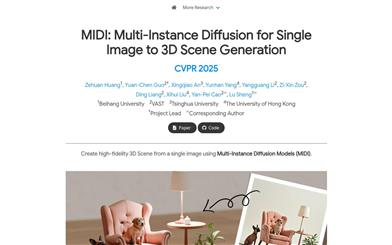
MIDI
MIDIは、多インスタンス拡散モデルを利用した革新的な画像から3Dシーン生成技術です。正確な空間関係を持つ複数の3Dインスタンスを、単一画像から直接生成できます。この技術の中核は多インスタンスアテンションメカニズムであり、複雑な複数ステップ処理を必要とせずに、物体間の相互作用と空間的一貫性を効果的に捉えることができます。MIDIは画像からシーン生成分野で優れた性能を示し、合成データ、現実世界のシーンデータ、そしてテキストから画像への拡散モデルによって生成されたスタイル化されたシーン画像に適しています。主な利点として、効率性、高忠実度、そして強力な汎化能力が挙げられます。
3Dモデリング
49.4K
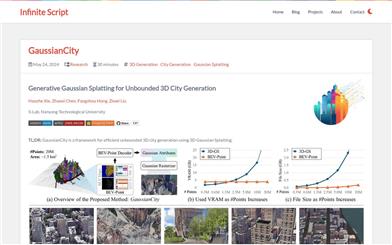
Gaussiancity
GaussianCityは、3Dガウス描画技術に基づいた、境界のない大規模な3D都市を効率的に生成することに特化したフレームワークです。この技術は、コンパクトな3Dシーン表現と空間認識型ガウス属性デコーダを通じて、従来の方法が大規模な都市景観を生成する際に直面するメモリと計算のボトルネックを解決します。主な利点として、単一の前方パスで高速に大規模な3D都市を生成できることがあり、既存技術を大幅に上回ります。本製品は南洋理工大学S-Labチームによって開発され、関連論文はCVPR 2025に掲載されています。コードとモデルはオープンソースであり、3D都市環境を効率的に生成する必要がある研究者や開発者向けです。
3Dモデリング
42.0K
Mlgym
MLGymは、MetaのGenAIチームとUCSB NLPチームによって開発された、AI研究エージェントの訓練と評価のためのオープンソースのフレームワークとベンチマークです。多様なAI研究タスクを提供することにより、強化学習アルゴリズムの発展を促進し、研究者が現実世界の研究シナリオにおいてモデルを訓練および評価するのに役立ちます。このフレームワークは、コンピュータビジョン、自然言語処理、強化学習など、複数のタスクをサポートしており、AI研究のための標準化されたテストプラットフォームを目指しています。
モデルトレーニングとデプロイメント
44.4K
Pippo
Pippoは、Meta Reality Labsと複数の大学が共同開発した生成モデルであり、一枚の普通の画像から高解像度の複数視点ビデオを生成できます。この技術の最大の強みは、追加の入力(パラメータ化モデルやカメラパラメータなど)なしで、高品質な1K解像度のビデオを生成できる点です。多視点拡散トランスフォーマーアーキテクチャに基づいており、仮想現実、映画制作など、幅広い応用が期待できます。Pippoのコードはオープンソースですが、事前学習済みウェイトは含まれておらず、ユーザーは自分でモデルをトレーニングする必要があります。
映像制作
66.5K

Videoworld
VideoWorldは、純粋な視覚入力(ラベルなし動画)から複雑な知識を学習することに特化した深層生成モデルです。自己回帰型動画生成技術を用いて、視覚情報のみからタスクルール、推論、計画能力を学習する方法を探求しています。本モデルの核心的な強みは、革新的な潜在動的モデル(LDM)であり、多段階の視覚変化を効率的に表現することで、学習効率と知識獲得能力を大幅に向上させます。VideoWorldは、囲碁動画やロボット制御タスクにおいて優れた性能を示し、その強力な汎化能力と複雑なタスクへの学習能力を実証しています。本モデルの研究背景は、生物が言語ではなく視覚を通して知識を学習することに着想を得ており、人工知能の知識獲得に新たな道を切り開くことを目指しています。
映像制作
54.6K
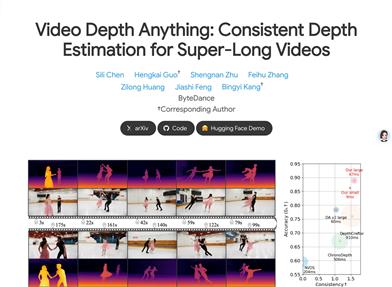
Video Depth Anything
