%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# LoRA
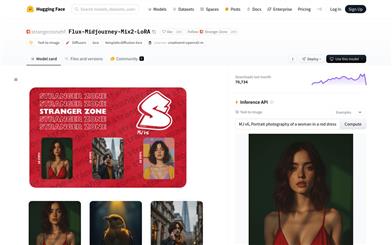
Flux Midjourney Mix2 LoRA
Flux-Midjourney-Mix2-LoRA is a deep learning-based text-to-image generation model designed to generate high-quality images from natural language descriptions. Built on a Diffusion architecture and incorporating LoRA technology, it enables efficient fine-tuning and stylized image generation. Its main advantages include high-resolution output, diverse style support, and excellent performance in complex scenes. This model is intended for users who need high-quality image generation, such as designers, artists, and content creators, facilitating the rapid realization of their creative concepts.
Image Generation
64.3K
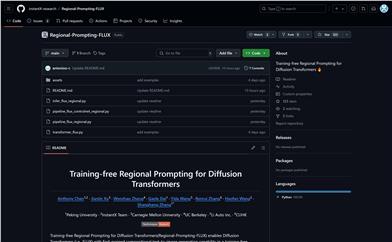
Regional Prompting FLUX
Regional-Prompting-FLUX is a training-independent regional prompting diffusion transformer model that provides fine-grained combined text-to-image generation capabilities for diffusion transformers (such as FLUX) without the need for training. The model not only delivers impressive results but also exhibits high compatibility with LoRA and ControlNet, minimizing GPU memory usage while maintaining high speed.
Image Generation
57.1K

In Context LoRA For Diffusion Transformers
In-Context LoRA is a fine-tuning technique for Diffusion Transformers (DiTs) that combines images rather than relying solely on text, allowing for fine-tuning on specific tasks while retaining task independence. The main advantage of this technique is its ability to effectively fine-tune on small datasets without any modifications to the original DiT model, solely by altering the training data. By jointly describing multiple images and applying task-specific LoRA fine-tuning, In-Context LoRA generates high-fidelity image sets that closely align with prompt requirements. This technique holds significant importance in the field of image generation as it provides a powerful tool for generating high-quality images for specific tasks without sacrificing task independence.
Image Generation
62.9K
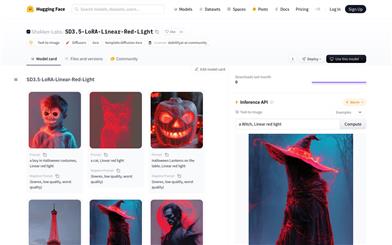
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Light is an AI model for text-to-image generation that utilizes LoRA (Low-Rank Adaptation) technology. This model can generate high-quality images based on user-provided text prompts, achieving efficient model fine-tuning at a lower computational cost while maintaining diversity and quality in generated images. It is based on the Stable Diffusion 3.5 Large model and has been optimized to meet specific image generation requirements.
Image Generation
63.8K
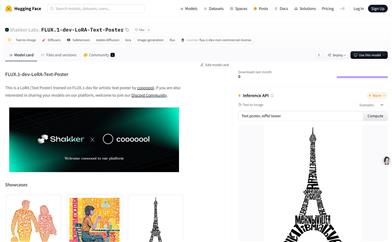
FLUX.1 Dev LoRA Text Poster
FLUX.1-dev-LoRA-Text-Poster is a text-to-image generation model developed by Shakker-Labs, specifically tailored for creating artistic text posters. Utilizing LoRA technology, it generates images from text prompts, providing users with an innovative way to craft artistic works. The model was trained by copyright user cooooool and is shared on the Hugging Face platform to foster community interaction and development. The model adheres to the non-commercial use Flux-1-dev licensing agreement.
Image Generation
48.6K
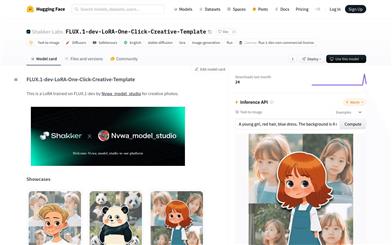
FLUX.1 Dev LoRA One Click Creative Template
FLUX.1-dev-LoRA-One-Click-Creative-Template is an image generation model trained with LoRA, provided by Shakker-Labs. This model focuses on creative photo generation, transforming user text prompts into imaginative images. It employs advanced text-to-image generation technology, making it ideal for users who need to quickly produce high-quality images. The model is hosted on the Hugging Face platform, allowing for convenient deployment and use. Non-commercial use is free, whereas commercial use requires adherence to the relevant licensing agreements.
