%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Text to Image

Diffsplat
DiffSplat is an innovative 3D generation technology that quickly creates 3D Gaussian point clouds from text prompts and single-view images. This technology leverages a large-scale pre-trained text-to-image diffusion model to efficiently generate 3D content. It addresses the limitations of traditional 3D generation methods concerning dataset size and the ineffective use of 2D pre-trained models, while maintaining 3D consistency. Key advantages of DiffSplat include efficient generation speeds (completed in 1 to 2 seconds), high-quality 3D output, and support for various input conditions. The model has broad prospects in academic research and industrial applications, particularly in scenarios requiring the rapid generation of high-quality 3D models.
3D Modeling
50.2K
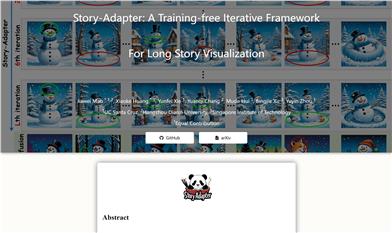
Story Adapter
Story-Adapter is an iterative framework designed specifically for visualizing long-form stories without the need for training. It optimizes the image generation process through an iterative paradigm and a global reference cross-attention module, maintaining semantic coherence in the story while reducing computational costs. The significance of this technology lies in its ability to generate high-quality, detail-rich images within long narratives, addressing the challenges faced by traditional text-to-image models in visualizing extended stories, such as semantic consistency and computational feasibility.
Image Generation
95.5K
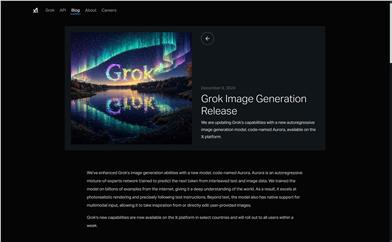
Grok Aurora
Aurora is a next-generation autoregressive image generation model launched by Grok, trained on billions of internet samples, enabling a profound understanding of the world. Aurora excels in photo-realistic rendering and accurately follows text instructions, supporting multimodal input to draw inspiration from user-provided images or directly edit them. The new features are already available in selected countries on the ?? platform and will be rolled out to all users within a week.
Image Generation
46.9K

Sana
Sana is a text-to-image framework capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at an incredibly fast speed while maintaining strong text-image alignment and can be deployed on laptop GPUs. The core design of Sana includes a deep compressed autoencoder, a linear diffusion transformer (DiT), a small language model as a decoder-only text encoder, and efficient training and sampling strategies. Compared to modern large diffusion models, Sana-0.6B is 20 times smaller and measures throughput over 100 times faster. Additionally, Sana-0.6B can be deployed on a 16GB laptop GPU, generating images at 1024×1024 resolution in less than 1 second. Sana makes low-cost content creation feasible.
Image Generation
52.2K
Stable Diffusion 3.5 ControlNets
Stable Diffusion 3.5 ControlNets, provided by Stability AI, is a text-to-image AI model that supports various ControlNets, including Canny edge detection, depth maps, and high-fidelity upscaling. This model generates high-quality images based on textual prompts, making it especially suitable for applications in illustration, architectural rendering, and 3D asset texturing. Its significance lies in providing finer control over image generation, enhancing the quality and detail of outputs. Background information includes its citation in academia (arxiv:2302.05543) and adherence to the Stability Community License. In terms of pricing, it is free for non-commercial use and for commercial use with an annual income below $1 million; exceeding this requires contacting for a corporate license.
Image Generation
50.2K
Chinese Picks
Qiantuwang AI Art Generation
Qiantuwang AI Art Generation is a platform that utilizes artificial intelligence to transform users' text descriptions into images. Through deep learning algorithms, it understands user creativity needs and generates corresponding visual content. The significance of this technology lies in its ability to greatly lower the barriers to artistic creation, enabling non-professionals to easily produce professional-quality images. Background information demonstrates that Qiantuwang AI Art Generation aims to unleash users' imagination and creativity, providing an easy-to-use AI creative toolbox. Pricing includes a free trial for users to experience the charm of AI art generation, along with paid services to meet more professional needs.
Image Generation
95.2K
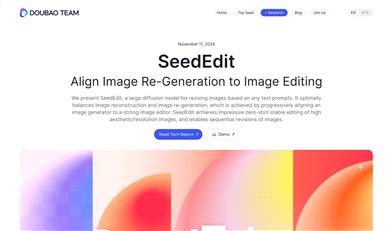
Seededit
SeedEdit is a large diffusion model introduced by the Doubao Team, designed to revise images based on any text prompts. It achieves an optimal balance between image reconstruction and regeneration by aligning a powerful image generator with a robust image editor in a stepwise fashion. SeedEdit enables zero-shot stable editing of high aesthetic/resolution images and supports continuous revision of images. The significance of this technology lies in its ability to address the core challenge of scarcity of paired image data in image editing problems, by viewing the text-to-image (T2I) generation model as a weak editing model and achieving 'editing' by generating new images with new prompts, which are then distilled and aligned within an image-conditioned editing model.
