%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
RF DETR
RF-DETRは、エッジデバイスに高精度とリアルタイム性能を提供することを目的とした、Transformerベースのリアルタイム物体検出モデルです。Microsoft COCOベンチマークで60 APを超える競争力のある性能と高速な推論速度を備え、様々な実用的なアプリケーションシナリオに適しています。RF-DETRは、現実世界の物体検出問題を解決することを目的としており、防犯、自動運転、スマート監視など、高効率かつ正確な検出が必要な業界に適しています。
["ラクシー パチャーン],["AI モデル]
51.6K
Sesame AI
Sesame AIは次世代の音声合成技術を代表し、高度な人工知能技術と自然言語処理を組み合わせることで、非常にリアルな音声、本物のような感情表現、自然な会話の流れを生成できます。本プラットフォームは、人間のような音声パターンを生成することに優れており、同時に一貫した性格特性を維持できるため、コンテンツ制作者、開発者、企業がアプリケーションに自然な音声機能を追加するのに最適です。具体的な価格と市場における位置付けはまだ不明ですが、その強力な機能と幅広い用途により、市場で高い競争力を有しています。
["料理-から-食べ物],["食べ物-から-料理]
46.9K
海外精選
Soundlabs AI
Soundlabs AI は、音楽プロデューサー向けのオーディオツールであり、リアルタイムのサウンドと楽器の変換に特化しています。高度な AI 技術により、ユーザーのサウンドを高品質のバーチャルシンガーまたは楽器の音色に変換し、あらゆるデジタルオーディオワークステーション(DAW)にシームレスに統合します。この技術の主な利点としては、リアルタイム変換、高品質オーディオ出力、豊富な音色モデルライブラリが挙げられます。Soundlabs AI は、音楽制作の柔軟性を高めるだけでなく、クリエイターに無限の創造の可能性を提供し、ポップミュージック、エレクトロニックミュージック、その他のジャンルにおいて重要な役割を果たします。価格設定は明確で、一括購入とサブスクリプションサービスを含む複数の購入オプションを提供し、さまざまなユーザーのニーズに対応しています。
音楽生成
45.0K
Verizon AI Connect
Verizon AI Connectは、Verizonが企業向けに提供するAIソリューションです。企業が強力なAI機能を最大限に活用できるよう支援します。Verizonネットワークの低遅延、高帯域幅、インテリジェントエッジ機能を活用し、リアルタイムAIワークロードをサポートします。オンデマンドで拡張可能な柔軟な接続オプションを提供し、動的なネットワークパスを最適化しながら、データのセキュリティとコンプライアンスを確保します。高度なネットワークインフラストラクチャとAI機能を統合することで、ビジネスイノベーションとデジタルトランスフォーメーションを推進するための強力なプラットフォームを提供します。
開発プラットフォーム
56.9K
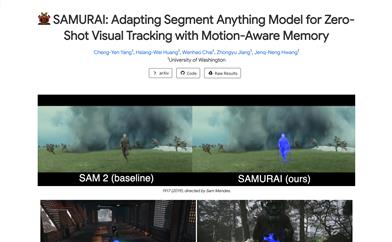
SAMURAI
SAMURAIは、Segment Anything Model 2 (SAM 2)をベースとしたビジュアルオブジェクトトラッキングモデルです。高速移動する物体や自己遮蔽する物体のビジュアルトラッキングタスクに特化して設計されています。時間的運動手がかりと運動知覚メモリ選択メカニズムを導入することで、物体の運動を効果的に予測し、マスク選択を最適化します。再トレーニングや微調整なしで、堅牢かつ正確なトラッキングを実現します。SAMURAIはリアルタイム環境で動作し、複数のベンチマークデータセットで強力なゼロショット性能を示しており、微調整なしで汎化できる能力を実証しています。評価において、SAMURAIは成功率と精度において既存のトラッカーと比較して大幅な向上を示しました。例えば、LaSOT-extではAUCが7.1%向上し、GOT-10kではAOが3.5%向上しました。さらに、LaSOTにおける教師あり学習手法と比較しても競争力を示しており、複雑なトラッキングシーンにおける堅牢性と動的環境における潜在的な実用性を強調しています。
ゼロショット学習
53.0K
高品質新製品
Segment Anything Model 2
Segment Anything Model 2 (SAM 2)は、Meta社のAI研究部門FAIRによって発表されたビジョンセグメンテーションモデルです。シンプルなトランスフォーマーアーキテクチャとストリーミングメモリ設計により、リアルタイムの動画処理を実現しています。ユーザーインタラクションを通じてモデル循環データエンジンを構築し、これまでにない規模の動画セグメンテーションデータセットSA-Vを収集しました。SAM 2はSA-Vでトレーニングされており、幅広いタスクとビジョン領域において高い性能を発揮します。
AI画像検出識別
53.3K
Sensevoice
SenseVoiceは、自動音声認識(ASR)、言語識別(LID)、音声感情認識(SER)、音声イベント検出(AED)など、複数の音声理解機能を備えた音声基礎モデルです。50種類以上の言語に対応し、高精度な多言語音声認識、音声感情認識、音声イベント検出に特化しており、Whisperモデルを凌駕する認識性能を実現しています。非自己回帰型エンドツーエンドフレームワークを採用することで、推論遅延が極めて低く、リアルタイム音声処理に最適です。
AI音声認識
101.0K
海外精選
Indexify