Video Depth Anythingは、深層学習に基づく動画深度推定モデルであり、超長動画に対して高品質で時間的に一貫性のある深度推定を提供します。Depth Anything V2をベースに開発されており、強力な汎化能力と安定性を備えています。主な利点としては、任意の長さの動画への対応、時間的一貫性、そしてオープンワールド動画への優れた適応性などが挙げられます。本モデルは、バイトダンス(ByteDance)の研究チームによって開発され、時間的一貫性や複雑なシーンへの対応といった、長動画の深度推定における課題解決を目指しています。現在、コードとデモが公開されており、研究者や開発者が利用できます。
映像編集
46.4K
Vitpose
ViTPoseは、Transformerアーキテクチャに基づく人体姿勢推定モデル群です。Transformerの強力な特徴抽出能力を活用し、人体姿勢推定タスクに対してシンプルかつ効果的なベースラインを提供します。ViTPoseモデルは複数のデータセットで優れた性能を示し、高い精度と効率性を備えています。シドニー大学のコミュニティによって保守?更新されており、様々な規模のバージョンが提供され、多様なアプリケーションシナリオのニーズに対応します。Hugging Faceプラットフォーム上でオープンソースとして提供されており、ユーザーは容易にこれらのモデルをダウンロード?デプロイし、人体姿勢推定に関する研究やアプリケーション開発を行うことができます。
AIモデル
50.2K
Tryoffanyone
TryOffAnyonは、着用している人物から平面状の布地を生成する深層学習モデルです。このモデルは、衣服を着た人物の画像を布地の平面図に変換することができ、ファッションデザイン、バーチャル試着などに重要な意味を持ちます。深層学習技術を用いて、非常にリアルな布地のシミュレーションを実現し、ユーザーはより直感的に衣服の着用効果をプレビューできます。主な利点としては、リアルな布地シミュレーションと高い自動化度があり、実際の試着にかかる時間とコストを削減できます。
AI設計ツール
72.0K
Flagai
FlagAIは、北京智源人工智能研究院が提供する、高品質な一元化オープンソースプロジェクトです。世界中で広く利用されている様々な大規模言語モデルアルゴリズム技術と、複数の大規模言語モデルの並列処理およびトレーニング加速技術を統合しています。効率的なトレーニングと微調整をサポートし、大規模言語モデルの開発と応用のハードルを下げ、開発効率の向上を目指しています。FlagAIは、言語大規模モデルOPT、T5、ビジョン大規模モデルViT、Swin Transformer、マルチモーダル大規模モデルCLIPなど、複数の分野の代表的なモデルを網羅しています。「悟道2.0」「悟道3.0」大規模モデルプロジェクトの成果もFlagAIにオープンソース化されており、現在Linux Foundationに参加し、世界中の研究者による共同イノベーションと貢献を促進しています。
モデルトレーニングとデプロイ
48.3K
Video Analyzer
video-analyzerは、Llamaの11BビジョンモデルとOpenAIのWhisperモデルを組み合わせた動画分析ツールです。キーフレームを抽出し、ビジョンモデルに入力して詳細情報を取得し、各フレームの詳細情報と利用可能な転写内容を組み合わせることで、動画の内容を記述します。このツールは、コンピュータビジョン、音声転写、自然言語処理を統合し、動画コンテンツの詳細な説明を生成します。主な利点として、クラウドサービスやAPIキーを必要とせず完全にローカルで動作すること、動画からキーフレームをインテリジェントに抽出すること、OpenAIのWhisperを用いた高品質な音声転写、OllamaとLlama3.2 11Bビジョンモデルを用いたフレーム分析、自然言語による動画コンテンツの説明生成などが挙げられます。
映像編集
98.8K
