%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Flux Midjourney Mix2 LoRA
Flux-Midjourney-Mix2-LoRAは、深層学習に基づくテキストから画像を生成するモデルであり、自然言語による記述から高品質な画像を生成することを目指しています。このモデルはDiffusionアーキテクチャに基づいており、LoRA技術と組み合わせることで、効率的な微調整とスタイル化された画像生成を実現します。主な利点としては、高解像度出力、多様なスタイルのサポート、複雑なシーンに対する優れた表現力などが挙げられます。このモデルは、デザイナー、アーティスト、コンテンツクリエイターなど、高品質な画像生成を必要とするユーザーに適しており、創造的な構想の迅速な実現を支援します。
画像生成
60.4K
Shou Xin
shou_xinは、テキストから画像を生成するモデルです。ユーザーが提供したテキストプロンプトに基づいて、手訫スタイルの鉛筆スケッチ画像を生成できます。このモデルはdiffusersライブラリとLoRA技術を使用し、高品質の画像生成を実現しています。shou_xinモデルは、その独特の芸術的スタイルと効率的な画像生成能力により、画像生成分野で独自の地位を築いており、特定の芸術的スタイルの画像を迅速に生成する必要があるユーザーに最適です。
画像生成
78.1K
Regional Prompting FLUX
Regional-Prompting-FLUXは、訓練不要の地域プロンプティング拡散変換器モデルです。訓練なしで、拡散変換器(FLUXなど)にきめ細かい組み合わせによるテキストから画像への生成能力を提供します。このモデルは、効果が顕著であるだけでなく、LoRAおよびControlNetと高度に互換性があり、高速性を維持しながらGPUメモリの使用量を削減できます。
画像生成
54.4K

拡散トランスフォーマーのためのコンテキストlora
コンテキストLoRAは、拡散トランスフォーマー(DiT)のための微調整技術です。テキストだけでなく画像を組み合わせることで、タスク非依存性を維持しながら特定タスクへの微調整を実現します。この技術の主な利点は、元のDiTモデルを変更することなく、トレーニングデータのみを変更するだけで、小規模なデータセットで効率的な微調整が可能になることです。コンテキストLoRAは、複数の画像を統合的に記述し、タスク固有のLoRA微調整を適用することで、プロンプトの要求に沿った高忠実度の画像セットを生成します。この技術は、タスク非依存性を犠牲にすることなく、特定のタスクに対して高品質な画像を生成する強力なツールを提供するため、画像生成分野において重要な意味を持ちます。
画像生成
58.5K
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Lightは、テキストから画像を生成するAIモデルです。LoRA(Low-Rank Adaptation)技術を用いることで、ユーザーが提供するテキストプロンプトに基づき、高品質な画像を生成できます。この技術の重要性は、計算コストを抑えつつモデルのファインチューニングを実現し、生成画像の多様性と品質を維持できる点にあります。本モデルはStable Diffusion 3.5 Largeモデルをベースに、特定の画像生成ニーズに合うよう最適化?調整されています。
画像生成
62.1K
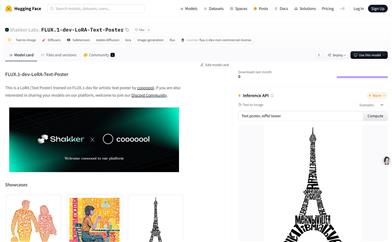
FLUX.1 Dev LoRA Text Poster
FLUX.1-dev-LoRA-Text-Posterは、Shakker-Labsが開発した、芸術的なテキストポスター生成を専門とするテキストから画像を生成するモデルです。LoRA技術を活用し、テキストプロンプトから画像を生成することで、ユーザーに革新的なアート作品制作方法を提供します。本モデルのトレーニングはcooooool氏によって行われ、Hugging Faceプラットフォーム上で共有されており、コミュニティの交流と発展を促進しています。非商業利用目的のflux-1-devライセンスに準拠しています。
画像生成
48.0K
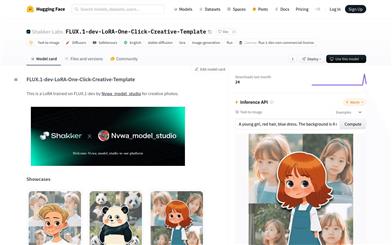
FLUX.1 Dev LoRA One Click Creative Template
FLUX.1-dev-LoRA-One-Click-Creative-Templateは、Shakker-Labsが提供するLoRAを用いて訓練された画像生成モデルです。クリエイティブな写真生成に特化しており、ユーザーのテキストプロンプトを創造的な画像に変換します。高度なテキストツーイメージ生成技術を採用しており、高品質な画像を迅速に生成する必要があるユーザーに最適です。Hugging Faceプラットフォームをベースとしており、容易に導入?利用できます。非商業利用は無料ですが、商業利用には該当するライセンス契約に従う必要があります。
AI画像生成
69.3K
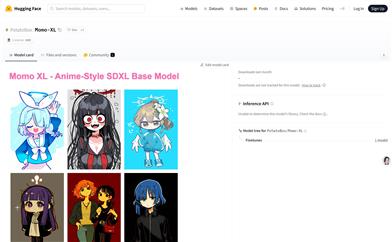
Momo XL
Momo XLはSDXLベースのアニメスタイルモデルで、微調整により、高品質でディテールが豊富で色彩鮮やかなアニメスタイル画像を生成できます。アーティストやアニメ愛好家に最適で、タグベースのプロンプトに対応し、出力結果の正確性と関連性を確保します。さらに、Momo XLはほとんどのLoRAモデルと互換性があり、多様なカスタマイズとスタイル変換を可能にします。