Image Editing
206.2K
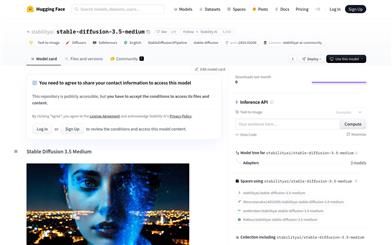
Stable Diffusion 3.5 Medium
Stable Diffusion 3.5 Medium is a text-to-image generation model developed by Stability AI, featuring improved image quality, typography, understanding of complex prompts, and resource efficiency. The model employs three fixed pre-trained text encoders, enhances training stability using QK normalization, and incorporates dual attention blocks in the first 12 transformer layers. It excels in multi-resolution image generation, consistency, and adaptability across various text-to-image tasks.
Image Generation
65.1K
Sd3.5
Stable Diffusion 3.5 is a lightweight model designed for simple inference, incorporating a text encoder, VAE decoder, and core MM-DiT technology. This model aims to assist partner organizations in implementing SD3.5 and can be used to produce high-quality images. Its significance lies in its efficient inference capabilities and low resource requirements, allowing a wide user base to enjoy the art of image generation. The model adheres to the Stability AI Community License Agreement and is available for free.
Image Generation
63.5K
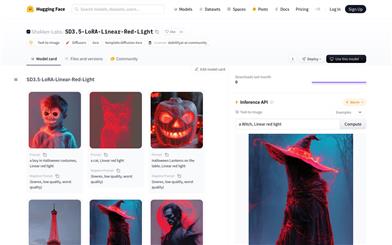
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Light is an AI model for text-to-image generation that utilizes LoRA (Low-Rank Adaptation) technology. This model can generate high-quality images based on user-provided text prompts, achieving efficient model fine-tuning at a lower computational cost while maintaining diversity and quality in generated images. It is based on the Stable Diffusion 3.5 Large model and has been optimized to meet specific image generation requirements.
Image Generation
63.5K
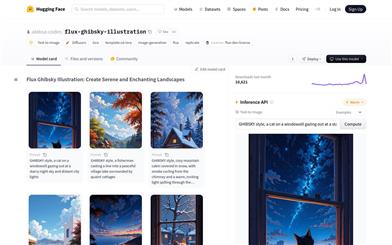
Flux Ghibsky Illustration
Flux Ghibsky Illustration is a text-to-image model that merges the enchanting details of Studio Ghibli animations with the serene skies found in Makoto Shinkai's works, creating captivating scenes. This model is particularly well-suited for creating dreamlike visuals, allowing users to generate images with a unique aesthetic using specific trigger words. It is an open-source project based on the Hugging Face platform, allowing users to download the model and run it on Replicate.
AI image generation
70.4K
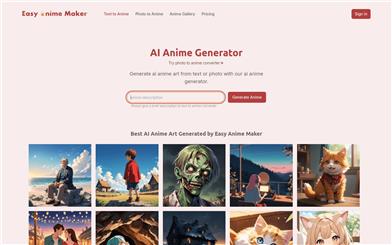
Easy Anime Maker
Easy Anime Maker is an AI-based anime generator that employs deep learning techniques, such as Generative Adversarial Networks, to convert user-inputted text descriptions or uploaded photos into anime-style artworks. This technology significantly lowers the barriers to creating anime art, enabling users without professional drawing skills to produce personalized anime images. The product background indicates it is an online platform perfect for anime enthusiasts and professionals needing quick anime-style images, allowing users to generate art through simple text prompts or photo uploads. A free trial is available, and users can sign up for 5 free points. If additional generations are needed, users can purchase points without a subscription.
AI animation image generation
54.1K
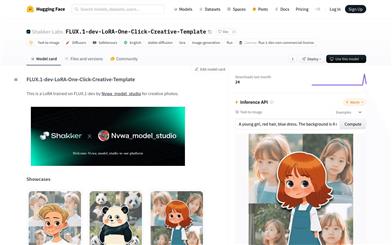
FLUX.1 Dev LoRA One Click Creative Template
FLUX.1-dev-LoRA-One-Click-Creative-Template is an image generation model trained with LoRA, provided by Shakker-Labs. This model focuses on creative photo generation, transforming user text prompts into imaginative images. It employs advanced text-to-image generation technology, making it ideal for users who need to quickly produce high-quality images. The model is hosted on the Hugging Face platform, allowing for convenient deployment and use. Non-commercial use is free, whereas commercial use requires adherence to the relevant licensing agreements.