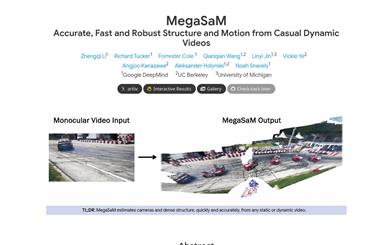
Megasam
MegaSaMは、動的シーンの単眼ビデオから、正確で、高速で、堅牢なカメラパラメータと深度マップの推定を可能にするシステムです。本システムは、入力ビデオが主に静的シーンと多くの視差を含むと仮定する従来のStructure from Motionや単眼SLAM技術の限界を突破します。MegaSaMは、深度ビジュアルSLAMフレームワークを綿密に改良することで、未知の視野角を持ち、カメラの移動経路に制限のないビデオを含む、現実世界の複雑な動的シーンのビデオにも対応できます。合成ビデオと実ビデオにおける広範な実験により、MegaSaMは、以前の研究や並行研究と比較して、カメラ姿勢と深度推定においてより正確で堅牢であり、実行時間も同等か、またはより高速であることが示されました。
3Dモデリング
50.8K
NVIDIA Jetson Orin Nano Super Developer Kit
NVIDIA Jetson Orin Nano Super Developer Kitは、コンパクトな生成AIスーパーコンピューターです。高い性能と低価格を実現しました。商業AI開発者からアマチュア、学生まで幅広いユーザー層をサポートし、生成AI推論性能を1.7倍、INT8 TOPS性能を67 TOPS(前世代比70%向上)、メモリ帯域幅を102GB/s(前世代比50%向上)に向上しています。検索強化型生成LLMチャットボットの開発、ビジュアルAIエージェントの構築、AIベースロボットの展開などに最適です。
開発とツール
48.0K
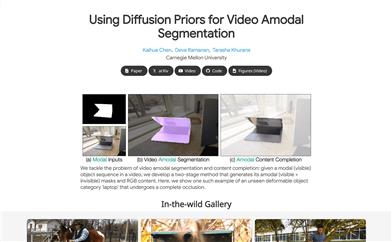
Diffusion Vas
カーネギーメロン大学が提案した、動画における非可視物体セグメンテーションとコンテンツ補完を行うモデルです。条件付き生成タスクの手法を用い、動画生成モデルの基礎知識を活用して、動画内の可視物体シーケンスを処理し、可視部分と非可視部分を含む物体のマスクとRGBコンテンツを生成します。本技術の主な利点としては、高度な遮蔽状況にも対応可能で、変形物体に対しても効果的な処理が可能な点が挙げられます。さらに、複数のデータセットにおいて既存の最先端手法を上回る性能を示しており、特に物体が遮蔽されている領域の非可視セグメンテーションにおいては、最大13%の性能向上を実現しています。
映像制作
44.4K
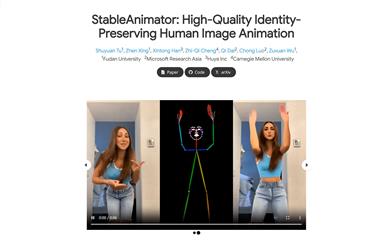
Stableanimator
StableAnimatorは、初のエンドツーエンドのアイデンティティ保持型ビデオ拡散フレームワークであり、後処理なしで高品質のビデオ合成が可能です。本技術は、参照画像と一連のポーズを条件として合成することにより、アイデンティティの一貫性を確保します。主な利点は、サードパーティ製のツールに依存する必要がなく、高品質の人物アニメーションを必要とするユーザーに最適であることです。
映像制作
63.2K

CHOIS
Controllable Human-Object Interaction Synthesis(CHOIS)は、言語記述、初期物体と人間の状態、疎な物体の経路点に基づいて、物体と人間の動きを同時に生成する高度な技術です。この技術は、特に正確な手と物体の接触や地面からの適切な支持が必要な場面において、現実的な人間の行動のシミュレーションに不可欠です。CHOISは、追加の監督情報として物体の幾何学的損失を導入し、サンプリング過程で接触制約を強制するための誘導項を設計することで、生成された物体の動きと入力された経路点のマッチング精度を向上させ、インタラクションの自然さを確保しています。
3Dモデリング
45.0K
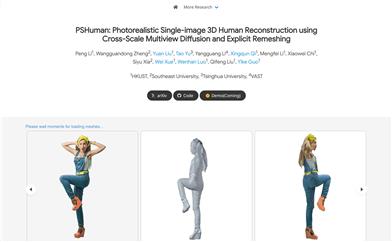
Pshuman