Indexifyは、リアルタイム抽出エンジンと事前構築済みの抽出アダプターを備えたオープンソースのデータフレームワークです。ドキュメント、プレゼンテーション、ビデオ、オーディオなど、さまざまな非構造化データから確実にデータを抽出できます。マルチモーダルデータに対応し、高度な埋め込みとチャンク化技術を提供し、Indexify SDKを使用してカスタムエクストラクターを作成できます。Indexifyは、セマンティック検索とSQLクエリを使用して画像、ビデオ、PDFを検索し、LLMアプリケーションが最も正確で最新のデータを取得できるようにします。さらに、ローカルでのプロトタイピングと、事前構成済みのKubernetesデプロイメントテンプレートを使用した本番環境での展開をサポートし、自動スケーリングと大量データの処理を実現します。
データ分析
53.0K
PAB
PABは、Pyramid Attention Broadcastを用いて動画生成プロセスを高速化するリアルタイム動画生成技術です。効率的な動画生成ソリューションを提供します。主な利点として、リアルタイム性、効率性、品質保証が挙げられます。リアルタイム動画生成機能が必要なアプリケーションシーンに適しており、動画生成分野に大きなブレークスルーをもたらします。
AI動画生成
91.4K
高品質新製品
Streamv2v
StreamV2Vは、ユーザープロンプトによってリアルタイムの動画から動画への翻訳(V2V)を実現する拡散モデルです。従来のバッチ処理とは異なり、StreamV2Vはストリーミング処理を採用することで、無限のフレーム数の動画を処理できます。その核心は、過去のフレームの情報を保存する特徴量バンクにあります。新しいフレームが入力されると、StreamV2Vは拡張自己注意機構と直接特徴量融合技術を用いて、類似する過去の情報を直接出力に融合します。特徴量バンクは、保存された特徴量と新しい特徴量を統合することで継続的に更新され、コンパクトで情報量の豊富な状態を維持します。StreamV2Vは、その適応性と効率性において優れており、微調整なしで画像拡散モデルとシームレスに統合できます。
AI動画生成
94.7K
Lookoncetohear
LookOnceToHearは、ユーザーが視覚的な認識だけで聞きたいターゲットスピーカーを選択できる革新的なスマートイヤホンインタラクションシステムです。この技術はCHI 2024でベストペーパーノミネーションを受賞しました。合成オーディオミキシング、頭部伝達関数(HRTFs)、およびバイノーラルルームインパルスレスポンス(BRIRs)を用いてリアルタイム音声抽出を実現し、ユーザーに新しいインタラクション方法を提供します。
AI音声認識
88.3K

Streamvoice
StreamVoiceは、言語モデルに基づいたゼロリップ音声変換モデルです。完全なソース音声なしでリアルタイム変換を実現します。全因果的コンテキスト認識言語モデルと時間独立の聴覚予測器を組み合わせることで、各時間ステップで意味的特徴と聴覚的特徴を交互に処理し、完全なソース音声への依存を解消します。ストリーミング処理におけるコンテキストの不完全性による性能低下を軽減するため、StreamVoiceは2つの戦略によって言語モデルのコンテキスト認識能力を高めています。1)教師付きコンテキスト予測:教師モデルを用いて現在と将来の意味的コンテキストを要約し、欠損コンテキストの予測を学習します。2)意味的マスキング:損傷した過去の意味的および聴覚的入力からの聴覚予測を促進し、コンテキスト学習能力を強化します。特筆すべきは、StreamVoiceが未来予測を一切必要としない、初の言語モデルベースのストリーミング型ゼロリップ音声変換モデルであることです。実験結果によると、StreamVoiceはストリーミング変換能力を備えつつ、非ストリーミング音声変換システムと同等のゼロリップ性能を維持しています。
AI音声合成
78.7K
Google AI MediaPipe
MediaPipeはGoogleが開発したオープンソースのクロスプラットフォーム機械学習フレームワークです。シンプルなAPIを通じて、開発者は様々なデバイス(スマートフォン、タブレット、ブラウザ、IoTデバイスなど)上で、複雑な機械学習モデルとアプリケーションを容易に構築できます。MediaPipeは複数のプログラミング言語に対応し、顔認識、ジェスチャー認識、物体追跡など、様々な事前トレーニング済みモデルを内蔵しています。開発者はこれらのモデルを迅速に統合して、インテリジェントなアプリケーションを開発できます。また、モデル圧縮と量子化技術にも対応しており、モデルサイズを10倍以上削減できるため、モバイル端末への機械学習モデルの展開に非常に有利です。総じて、MediaPipeは非常に使いやすく効率的な機械学習開発フレームワークです。
開発とツール
109.0K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
40.8K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.3K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
39.7K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.5K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.3K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.2K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M