AI image generation
71.5K
Flux 1.1 Pro AI
Flux 1.1 Pro AI is an AI-driven advanced image generation platform utilizing cutting-edge AI technology to convert user text prompts into high-quality visual effects. This platform boasts a sixfold increase in image generation speed, significantly improved image quality, and enhanced adherence to prompts. Flux 1.1 Pro AI is suitable not only for artists and designers but also for content creators, marketers, and other professionals, helping them realize their visual ideas and improve creativity and quality in their respective fields.
AI image generation
56.9K
Stable Video Portraits
Stable Video Portraits is an innovative hybrid 2D/3D generation method that uses pre-trained text-to-image models (2D) and 3D shape models (3D) to generate realistic dynamic face videos. This technology elevates generic 2D stable diffusion models to video models through person-specific fine-tuning, providing a time-series 3D shape model as a condition, and introduces a temporal denoising process to generate temporally smooth facial images that can be edited and morphed into text-defined celebrity likenesses without additional fine-tuning at test time. This method outperforms existing monocular head avatar methods in both quantitative and qualitative analyses.
AI image generation
50.5K
Cogview3
CogView3 is a text-to-image generation system built on a cascaded diffusion framework. This system decomposes the high-resolution image generation process into multiple stages, adding Gaussian noise to low-resolution outputs, which initiates the diffusion process from these noisy images. CogView3 surpasses SDXL in image generation, featuring faster generation speeds and higher image quality.
AI image generation
65.1K
English Picks
Prompt Llama
Prompt Llama is a dedicated AI model testing platform focusing on text-to-image generation. It allows users to compile high-quality text prompts and test the performance of various models under the same prompts. The platform supports multiple AI models, including but not limited to Midjourney, DALL·E 3, Firefly, making it a valuable resource for researchers and enthusiasts in the field of AI image generation.
AI Model
63.2K
FLUX 1.net
The FLUX AI Image Generator is an innovative image generation model that creates high-quality images based on text prompts. Its significance lies in democratizing high-quality content creation tools, providing a streamlined solution for both professionals and hobbyists, enabling users to produce professional-grade visuals without extensive technical knowledge or resources.
Image Generation
65.1K
Fresh Picks
Storymaker
StoryMaker is an AI model focused on text-to-image generation, capable of producing coherent character and scene images based on textual descriptions. By combining advanced image generation technology with facial encoding, it provides users with a powerful tool for creating visually engaging narratives. The model's key benefits include efficient image generation capabilities, precise control over details, and high responsiveness to user input. It has wide-ranging applications in creative industries, advertising, and entertainment.
AI image generation
115.4K

Concept Sliders
Concept Sliders is a technique for precisely controlling concepts in diffusion models, implemented through low-rank adapters (LoRA) on top of pre-trained models. It allows artists and users to train directional control over specific attributes using simple text descriptions or image pairs. The main advantage of this technology is its ability to make subtle adjustments to generated images without altering their overall structure, such as modifying eye size or lighting, thus achieving finer control. It provides artists with a new means of creative expression while addressing issues of generating blurry or distorted images.
AI design tools
51.6K
Fluximagegenerator.co
Flux Image Generator is a tool that leverages advanced AI model technology to quickly transform users' ideas into high-quality images. It provides three different model variants, including the fast local development model and personal use model FLUX.1 [schnell], the guide distilled model FLUX.1 [dev] for non-commercial use, and FLUX.1 [pro] for state-of-the-art image generation performance. This tool is suitable for both personal projects and commercial use, catering to a variety of user needs.
Image Generation
52.7K
CSGO
CSGO is a text-to-image generation model based on content style synthesis. It generates and automatically cleans stylized data triplets through a data-building pipeline and has constructed the first large-scale style transfer dataset, IMAGStyle, consisting of 210,000 image triplets. The CSGO model employs end-to-end training and clearly decouples content and style features through independent feature injection. It supports image-driven style transfer, text-driven style synthesis, and text-editing-driven style synthesis, offering benefits such as inference without the need for fine-tuning, retaining the generative capabilities of the original text-to-image models, and unifying style transfer and style synthesis.
AI image generation
63.5K
Half Illustration
half_illustration is a text-to-image generation model based on the Flux Dev 1 model that combines photographic and illustrative elements to create artistically compelling images. This model utilizes LoRA technology, enabling style consistency through specific trigger words, making it ideal for artistic creation and design fields.