AI動画画像生成
54.6K
![iPhone Photo [FLUX] (iPhone写実風) - v1 final](https://p1.chinaz.com/ai-2024-10-11-202410110912015160.jpg/392/259/W/jpg)
Iphone Photo [FLUX] (iPhone写実風) V1 Final
iPhone Photo [FLUX]は、LoRA技術に基づいたAIモデルです。画像の写実性を高めることに特化しており、特にiPhoneの写真のような効果を再現することに優れています。iPhoneで撮影した写真だけでなく、他のソースの写真にも自然でリアルな視覚効果を加えることができます。Anibaaalによって開発され、2024年10月2日にCivitaiプラットフォームで公開されました。推奨設定は強度1で、1000件以上のいいねと375件以上のコメントがあり、高い人気を誇ります。
AI画像増強
48.6K
高品質新製品
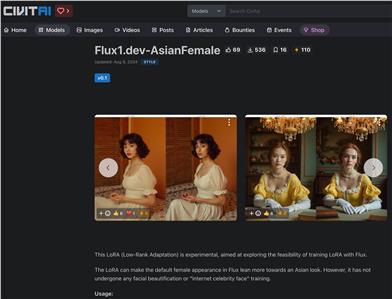
Flux1.dev AsianFemale
Flux1.dev-AsianFemaleは、Flux.1 DモデルをベースとしたLoRA(Low-Rank Adaptation)実験モデルです。訓練を通じて、Fluxモデルのデフォルトの女性像をアジア人の外見的特徴により近づけることを目指しています。顔の美化処理や有名人の顔画像による訓練は行っていないため、実験的なモデルであり、訓練上の課題や問題点が残されている可能性があります。
AI画像生成
94.4K
X Flux
x-fluxは、XLabs AIチームが公開した深層学習モデル訓練スクリプト集です。LoRAおよびControlNetモデルを含み、DeepSpeedを用いて訓練されます。512x512および1024x1024の画像サイズに対応し、対応する訓練設定ファイルとサンプルを提供しています。x-fluxモデル訓練は、画像生成の質と効率の向上を目指しており、AI画像生成分野において重要な意義を持ちます。
AIモデル
74.0K
Flux RealismLoRA
flux-RealismLoRAは、XLabs AIチームによって公開されたFLUX.1-devモデルに基づくLoRA技術で、リアルな画像を生成するために使用されます。テキストプロンプトから画像を生成し、アニメスタイル、ファンタジー、自然映画風など、様々なスタイルに対応しています。XLabs AIは、ユーザーがモデルのトレーニングと使用を容易に行えるよう、トレーニングスクリプトと設定ファイルを提供しています。
AI画像生成
64.9K
Mistral Finetune
mistral-finetuneは、LoRAトレーニングパラダイムに基づいた軽量コードライブラリです。大部分の重みを凍結したまま、追加の重みの1~2%のみを、低ランク行列摂動の形でファインチューニングできます。多GPU単一ノードのトレーニング設定に最適化されており、7Bモデルのような比較的小さいモデルであれば、単一のGPUでも十分です。このコードライブラリは、特にデータフォーマットに関して、シンプルで分かりやすいファインチューニングの入り口を提供することを目的としており、多様なモデルアーキテクチャやハードウェアタイプを網羅することを目的としていません。
AIモデル
48.9K
Llama 3 70B Gradient 524K アダプター
Llama-3 70B Gradient 524K アダプターは、Gradient AI Teamが開発したLlama-3 70Bモデルベースのアダプターです。LoRA技術を用いてモデルのコンテキスト長を524Kに拡張することで、長文データ処理におけるモデルのパフォーマンスを向上させます。このモデルは、NTK-aware補間とRingAttentionライブラリなどの高度なトレーニング技術を用いて、高性能計算クラスタ上で効率的にトレーニングされています。
AIモデル
48.6K

マルチlora合成
マルチLoRA合成は、複数の低ランク適応(LoRA)を組み合わせることで高品質な画像生成を実現する先進技術です。この手法は、モデルサイズを維持しつつ、画像の細部と多様性を向上させます。
AI画像生成
84.5K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
43.9K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
42.5K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
41.4K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
41.7K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
42.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
40.6K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M