%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Omnisensevoice
紹介 :
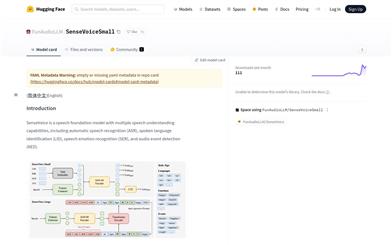
OmniSenseVoiceは、SenseVoiceを最適化した音声認識モデルです。高速推論と高精度なタイムスタンプに特化し、よりスマートで高速な音声文字起こしを提供します。
ターゲットユーザー :
音声文字起こし、音声分析、リアルタイム音声認識を必要とする企業や開発者を対象としています。OmniSenseVoiceの高速処理能力と高精度なタイムスタンプ機能は、会議録の作成、講義内容の文字起こし、リアルタイム翻訳など、大量の音声データを迅速に処理する必要がある場面に最適です。
使用シナリオ
会議のリアルタイム音声文字起こしを行い、タイムスタンプ付きの会議録を作成する。
オンラインコースの内容を文字起こしし、タイムスタンプ付きの講義ノートを生徒に提供する。
リアルタイム翻訳アプリケーションで、迅速かつ正確な音声翻訳サービスを提供する。
製品特徴
様々な言語の自動検出または指定に対応(自動、中国語、英語、広東語、日本語、韓国語)。
テキスト正規化オプションを提供。逆テキスト正規化処理の有無を選択できます。
特定のGPUでの実行を選択可能(デフォルトはCPU)。
量子化モデルを使用して処理速度を向上。
詳細なヘルプ情報を提供し、ユーザーの理解と使用を容易にします。
ベンチマーク機能により、モデルのパフォーマンスを評価可能。
正確性を損なうことなく、最大50倍の高速処理に対応。
使用チュートリアル
1. OmniSenseVoiceモデルをインストールします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 必要に応じて言語パラメーターを設定します(例:--language ja)。
3. テキスト正規化処理の有無を選択します(例:--textnorm woitn)。
4. 実行するデバイスIDを指定します(例:--device-id 0)。
5. 必要に応じて、量子化モデルを使用できます(例:--quantize)。
6. ベンチマークテストを実行して、モデルのパフォーマンスを評価します(例:omnisense benchmark -s -d --num-workers 2 --device-id 0 --batch-size 10 --textnorm woitn --language en benchmark/data/manifests/libritts/libritts_cuts_dev-clean.jsonl)。
7. READMEファイルを参照して、詳細な使用方法と設定オプションを確認してください。
8. 具体的なニーズに合わせてパラメーターを調整し、音声認識タスクを実行します。