%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Turtle Benchmark
簡介 :
Turtle Benchmark是一款基於'Turtle Soup'遊戲的新型、無法作弊的基準測試,專注於評估大型語言模型(LLMs)的邏輯推理和上下文理解能力。它通過消除對背景知識的需求,提供了客觀和無偏見的測試結果,具有可量化的結果,並且通過使用真實用戶生成的問題,使得模型無法被'遊戲化'。
需求人群 :
Turtle Benchmark適用於需要評估和比較大型語言模型性能的研究者和開發者。它特別適合那些專注於模型的邏輯推理和上下文理解能力的專業人士,幫助他們更準確地瞭解模型在中文語境下的表現。
使用場景
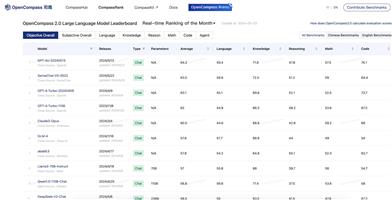
研究者使用Turtle Benchmark評估不同大型語言模型在特定邏輯推理任務上的表現。
開發者利用Turtle Benchmark測試他們的語言模型是否能夠準確理解並回答用戶的問題。
教育機構使用Turtle Benchmark作為教學工具,幫助學生理解大型語言模型的工作原理和性能評估方法。
產品特色
目標明確、無偏見:專注於推理能力,無需背景知識。
結果可量化:提供清晰、可測量的結果(正確/錯誤/未知),便於比較。
持續進化:使用真實用戶生成的問題,防止系統被操縱。
語言理解:測試模型理解上下文和進行邏輯推斷的能力。
使用簡單:通過簡單的命令行操作即可進行評估。
數據豐富:包含32個獨特的'Turtle Soup'故事和1537個人工標註的標籤。
結果解讀:通過散點圖比較不同模型在2-shot學習場景下的整體準確率和故事平均準確率。
使用教程
1. 進入Turtle Benchmark項目目錄。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 將.env.example文件重命名為.env並添加API密鑰。
3. 執行`python evaluate.py`命令以進行2-shot學習評估。
4. 如需進行零樣本(Zero-shot)評估,執行`python evaluate.py --shot 0`命令。
5. 查看評估結果,包括整體準確率和故事平均準確率。
6. 通過散點圖分析不同模型的性能差異。