%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Transformers
EXAONE 3.5 7.8B Instruct AWQ
EXAONE 3.5 is a series of instruction-tuned bilingual (English and Korean) generative models developed by LG AI Research, with parameters ranging from 2.4B to 32B. These models support long context processing of up to 32K tokens and demonstrate state-of-the-art performance in real-world use cases and long context understanding, while remaining competitive in general domains compared to similarly sized models released recently. The EXAONE 3.5 models include: 1) the 2.4B model, optimized for deployment on small or resource-constrained devices; 2) the 7.8B model, matching the size of predecessor models but offering improved performance; 3) the 32B model, providing powerful performance.
AI Model
48.0K
Llama 3 Patronus Lynx 70B Instruct Q4 K M GGUF
PatronusAI/Llama-3-Patronus-Lynx-70B-Instruct-Q4_K_M-GGUF is a large quantized language model based on 70 billion parameters, utilizing 4-bit quantization technology to reduce model size and enhance inference efficiency. This model belongs to the PatronusAI series and is built upon the Transformers library, suitable for applications requiring high-performance natural language processing. The model adheres to the cc-by-nc-4.0 license agreement, allowing for non-commercial usage and sharing.
AI Model
46.1K
Llama 3 Patronus Lynx 8B V1.1 Instruct Q8 GGUF
PatronusAI/Llama-3-Patronus-Lynx-8B-v1.1-Instruct-Q8-GGUF is a quantized version based on the Llama model, specifically designed for dialogue and hallucination detection. It employs the GGUF format and contains 803 million parameters, classifying it as a large language model. Its significance lies in providing high-quality dialogue generation and hallucination detection capabilities, while maintaining efficient model performance. The model is built on the Transformers library and GGUF technology, suitable for applications requiring high-performance conversational systems and content generation.
Chatbot
46.4K
EXAONE 3.5 2.4B Instruct AWQ
EXAONE-3.5-2.4B-Instruct-AWQ is a series of bilingual (English and Korean) instruction-tuned generative models developed by LG AI Research, with parameter sizes ranging from 2.4B to 32B. These models support long context processing of up to 32K tokens and demonstrate state-of-the-art performance in real-world use cases and long context understanding, while remaining competitive in general domains compared to similarly sized recently released models. The model has been optimized for deployment on small or resource-constrained devices and utilizes AWQ quantization technology, achieving 4-bit grouped weight quantization (W4A16g128).
AI Model
51.6K
Llama Lynx 70b 4bit Quantized
Llama-Lynx-70b-4bit-Quantized is a large text generation model developed by PatronusAI, containing 7 billion parameters and optimized through 4-bit quantization to enhance model size and inference speed. Built on the Hugging Face Transformers library, it supports multiple languages and excels in dialogue and text generation tasks. Its significance lies in its ability to reduce storage and computational requirements while maintaining high performance, enabling the deployment of robust AI models in resource-constrained environments.
AI Model
46.4K
Llama Lynx 70b 4bitAWQ
Llama-lynx-70b-4bitAWQ is a 70 billion parameter text generation model hosted by Hugging Face, employing 4-bit precision and AWQ technology. This model is significant in the field of natural language processing, especially for tasks requiring the processing of large datasets and complex operations. Its advantages include the generation of high-quality text while maintaining low computational costs. Background information indicates compatibility with the 'transformers' and 'safetensors' libraries, making it suitable for text generation tasks.
AI Model
46.4K
EXAONE 3.5 7.8B Instruct
EXAONE-3.5-7.8B-Instruct is a series of bilingual (English and Korean) generative models optimized for instructions, developed by LG AI Research, with parameter sizes ranging from 2.4B to 32B. These models support long context processing of up to 32K tokens, demonstrating state-of-the-art performance in real-world applications and long-context understanding, while remaining competitive in general domains compared to similarly sized models recently released.
AI Model
48.0K
EXAONE 3.5 2.4B Instruct
EXAONE-3.5-2.4B-Instruct is a series of bilingual (English and Korean) instruction-tuned generation models developed by LG AI Research, with parameter sizes ranging from 2.4B to 32B. These models support long context processing of up to 32K tokens and demonstrate state-of-the-art performance in real-world use cases and long context understanding while remaining competitive in general domains compared to similarly sized recently released models. The model is particularly suited for scenarios that require processing long texts and multilingual needs, such as automatic translation, text summarization, and conversational systems.
