%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Scale Leaderboard
紹介 :
Scale Leaderboardは、AIモデルのパフォーマンス評価に特化したプラットフォームです。専門家による審査を経たプライベートな評価データセットを使用することで、評価結果の公平性と信頼性を確保しています。最新のデータセットとモデルを定期的にランキングに追加し、ダイナミックな競争環境を促進します。厳格な審査を受けた専門家が、分野固有の方法を用いて評価を行うため、高品質かつ信頼性の高い評価が保証されます。
ターゲットユーザー :
Scale Leaderboardは、様々なAIモデルのパフォーマンスを公平かつ信頼性の高い方法で評価?比較する必要があるAI研究者や開発者を対象としています。本プラットフォームは、モデルの長所と短所の特定を支援し、モデルの改善と最適化を促進します。
使用シナリオ
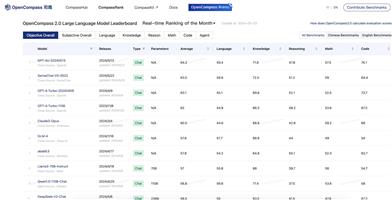
GPT-4 Turbo Previewがプログラミングカテゴリーで1位(スコア1155)
Claude 3 Opusが数学カテゴリーで1位(スコア95.19)
GPT-4oが指示遵守カテゴリーで2位(スコア88.57)
製品特徴
データ改ざんを防ぐためのプライベートな評価データセット
最新のデータセットとモデルを含むランキングの定期更新
専門家による分野固有の方法を用いた評価
詳細な評価方法論情報の提供
プログラミング、数学、指示遵守、スペイン語など、複数のカテゴリーを含むランキング
使用チュートリアル
Scale Leaderboardウェブサイトにアクセスする
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
様々なカテゴリーのAIモデルランキングを確認する
興味のあるモデルを選択し、パフォーマンススコアとランキングを確認する
評価方法論を読んで、スコアリングの根拠を理解する
ランキングにモデルを追加したい場合は、seal@scale.comまでご連絡ください




おすすめAI製品
Deepeval
DeepEvalは、LLMが問題に対する回答を評価するための多角的な指標を提供し、回答が関連性があり、一貫性があり、偏りや有害な表現を含まないことを保証します。CI/CDパイプラインとの統合も容易で、機械学習エンジニアはLLMアプリケーションの改善に伴うパフォーマンスの向上を迅速に評価?検証できます。DeepEvalはPythonに優しいオフライン評価方法を提供し、パイプラインの運用準備を確実にします。それはまさに「パイプラインのためのPytest」と言えるもので、テストの通過と同じくらいシンプルで直接的な方法で、生産と評価パイプラインのプロセスを実現します。
AIモデル評価
159.5K

Gpteval3d
GPTEval3Dは、GPT-4Vを基盤としたオープンソースの3D生成モデル評価ツールです。テキストから3Dモデルを生成するモデルを自動的に評価し、ELOスコアを算出、既存モデルとの比較ランキングを提供します。シンプルで使いやすい設計となっており、ユーザーによるカスタム評価データセットもサポート。GPT-4Vの評価能力を最大限に活かし、3D生成タスク研究における強力なツールとなります。
AIモデル評価
74.8K