%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

SCENICモデル
SCENICは、テキスト条件に基づくシーンインタラクションモデルです。様々な地形を持つ複雑なシーンにも対応し、自然言語を用いたユーザー指定の意味的制御をサポートします。ユーザーが指定した軌跡を副目標、テキストプロンプトを指示として用いて3Dシーン内をナビゲートします。SCENICは階層的推論によるシーン理解と、動きとテキスト間のフレームアライメントを組み合わせることで、様々な動作スタイル間のシームレスな遷移を実現します。この技術の重要性は、現実の物理法則とユーザー指示に沿ったキャラクターナビゲーション動作を生成できる点にあり、仮想現実、拡張現実、ゲーム開発などの分野で大きな意義を持ちます。
ゲーム開発
44.7K

CHOIS
Controllable Human-Object Interaction Synthesis(CHOIS)は、言語記述、初期物体と人間の状態、疎な物体の経路点に基づいて、物体と人間の動きを同時に生成する高度な技術です。この技術は、特に正確な手と物体の接触や地面からの適切な支持が必要な場面において、現実的な人間の行動のシミュレーションに不可欠です。CHOISは、追加の監督情報として物体の幾何学的損失を導入し、サンプリング過程で接触制約を強制するための誘導項を設計することで、生成された物体の動きと入力された経路点のマッチング精度を向上させ、インタラクションの自然さを確保しています。
3Dモデリング
45.8K
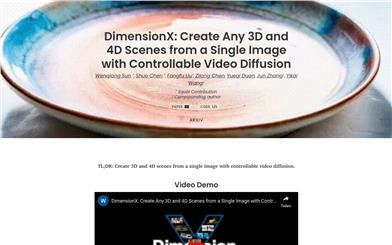
Dimensionx
DimensionXは、ビデオ拡散モデルに基づく3Dおよび4Dシーン生成技術です。一枚の写真から、制御可能な視点と動的な変化を伴う三次元および四次元のシーンを作成できます。この技術の主な利点には、高い柔軟性とリアルさが含まれ、ユーザーが提供するプロンプトに基づいて、様々なスタイルとテーマのシーンを生成できます。DimensionXの背景情報によると、研究者グループによって共同開発され、画像生成技術の発展を促進することを目的としています。現在、この技術は研究開発コミュニティに無料で提供されています。
3Dモデリング
67.3K