AI image generation
71.5K
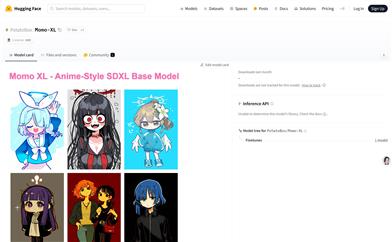
Momo XL
Momo XL is an anime style model based on SDXL, fine-tuned to generate high-quality, detailed, and vibrant anime images. It is especially suitable for artists and anime enthusiasts and supports tag-based prompts to ensure the accuracy and relevance of the output. Additionally, Momo XL is compatible with most LoRA models, allowing users to create diverse customizations and style transfers.
AI animation image generation
55.2K
![iPhone Photo [FLUX] (iPhone Realism) - v1 final](https://p1.chinaz.com/ai-2024-10-11-202410110912015160.jpg/392/259/W/jpg)
Iphone Photo [FLUX] (iPhone Realism) V1 Final
iPhone Photo [FLUX] is an AI model based on LoRA technology, designed to enhance the realism of images, especially excelling in mimicking iPhone photo effects. It not only enhances the quality of iPhone-captured photos but also adds a natural and realistic visual effect to non-iPhone photos. Developed by Anibaaal and released on October 2, 2024, this model belongs to the Civitai platform. A usage tip suggests setting the intensity to 1, and it boasts over 1000 likes and 375 comments, indicating its popularity.
AI Image Enhancement
51.9K
Fresh Picks
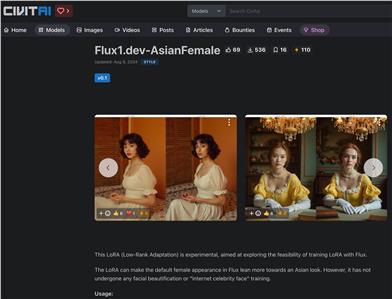
Flux1.dev AsianFemale
Flux1.dev-AsianFemale is an experimental Low-Rank Adaptation (LoRA) model based on the Flux.1 D model, designed to explore training methods that shift the default female imagery of the Flux model toward Asian features. This model has not undergone facial beautification or celebrity face training, making it experimental with potential training issues and challenges.
AI image generation
102.7K
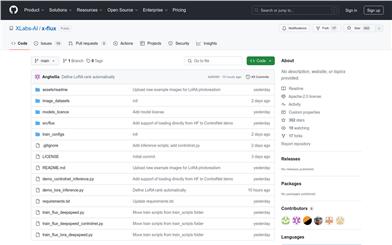
X Flux
x-flux is a collection of deep learning model training scripts released by the XLabs AI team, featuring LoRA and ControlNet models. These models leverage DeepSpeed for training and support image sizes of 512x512 and 1024x1024, along with corresponding training configuration files and examples. The x-flux model training aims to enhance the quality and efficiency of image generation, making it significant in the field of AI image generation.
AI Model
70.7K
Flux RealismLora
flux-RealismLora, developed by the XLabs AI team, utilizes LoRA technology based on the FLUX.1-dev model to generate realistic images. This technology generates images from text prompts and supports various styles, including animation, fantasy, and natural cinema styles. XLabs AI provides training scripts and configuration files to facilitate model training and usage.
AI image generation
65.1K
Mistral Finetune
mistral-finetune is a lightweight codebase that utilizes the LoRA training paradigm, allowing fine-tuning by training only 1-2% of the additional weights in the form of low-rank matrix perturbations while freezing most of the original weights. It is optimized for multi-GPU single-node training setups. For smaller models, like the 7B model, a single GPU is sufficient. This codebase aims to provide a simple and guided fine-tuning entry point, particularly in data formatting, and does not intend to cover a wide range of model architectures or hardware types.
AI Model
48.6K
Llama 3 70B Gradient 524K Adapter
The Llama-3 70B Gradient 524K Adapter is an extension of the Llama-3 70B model, developed by the Gradient AI Team. It is designed to extend the model's context length to over 524K through LoRA technology, thereby enhancing the model's performance in handling long text data. The model employs advanced training technologies, including NTK-aware interpolation and the RingAttention library, to efficiently train within high-performance computing clusters.
AI Model
48.3K

Multi LoRA Composition
Multi-LoRA Composition is an advanced image generation technology that produces high-quality images by combining multiple low-rank adaptors (LoRA). This approach enhances the details and diversity of the images while maintaining the size of the model.
AI image generation
82.0K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
45.5K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.3K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
44.2K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
43.6K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.6K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.7K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M