%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Half Illustration
Overview :
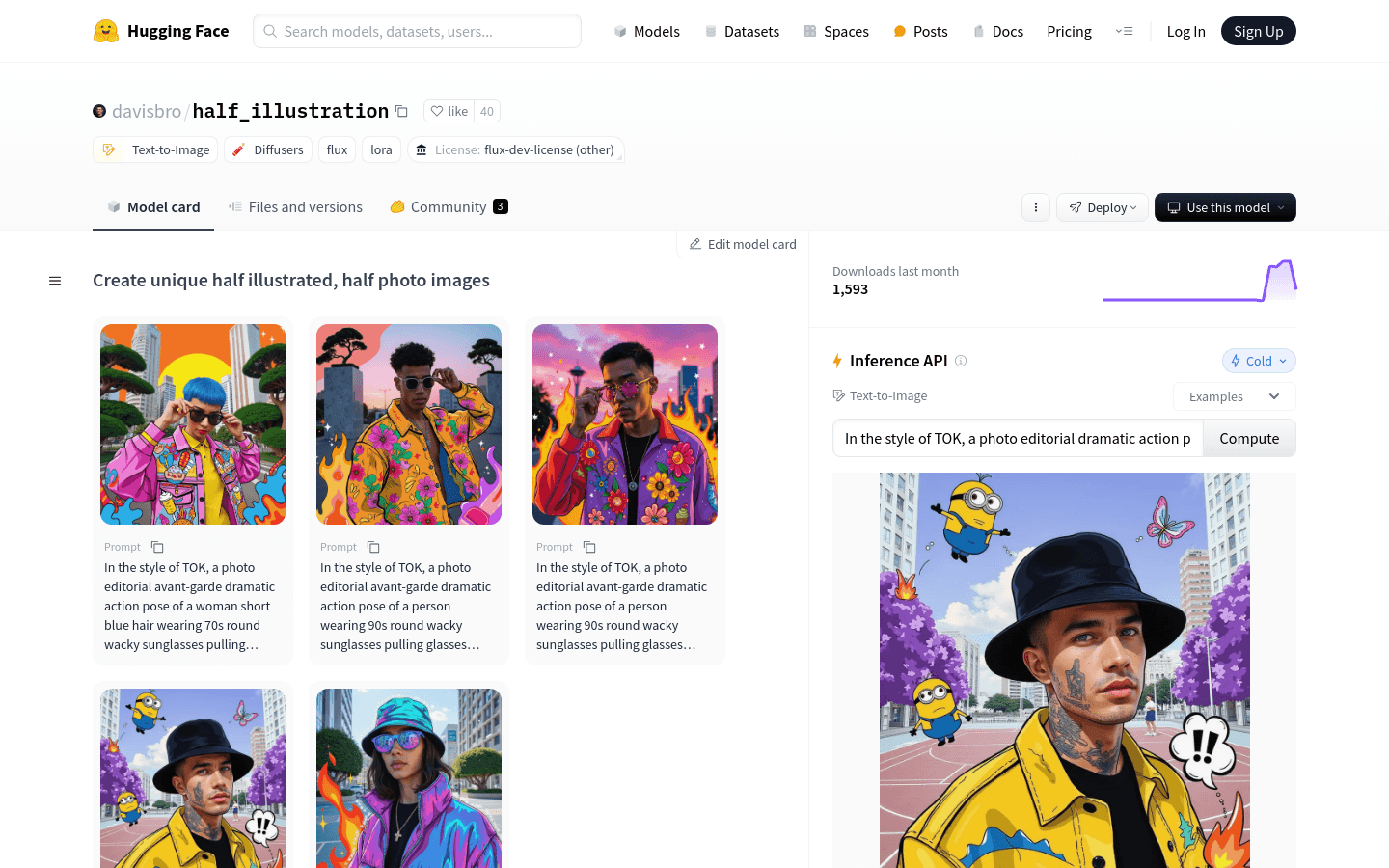
half_illustration is a text-to-image generation model based on the Flux Dev 1 model that combines photographic and illustrative elements to create artistically compelling images. This model utilizes LoRA technology, enabling style consistency through specific trigger words, making it ideal for artistic creation and design fields.
Target Users :
The primary audience includes artists, designers, and creative workers who can leverage the half_illustration model to quickly generate images with a unique style, enhancing their creative efficiency and the artistic expressiveness of their works.
Use Cases
Create a dramatic avant-garde pose of a woman wearing quirky round sunglasses from the 70s in TOK style at sunset in Tokyo.
Create a dramatic avant-garde pose of a person wearing quirky round sunglasses from the 90s in TOK style at sunset in Seattle.
Create a dramatic pose of a person with sharp eyes and facial tattoos in TOK style on a basketball court in Tokyo.
Create a dramatic pose of a person wearing a creative bucket hat in TOK style on a basketball court in Tokyo.
Features
Generate images by combining photographic and illustrative elements.
Maintain style consistency using specific trigger words.
Support execution on the Replicate platform.
Applicable in the fields of artistic creation and design.
Support for model download and local use.
Compatible with the diffusers library for easy integration into existing projects.
How to Use
1. Download the half_illustration model files.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Use AutoPipelineForText2Image from the diffusers library to load the model.
3. Load the LoRA weights using the pipeline.load_lora_weights method.
4. Input descriptive text using the pipeline method to generate images.
5. Adjust text descriptions and generation parameters as needed for the ideal image outcome.
6. Save the generated images and edit or apply them further as necessary.














Featured AI Tools
Chinese Picks

Capcut Dreamina
CapCut Dreamina is an AIGC tool under Douyin. Users can generate creative images based on text content, supporting image resizing, aspect ratio adjustment, and template type selection. It will be used for content creation in Douyin's text or short videos in the future to enrich Douyin's AI creation content library.
AI image generation
9.0M

Outfit Anyone
Outfit Anyone is an ultra-high quality virtual try-on product that allows users to try different fashion styles without physically trying on clothes. Using a two-stream conditional diffusion model, Outfit Anyone can flexibly handle clothing deformation, generating more realistic results. It boasts extensibility, allowing adjustments for poses and body shapes, making it suitable for images ranging from anime characters to real people. Outfit Anyone's performance across various scenarios highlights its practicality and readiness for real-world applications.
AI image generation
5.3M