Translation
50.5K
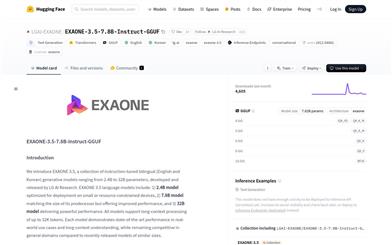
EXAONE 3.5 7.8B Instruct GGUF
EXAONE 3.5 is a series of bilingual (English and Korean) instruction-tuned generation models developed by LG AI Research, with parameters ranging from 2.4B to 32B. These models support long-context processing of up to 32K tokens and demonstrate state-of-the-art performance in real-world use cases and long-context understanding, while remaining competitive in general domains when compared to recently released models of similar size. The EXAONE 3.5 model series includes: 1) 2.4B model, optimized for deployment on small or resource-constrained devices; 2) 7.8B model, which matches the size of previous models but offers improved performance; 3) 32B model, providing robust performance.
AI Model
55.8K
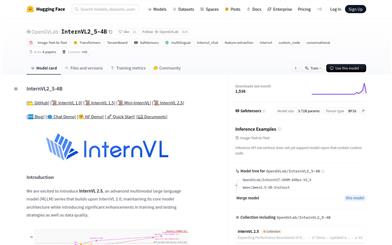
Internvl2 5 4B
InternVL2_5-4B is an advanced multimodal large language model (MLLM) that maintains the core model architecture of InternVL 2.0 while significantly enhancing training and testing strategies and data quality. The model excels in handling tasks from image and text to text, particularly in multimodal reasoning, mathematical problem solving, OCR, and chart and document comprehension. As an open-source model, it provides researchers and developers with powerful tools to explore and build intelligent applications based on visual and linguistic elements.
AI Model
45.5K
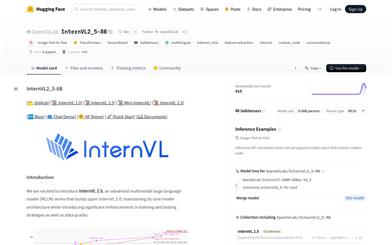
Internvl2 5 8B
InternVL2_5-8B is a multimodal large language model (MLLM) developed by OpenGVLab, significantly enhanced with training and testing strategies as well as data quality improvements based on InternVL 2.0. This model employs the 'ViT-MLP-LLM' architecture, integrating the newly pre-trained InternViT with various pre-trained language models, such as InternLM 2.5 and Qwen 2.5, utilizing a randomly initialized MLP projector. The InternVL 2.5 series models demonstrate outstanding performance on multimodal tasks, including image and video understanding and multilingual comprehension.
AI Model
51.3K
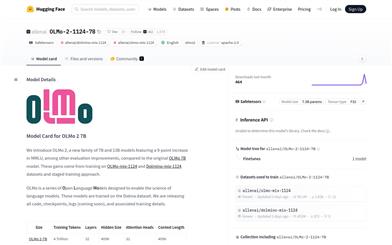
Olmo 2 7B
OLMo 2 7B, developed by the Allen Institute for AI (Ai2), is a large language model with 7 billion parameters that demonstrates excellent performance across various natural language processing tasks. By training on large-scale datasets, it is capable of understanding and generating natural language, supporting a range of research and applications related to language models. The main advantages of OLMo 2 7B include its large parameter count, which allows it to capture subtler linguistic features, and its open-source nature, which fosters further research and application in academia and industry.
AI Model
45.5K
Smolvlm
SmolVLM is a compact yet powerful visual language model (VLM) with 2 billion parameters, leading in efficiency and memory usage among similar models. It is fully open-source, with all model checkpoints, VLM datasets, training recipes, and tools released under the Apache 2.0 license. The model is designed for local deployment in browsers or edge devices, reducing inference costs and allowing for user customization.
AI Model
53.0K
Qwq 32B Preview
QwQ-32B-Preview is an experimental research model developed by the Qwen team, aimed at improving AI reasoning capabilities. This model demonstrates promising analytical abilities, but it also has significant limitations. It excels in mathematics and programming; however, it has room for improvement in common-sense reasoning and nuanced language understanding. The model employs a transformer architecture with 32.5 billion parameters, 64 layers, and 40 attention heads (GQA). Background information reveals that QwQ-32B-Preview is a further development of the Qwen2.5-32B model, featuring enhanced language understanding and generation abilities.