PSHumanは、多視点拡散モデルと明示的再構成技術を用いて、一枚の写真からリアルな3D人体モデルを再構築する革新的なフレームワークです。この技術は、複雑な自己遮蔽問題に対処し、生成された顔の詳細において幾何学的歪みを回避できる点が重要です。PSHumanは、クロススケール拡散モデルによってグローバルな全身形状とローカルな顔の特徴を統合的にモデル化することで、ディテールが豊富でアイデンティティの特徴を維持した新たな視点からの生成を実現します。さらに、SMPL-Xなどのパラメトリックモデルが提供するボディープライオリティによって、異なる人体姿勢でのクロスビューボディ形状の一貫性を強化しています。PSHumanの主な利点として、幾何学的ディテールの豊かさ、テクスチャの忠実度の高さ、および汎化能力の強さが挙げられます。
3Dモデル
69.0K
Text To Pose
text-to-poseは、テキスト記述から人物のポーズを生成し、そのポーズを用いて画像を生成することを目的とした研究プロジェクトです。自然言語処理とコンピュータビジョンの技術を融合し、拡散モデルの制御と品質を向上させることで、テキストから画像への生成を実現しています。NeurIPS 2024 Workshopで発表された論文に基づいており、革新的かつ最先端の技術です。主な利点としては、画像生成の精度と制御性の向上、ならびに芸術創作や仮想現実などの分野における応用可能性が挙げられます。
画像生成
47.7K
中国語精選
DINO X
DINO-Xは物体認識を中核とした大規模ビジョンモデルであり、オープンセット検出、インテリジェントな質問応答、人体姿勢推定、物体カウント、衣服の色変更といったコア機能を備えています。既知の物体だけでなく、未知のカテゴリにも柔軟に対応し、高度なアルゴリズムにより優れた適応性と堅牢性を誇ります。予測不可能な様々な課題にも正確に対応し、複雑なビジュアルデータに対する包括的なソリューションを提供します。DINO-Xは、ロボット工学、農業、小売業、セキュリティ監視、交通管理、製造業、スマートホーム、物流?倉庫、エンターテインメントメディアなど、幅広い用途に適用可能であり、DeepDataSpace社がコンピュータビジョン技術分野で開発した主力製品です。
物体検出
63.5K
Autoseg SAM2
AutoSeg-SAM2は、Segment-Anything-2(SAM2)とSegment-Anything-1(SAM1)に基づいた、全動画自動セグメンテーションツールです。動画内の各オブジェクトを追跡し、新たなオブジェクトの可能性も検出します。本ツールは、静的セグメンテーション結果を提供し、SAM2を用いてそれらを追跡することで、動画コンテンツ分析、オブジェクト認識、動画編集などの分野で重要な役割を果たします。開発者はzrporzであり、Facebook ResearchのSAM2とzrporz独自のSAM1に基づいて開発されています。オープンソースプロジェクトであるため、無料でご利用いただけます。
オブジェクト追跡
47.2K
Turbolens
TurboLensは、OCR、コンピュータビジョン、生成AIを統合したフル機能プラットフォームです。非構造化画像からインサイトを自動的に高速生成し、ワークフローを簡素化します。革新的なOCR技術とAI駆動の翻訳?分析キットにより、印刷物や手書き文書からカスタマイズされたインサイトを抽出します。さらに、数式や表の認識機能も備え、画像を操作可能なデータに変換し、数式をLaTeX形式、表をExcel形式に変換します。価格体系は無料プランと有料プランを提供し、様々なユーザーニーズに対応します。
コンピュータビジョン
50.0K
Llama Mesh
