%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Lookoncetohear
紹介 :
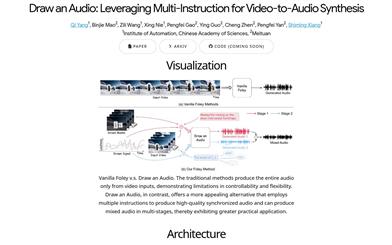
LookOnceToHearは、ユーザーが視覚的な認識だけで聞きたいターゲットスピーカーを選択できる革新的なスマートイヤホンインタラクションシステムです。この技術はCHI 2024でベストペーパーノミネーションを受賞しました。合成オーディオミキシング、頭部伝達関数(HRTFs)、およびバイノーラルルームインパルスレスポンス(BRIRs)を用いてリアルタイム音声抽出を実現し、ユーザーに新しいインタラクション方法を提供します。
ターゲットユーザー :
この製品は、騒音環境下での音声認識と抽出を必要とする研究者や開発者に向いています。例えば、聴覚障害者が騒音環境下で会話をより良く理解したり、多音声環境下で音声分析や処理を行うのに役立ちます。
使用シナリオ
会議で、LookOnceToHearを使用して特定の発話者の音声を聞き取ります。
騒がしい公共の場で、聴覚障害者が会話を集中して聞き取れるように支援します。
音声分析研究で、複数の音源を区別して抽出するために使用します。
製品特徴
ユーザーは、聞きたい音声をターゲットスピーカーの方を数秒間見ることで選択できます。
Scaperツールキットを使用して合成オーディオミックスを生成します。
自己完結型データセットとトレーニング用の.jams仕様ファイルを自由に提供します。
リアルタイム音声抽出とターゲット音声聴力モデルの評価をサポートします。
ユーザーがトレーニングと評価を容易に行えるよう、モデルのチェックポイントを提供しています。
騒音環境下での音声認識と抽出に適しています。
使用チュートリアル
提供された.zipファイルをdata/ディレクトリにダウンロードして解凍します。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
コマンドを実行してトレーニングプロセスを開始します。
.jams仕様ファイル上でScaperのgenerate_from_jams関数を使用してオーディオミックスを生成します。
ターゲット音声聴力モデルのチェックポイントをダウンロードしてロードし、評価を行います。
必要に応じてモデルパラメータを調整してパフォーマンスを最適化します。
実際のアプリケーションでは、ユーザーはターゲットスピーカーの方を見るだけで音声抽出を開始できます。