%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Sana
Overview :
Sana is a text-to-image framework capable of efficiently generating images with resolutions up to 4096×4096. It synthesizes high-resolution, high-quality images at an incredibly fast speed while maintaining strong text-image alignment and can be deployed on laptop GPUs. The core design of Sana includes a deep compressed autoencoder, a linear diffusion transformer (DiT), a small language model as a decoder-only text encoder, and efficient training and sampling strategies. Compared to modern large diffusion models, Sana-0.6B is 20 times smaller and measures throughput over 100 times faster. Additionally, Sana-0.6B can be deployed on a 16GB laptop GPU, generating images at 1024×1024 resolution in less than 1 second. Sana makes low-cost content creation feasible.
Target Users :
The target audience includes designers, artists, and content creators who require efficient and low-cost image synthesis. Sana's high-resolution image synthesis capabilities make it ideal for professionals needing to generate high-quality images, such as advertising designers, game developers, and digital artists. Additionally, due to its rapid generation speed and low hardware requirements, Sana is also suitable for individual users and small businesses.
Use Cases
Example 1: A designer uses Sana to generate high-quality advertising images, thereby increasing work efficiency.
Example 2: A game developer utilizes Sana to quickly create in-game background images, reducing development costs.
Example 3: A digital artist employs Sana to create unique artworks, facilitating creative expression.
Features
- Deep compressed autoencoder: Compared to traditional autoencoders, Sana's trained autoencoder can compress images 32 times, effectively reducing the number of latent variables.
- Linear DiT: Replaces all traditional attention mechanisms with linear attention, enhancing efficiency at high resolutions without sacrificing quality.
- Decoder-only text encoder: Utilizes a modern small language model as a decoder-only text encoder, improving image-text alignment through complex human instructions and contextual learning.
- Efficient training and sampling: Proposes Flow-DPM-Solver to reduce sampling steps and accelerates convergence through efficient title tagging and selection.
- Competing with modern large diffusion models: Sana-0.6B performs comparably to modern large diffusion models like Flux-12B while being 20 times smaller and over 100 times faster in throughput.
- Laptop GPU deployment: Sana-0.6B can be deployed on a 16GB laptop GPU, generating images at 1024×1024 resolution in less than 1 second.
- Open-source solution: Sana is committed to providing fast, open-source AI technology to tackle real-world challenges.
How to Use
1. Visit Sana's official website or GitHub page to learn about the product information and usage requirements.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Download and install the necessary software and dependencies as guided on the page.
3. Read through Sana's documentation to understand how to configure the environment and prepare input data.
4. Write your own text prompts based on the example code to generate the desired images.
5. Run the code; Sana will generate corresponding images based on the text prompts.
6. Evaluate the quality of the generated images and adjust the text prompts or model parameters as needed for better results.
7. Use the generated images for personal projects or commercial purposes while adhering to relevant copyright and usage agreements.







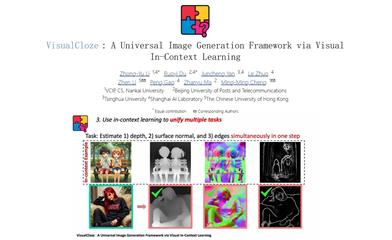
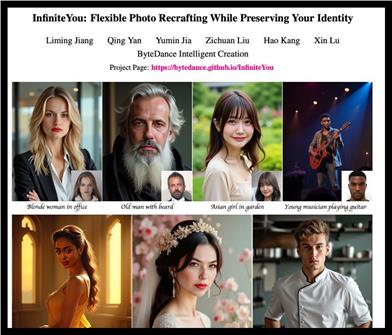

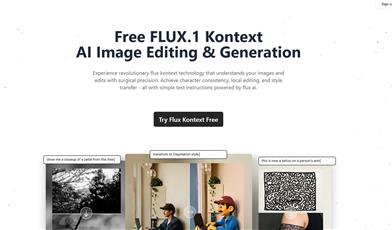

Featured AI Tools

Face To Many
Face to Many can transform a facial photo into multiple styles, including 3D, emojis, pixel art, video game style, clay animation, or toy style. Users simply upload a photo and choose the desired style to effortlessly create amazing and unique facial art. The product offers various parameters for user customization, such as noise intensity, prompt intensity, depth control intensity, and InstantID intensity.
Image Generation
4.8M
English Picks
Domoai
DomoAI is an image creation tool that offers a variety of pre-set AI models, allowing users to effortlessly achieve a consistent artistic style across all their projects. Its user-friendly and efficient design enables quick mastery, helping users craft exceptional visual assets. With DomoAI, users can experiment quickly and efficiently, boosting their creativity. Additionally, DomoAI's text-to-art feature transforms imagination into reality in just 20 seconds, bringing anime dreams to life.
Image Generation
2.7M