AI Model
53.0K
Qwen2.5 Coder 0.5B Instruct GPTQ Int8
Qwen2.5-Coder is the latest series of the Qwen large language model, focusing on code generation, reasoning, and debugging. Based on the robust Qwen2.5, this series significantly improves code generation, reasoning, and repair capabilities by incorporating 55 trillion training tokens, including source code, text code grounding, and synthetic data. The Qwen2.5-Coder-32B has emerged as the most advanced open-source large language model for code generation, matching the coding capabilities of GPT-4o. Additionally, Qwen2.5-Coder offers a more comprehensive foundation for real-world applications, such as code agents, enhancing coding abilities while maintaining strengths in mathematics and general proficiency.
Coding Assistant
45.5K
Qwen2.5 Coder 0.5B Instruct GPTQ Int4
Qwen2.5-Coder is the latest series in the Qwen large language model lineup, focusing on code generation, inference, and debugging. Built upon the powerful Qwen2.5 framework, this model was trained on 550 trillion sources, including source code, text code foundations, and synthetic data, making it the most advanced open-source code language model available today. It not only matches the programming capabilities of GPT-4o but also maintains an edge in mathematics and general competencies. The Qwen2.5-Coder-0.5B-Instruct-GPTQ-Int4 model features a 4-bit quantized instruction-tuned architecture, incorporating causal language modeling, pre-training and fine-tuning, as well as a transformers architecture.
Coding Assistant
48.0K
Qwen2.5 Coder 0.5B Instruct AWQ
Qwen2.5-Coder represents the latest series of the Qwen large language models, focusing on code generation, reasoning, and repair. Built on the robust foundations of Qwen2.5, with a training corpus expanded to 5.5 trillion tokens that includes source code, textual code bases, and synthetic data, Qwen2.5-Coder-32B has emerged as the leading open-source code LLM, matching the coding capabilities of GPT-4o. This model is a 4-bit instruction-tuned version of the 0.5B parameters, featuring characteristics such as causal language modeling, pre-training and fine-tuning, as well as a transformer architecture.
Code Reasoning
45.3K
Alphaqubit
AlphaQubit is an artificial intelligence system developed collaboratively by Google's DeepMind and Quantum AI teams, capable of identifying errors in quantum computers with state-of-the-art accuracy. This technology integrates expertise in machine learning and quantum error correction, aimed at advancing the construction of reliable quantum computers, which is crucial for solving complex problems, achieving scientific breakthroughs, and exploring new domains. The primary advantages of AlphaQubit include high accuracy and applicability to large-scale quantum computation.
Artificial Intelligence
46.1K
Qwen2.5 Coder 32B Instruct GGUF
Qwen2.5-Coder is a model specifically designed for code generation, significantly improving capabilities in this area, with a variety of parameter sizes and support for quantization. It is free and enhances efficiency and quality for developers.
Code Reasoning
50.0K
Qwen2.5 Coder 0.5B Instruct
Qwen2.5-Coder is the latest series of the Qwen large language model, focusing on code generation, reasoning, and fixing. Built on the powerful Qwen2.5 with an extended training dataset of 5.5 trillion tokens that includes source code, text code bases, and synthetic data, Qwen2.5-Coder-32B has become the leading open-source code LLM, matching GPT-4o in coding abilities. This model not only enhances coding capabilities but also maintains superiority in mathematics and general abilities, providing a comprehensive foundation for real-world applications like code assistance.
Coding Assistant
44.7K
Qwen2.5 Coder 1.5B
Qwen2.5-Coder-1.5B is a large language model in the Qwen2.5-Coder series, focusing on code generation, reasoning, and debugging. Built upon the robust Qwen2.5 architecture, this model has significantly expanded the training tokens to 5.5 trillion, incorporating source code, textual code bases, synthetic data, and more, making it a leader among open-source code LLMs, rivaling GPT-4o's coding capabilities. Moreover, Qwen2.5-Coder-1.5B has enhanced its mathematical and general capabilities, providing a more comprehensive foundation for practical applications such as code agents.
Coding Assistant
49.7K
Qwen2.5 Coder 7B
Qwen2.5-Coder-7B is a large language model based on Qwen2.5, focusing on code generation, reasoning, and correction. It has been trained on 5.5 trillion tokens, including source code, textual code grounding, synthetic data, etc., representing the latest advancements in open-source code language models. This model not only matches GPT-4o in programming capabilities but also retains advantages in mathematics and general skills, supporting long contexts of up to 128K tokens.