LLaMA-Meshは、大規模言語モデル(LLM)をテキスト上での事前学習から3Dメッシュ生成へと拡張する技術です。この技術は、LLMに既に埋め込まれている空間的知識を活用し、対話型の3D生成とメッシュ理解を実現します。LLaMA-Meshの主な利点は、3Dメッシュの頂点座標と面定義を純粋なテキストとして表現できるため、LLMとの直接的な統合が可能で、語彙の拡張が不要な点です。主な特長としては、テキストプロンプトからの3Dメッシュ生成、テキストと3Dメッシュ出力のオンデマンドな交互生成、3Dメッシュの理解と解釈などが挙げられます。LLaMA-Meshは、強力なテキスト生成性能を維持しながら、ゼロから訓練されたモデルと同等のメッシュ生成品質を実現しています。
人工知能
61.8K

Countanything
CountAnythingは、高度なコンピュータビジョンアルゴリズムを利用して、物体数を自動的かつ正確に計数する最先端のアプリケーションです。工業、養殖業、建設業、医療、小売など、様々なシーンで活用できます。本製品の主な利点は、高精度と高効率であり、計数作業の正確性と速度を大幅に向上させることができます。製品背景情報として、現在CountAnythingは中国本土以外のユーザー向けに公開されており、無料トライアルを提供しています。
物体計数
53.0K
NVIDIA AI Blueprint
NVIDIA AI Blueprint for Video Search and Summarizationは、NVIDIA NIMマイクロサービスと生成AIモデルに基づいた、自然言語プロンプトを理解し、ビジュアルな質問応答を実行するビジュアルAIエージェント構築のための参考ワークフローです。これらのエージェントは、工場、倉庫、小売店、空港、交差点など、さまざまな場面に展開でき、運用チームが自然なインタラクションから得られる豊富な洞察に基づいて、より良い意思決定を支援します。
AIモデル
49.7K
Genxd
GenXDは、3Dおよび4Dシーン生成に特化したフレームワークです。日常生活でよく見られるカメラや物体の動きを利用して、一般的な3Dおよび4D生成の共同研究を行います。コミュニティには大規模な4Dデータが不足しているため、GenXDはまず、ビデオからカメラの姿勢と物体の動きの強度を取得するデータ策定プロセスを提案しました。このプロセスに基づいて、GenXDは大規模な現実世界の4DシーンデータセットであるCamVid-30Kを導入しました。すべての3Dおよび4Dデータを利用することで、GenXDフレームワークはあらゆる3Dまたは4Dシーンを生成できます。カメラと物体の動きを分離し、3Dおよび4Dデータからシームレスに学習するマルチビュー時間モジュールを提案しています。さらに、GenXDは、複数の条件付きビューをサポートするために、マスク潜在条件を採用しています。GenXDは、カメラの軌跡に従うビデオと、3D表現に昇格できる一貫性のある3Dビューを生成できます。様々な現実世界および合成データセットで広範な評価を行い、GenXDが3Dおよび4D生成において、従来の方法と比較して有効性と多機能性を備えていることを示しました。
3Dモデリング
49.1K
Tencent Hunyuan Large
Tencent-Hunyuan-Large(混元大模型)は、テンセントが発表した業界をリードするオープンソースの大規模混合専門家(MoE)モデルであり、総パラメータ数3890億、活性化パラメータ数520億を誇ります。自然言語処理、コンピュータビジョン、科学タスクなどにおいて顕著な進歩を遂げており、特に長いコンテキストの入力処理と、長コンテキストタスク処理能力の向上において優れた性能を発揮します。混元大模型のオープンソース化は、より多くの研究者の革新的な発想を促し、AI技術の進歩と応用を共同で推進することを目指しています。
AIモデル
57.1K
- 1
- 2
- 3
- 4
- 5
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.5K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M