%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Seed ASR
紹介 :
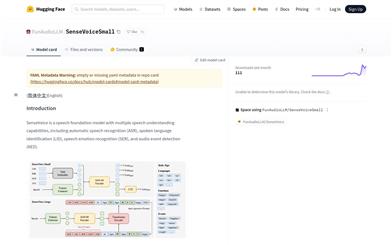
Seed-ASRは、バイトダンス社が開発した大規模言語モデル(Large Language Model, LLM)に基づく音声認識モデルです。連続音声表現とコンテキスト情報をLLMに入力することで、LLMの能力を活用し、大規模な訓練とコンテキスト認識能力によって、複数領域、アクセント/方言、言語を含む包括的な評価セットでのパフォーマンスを大幅に向上させました。最近発表された大規模ASRモデルと比較して、Seed-ASRは中国語と英語の共通テストセットで10~40%の単語誤り率の低減を実現し、その強力な性能をさらに証明しています。
ターゲットユーザー :
Seed-ASRのターゲットユーザーは、高精度な音声認識サービスを必要とする企業や個人です。例えば、音声テキスト変換サービスプロバイダー、多言語コンテンツ制作者、複雑な環境での音声認識を必要とするアプリケーション開発者などが該当します。本技術は、複数言語や方言の処理、特定のコンテキスト環境での正確な音声認識が必要な場面に特に適しています。
使用シナリオ
企業がSeed-ASRを使用して会議録音のリアルタイム書き起こしを行い、会議記録の効率と精度を向上させる。
コンテンツ制作者がSeed-ASRを使用してビデオまたはポッドキャストの音声コンテンツをテキストに変換し、コンテンツのマルチプラットフォーム配信を容易にする。
教育機関がSeed-ASRを使用して授業録音の書き起こしを行い、生徒の復習と教師の評価を容易にする。
製品特徴
コンテキスト認識能力:会話履歴、代理名、代理説明情報などのコンテキスト情報に基づいて、認識精度を向上させることができます。
多領域適応性:ビジネス、教育、エンターテインメントなど、さまざまな分野で正確な音声認識サービスを提供できます。
多言語対応:中国語、英語など複数の言語の音声認識に対応しています。
多方言認識:呉語、広東語、四川語など、中国のさまざまな方言を認識できます。
エラー自己修正:字幕の修正を認識のヒントとして使用し、後続のビデオで同じエラーを繰り返さないようにすることができます。
背景ノイズ耐性:背景ノイズがあっても高い認識精度を維持できます。
使用チュートリアル
ステップ1:Seed-ASRの公式ウェブサイトにアクセスするか、関連アプリをダウンロードします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
ステップ2:アカウントを登録してログインし、必要に応じて適切なサービスプランを選択します。
ステップ3:認識する音声ファイルをアップロードするか、リアルタイム音声認識を実行します。
ステップ4:言語、方言などの認識パラメーターを設定します。
ステップ5:認識プロセスを開始し、Seed-ASRが音声データを処理するのを待ちます。
ステップ6:認識結果を確認し、必要に応じて編集および修正します。
ステップ7:認識後のテキストデータをエクスポートまたは使用して、さらなる分析や記録を行います。