Coding Assistant
45.3K
Qwen2.5 Coder 7B Instruct
Qwen2.5-Coder-7B-Instruct is a large language model specifically designed for code, part of the Qwen2.5-Coder series which includes six mainstream model sizes: 0.5, 1.5, 3, 7, 14, and 32 billion parameters to meet the diverse needs of developers. This model shows significant improvements in code generation, reasoning, and debugging, trained on an extensive dataset of 5.5 trillion tokens that includes source code, code-related textual data, and synthetic data. The Qwen2.5-Coder-32B represents the latest advancement in open-source code LLMs, matching the coding capabilities of GPT-4o. Moreover, it supports long context lengths of up to 128K tokens, providing a solid foundation for practical applications like code agents.
Coding Assistant
44.2K
Qwen2.5 Coder 14B
Qwen2.5-Coder-14B is a large language model in the Qwen series focused on code, encompassing various model sizes ranging from 0.5 to 32 billion parameters to meet diverse developer needs. The model shows significant improvements in code generation, reasoning, and repair, built upon the powerful Qwen2.5, with a training token expansion to 5.5 trillion, including source code, grounded text code, and synthetic data. Qwen2.5-Coder-32B has become the leading open-source code LLM, matching the coding capacity of GPT-4o. Additionally, it provides a comprehensive foundation for real-world applications such as code agents, enhancing coding abilities while maintaining advantages in mathematics and general tasks. It supports long contexts of up to 128K tokens.
Coding Assistant
48.3K
Qwen2.5 Coder 14B Instruct
Qwen2.5-Coder-14B-Instruct is a large language model in the Qwen2.5-Coder series, focusing on code generation, reasoning, and repair. Built upon the powerful Qwen2.5, this model is trained on 5.5 trillion tokens, including source code and synthesized data, making it a leading open-source code LLM. It not only enhances coding capabilities but also maintains strengths in mathematics and general abilities while supporting long contexts of up to 128K tokens.
Coding Assistant
46.1K
Qwen2.5 Coder 32B
Qwen2.5-Coder-32B is a code generation model based on Qwen2.5, featuring 32 billion parameters, making it one of the largest open-source code language models available today. It shows significant improvements in code generation, reasoning, and fixing, capable of handling long texts up to 128K tokens, which is suitable for practical applications such as code assistants. The model also maintains advantages in mathematical and general capabilities, supporting long text processing, thus serving as a powerful assistant for developers in code development.
Coding Assistant
48.3K
Qwen2.5 Coder 32B Instruct
Qwen2.5-Coder represents a series of large language models designed specifically for code generation, featuring six mainstream model sizes with 0.5, 1.5, 3, 7, 14, and 32 billion parameters to meet diverse developers' needs. This model has made significant improvements in code generation, reasoning, and repair, built upon the robust Qwen2.5, trained on a token count expanding to 5.5 trillion, including source code, text code basics, synthetic data, and more. The Qwen2.5-Coder-32B is currently the most advanced open-source code generation large language model, rivaling the encoding capabilities of GPT-4o. It not only enhances coding abilities but also retains advantages in mathematics and general understanding, supporting long contexts of up to 128K tokens.
Coding Assistant
46.1K
Transformers.js
transformers.js is a JavaScript library designed to offer advanced machine learning capabilities to web applications. It allows users to run pre-trained Transformers models directly in the browser without server support. The library utilizes ONNX Runtime as the backend, supporting the conversion of PyTorch, TensorFlow, or JAX models into ONNX format. transformers.js is equivalent in functionality to the Hugging Face transformers Python library, providing similar APIs to ease the migration of existing code to the web side.
AI Development Assistants
56.6K
Llama 3 70B Gradient 524K Adapter
The Llama-3 70B Gradient 524K Adapter is an extension of the Llama-3 70B model, developed by the Gradient AI Team. It is designed to extend the model's context length to over 524K through LoRA technology, thereby enhancing the model's performance in handling long text data. The model employs advanced training technologies, including NTK-aware interpolation and the RingAttention library, to efficiently train within high-performance computing clusters.
AI Model
48.3K
Tinyllama
The TinyLlama project aims to pre-train a 1.1B Llama model on 3 trillion tokens. With some optimizations, we can achieve this in just 90 days using 16 A100-40G GPUs. Training began on 2023-09-01. We adopt the same architecture and tokenizer as Llama 2. This means TinyLlama can be used in many open-source projects built on top of Llama. Additionally, with only 1.1B parameters, TinyLlama's compactness allows it to meet the needs of many applications with limited computational and memory resources.
AI Model
65.7K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.5K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M