AI image generation
63.2K
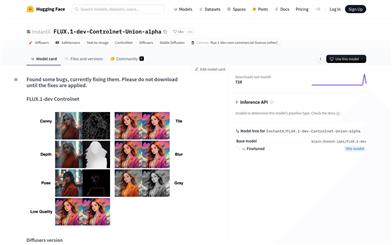
FLUX.1 Dev Controlnet Union Alpha
FLUX.1-dev-Controlnet-Union-alpha is a text-to-image generation model belonging to the Diffusers series, utilizing ControlNet technology for control. Currently, it is in the alpha stage and has not yet been fully trained, but it has demonstrated the effectiveness of its code. This model aims to promote the growth of the Flux ecosystem through the rapid expansion of the open-source community. Although the fully trained Union model may not outperform specialized models in certain areas such as pose control, its performance is expected to improve as training progresses.
AI image generation
73.1K

Texgen
TexGen is an innovative multi-view sampling and resampling framework for synthesizing 3D textures from arbitrary textual descriptions. It leverages a pre-trained text-to-image diffusion model, implementing consistent view sampling and attention-guided multi-view sampling strategies, along with noise resampling techniques, to significantly enhance the texture quality of 3D objects, achieving high viewpoint consistency and rich appearance details.
AI image generation
61.5K
English Picks
Flux AI
Flux AI is an advanced text-to-image AI model developed by Black Forest Labs that employs a transformer-based flow model to generate high-quality images. Key advantages of this technology include outstanding visual quality, strict adherence to prompts, diverse dimensions/aspect ratios, and varied typography and outputs. Flux AI offers three variants: FLUX.1 [pro], FLUX.1 [dev], and FLUX.1 [schnell], each designed for different use cases and performance levels. Flux AI aims to make cutting-edge AI technology accessible to everyone by providing FLUX.1 [schnell] as a free open-source model, ensuring that individuals, researchers, and small developers can benefit from advanced AI technology without financial barriers.
Image Generation
76.2K
Fresh Picks
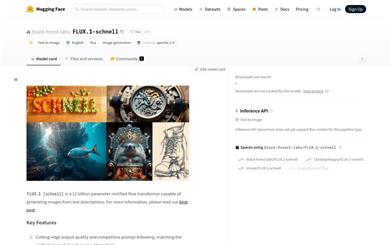
FLUX.1 Schnell
FLUX.1 [schnell] is a modified flow transformer with 1.2 billion parameters that generates images from text descriptions. It is renowned for its state-of-the-art output quality and competitive prompt-following capabilities, matching the performance of closed-source alternatives. The model is trained using latent adversarial diffusion distillation, allowing for the generation of high-quality images in as few as one to four steps. FLUX.1 [schnell] is released under the Apache-2.0 license, making it suitable for personal, scientific, and commercial use.
AI image generation
79.5K
Canva Text To Image
Canva's AI image generator app allows you to have the perfect images at your fingertips - even if they don't exist yet. Using the "Text to Image" feature, simply input text to generate images perfect for creative projects like presentations or social media posts. Choose from different image styles such as watercolor, cinematic, neon, and more. You can also utilize other AI generator applications within Canva, like DALL·E and Imagen. Whether you're a content creator, entrepreneur, or artist, these tools empower you to efficiently create unique images and brand assets. Canva offers both free and paid subscriptions, with paid versions granting you the ability to generate more images per month.
Image Generation
338.7K
English Picks
Playground V2.5
Playground is a free online AI image generator. Users can use it to create artwork, social media posts, presentations, posters, videos, logos, and more. It utilizes the latest advanced visual models to generate high-quality images in various styles and content. Key features and advantages include: 1) Powerful image generation capabilities, capable of generating detailed images based on text descriptions; 2) Support for multiple generation styles, such as realistic, anime, and more; 3) Support for generating high-resolution images; 4) Customizable image style generation, such as color and composition; 5) Free to use, no login required; 6) Simple and user-friendly web interface.
AI image generation
310.8K
Mobilediffusion
MobileDiffusion is a lightweight potential diffusion model designed specifically for mobile devices. It can generate a high-quality 512x512 image in just 0.5 seconds based on text prompts. Compared to other text-to-image models, it is smaller (with only 520M parameters), making it highly suitable for deployment on mobile devices. Its main features include: 1) Image generation based on text; 2) Quick generation, completing in 0.5 seconds; 3) Compact parameter size, just 520M; 4) Generation of high-quality images. Its primary usage scenarios include content creation, artistic creation, game development, and app development, among others. Example uses include: generating a picture of blooming roses by inputting 'Blossoming rose,' generating a picture of a golden retriever joyfully running by inputting 'Golden retrievere frolicking run,' and generating a Martian landscape by inputting 'Martian scenery, outer space.' Compared to other large models, it is more suitable for deployment on mobile devices.
AI image generation
191.8K
- 1
- 2
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.8K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.7K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
42.2K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
43.1K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
42.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.8K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.4K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M