Vividdream
VividDreamは、単一の入力画像またはテキストプロンプトから、環境ダイナミクスを備えた探索可能な4Dシーンを生成できる革新的な技術です。まず、入力画像を静的な3D点群に拡張し、次にビデオ拡散モデルを使用してアニメーションビデオの集合を生成し、4Dシーン表現を最適化することで、一貫性のある動きと没入感のあるシーン探索を実現します。この技術は、多様な現実的な画像とテキストプロンプトに基づいた魅力的な4D体験の生成を可能にします。
AI画像生成
60.2K
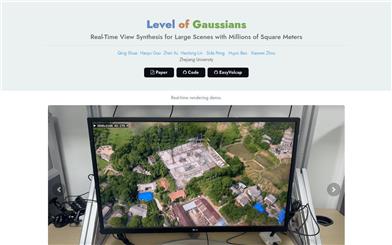
ガウシアンレベル(log)
ガウシアンレベル(LoG)は、3Dシーンを効率的にレンダリングするための新しい技術です。ツリー構造でガウシアンプリミティブを格納し、漸進的トレーニング戦略によって画像からエンドツーエンドで再構築することで、局所的最小値を効果的に克服し、数百万平方キロメートルにおよぶ領域のリアルタイムレンダリングを実現します。これは、大規模シーンレンダリングにおける重要な進歩です。
AI画像生成
54.1K
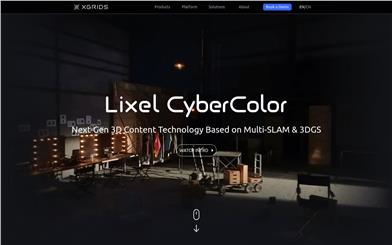
Lixel CyberColor
Lixel CyberColor(LCC)は、XGRIDS社が開発した最先端技術製品であり、3Dシーン制作に革命的な変化をもたらします。LCCは、Multi-SLAMテクノロジーとガウス溅射技術を用いて、映画級の高品質な無限大3Dシーンを自動生成します。その最大の特長は、リアルなディテールを正確に捉え、再現することにあり、仮想現実(VR)、ゲーム開発、映画制作など、様々な分野でリアルな体験を提供します。
XGRIDSは、ソフトとハードウェアを統合したソリューションとして、ミクロンからキロメートルレベルの高精度3D再構築とインテリジェント空間計算において卓越した能力を発揮します。Multi-SLAMアルゴリズムと最適化された3DGS技術を採用することで、超リアルな大型3Dモデルを自動作成し、没入感のある体験を提供します。最適化されたアルゴリズムにより、よりリアルなレンダリングを実現し、データ圧縮技術によってモデルサイズを90%削減します。LiDAR統合技術によりセンチメートル単位の高精度モデルを実現し、AI駆動の動的物体除去アルゴリズムも提供します。Unity、Unreal Engine、Web、モバイルプラットフォーム向けプラグインとSDKを提供し、3Dコンテンツ制作を強力にサポートします。
AI設計ツール
76.7K
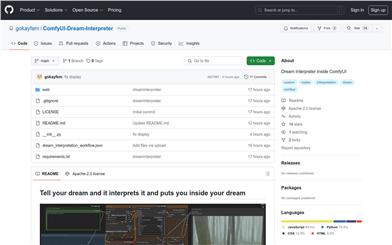
Comfyui Dream Interpreter
ComfyUI-Dream-InterpreterはComfyUIプラグインで、ユーザーが自身の夢の記述を入力すると、その夢の潜在的な意味を解釈し、パノラマ的な夢の情景画像を生成します。生成されるのは静止画だけでなく、3Dインタラクティブなキャンバスであり、ユーザーはまるでその場にいるかのように自身の夢の世界を探求できます。このプラグインは夢の記述、解釈、生成を組み合わせ、ユーザーに独特な夢体験を提供します。
AI画像生成
100.7K
Blockfusion
BlockFusionは、拡散モデルに基づいた3Dシーン生成モデルです。新しいブロックをシームレスにシーンに統合することができます。これは、完全な3Dシーンメッシュからランダムに切り取られた3Dブロックのデータセットをトレーニングすることで実現されています。ブロックごとのフィッティングにより、全てのトレーニングブロックは混合ニューラルフィールドに変換されます。このフィールドは、幾何学的特徴を持つ四面体と、符号付き距離値をデコードするための多層パーセプトロン(MLP)で構成されます。四面体を潜在的な四面体空間に圧縮し、ノイズ除去拡散処理を行うために、変分オートエンコーダが使用されます。潜在表現への拡散の適用により、高品質で多様な3Dシーンの生成が可能になります。シーン生成時にシーンを拡張する場合、既存のシーンと重なるように空のブロックを追加し、既存の潜在四面体を外挿して新しいブロックを埋めます。この外挿は、ノイズ除去の反復処理において、重なっている四面体の特徴サンプルを使用して生成プロセスを調整することで行われます。潜在四面体の外挿により、意味的および幾何学的に整合性のある遷移が生成され、既存のシーンと調和的に融合します。シーン要素の配置と配列を制御するために、2Dレイアウト調整メカニズムが使用されます。実験結果から、BlockFusionは多様で、幾何学的に整合性があり、高品質な屋内外の大規模な3Dシーンを生成できることが示されています。
AI画像生成
51.9K
3Dガウシアン?スプラッティングによるデブラーリング
3D Gaussian Splattingによるデブラーリングは、新しく提案されたラスタ化手法、3Dガウス、およびラスタ化に基づく、神経場を用いた新しいデブラーリングフレームワークです。小型の多層パーセプトロン(MLP)を使用することで、ぼやけた画像から詳細な画像をリアルタイムでレンダリングしながら再構築できます。本手法は、トレーニング中にK-最近傍(KNN)アルゴリズムを用いて追加の点を付加することで点群をより高密度にし、相対深度に基づいて3Dガウスを疎に間引きすることで、より多くの3Dガウスを保持します。複数の実験により、そのデブラーリングにおける有効性が確認されています。
AI画像増強
72.9K

Wonderjourney
WonderJourneyは、モジュール型のシーン生成フレームワークです。ユーザーが提供する位置情報に基づき、多様で相互に関連付けられた一連の3Dシーンを生成し、想像上の「奇妙な旅」を形成します。言語モデルを用いてシーンのテキスト説明を生成し、テキスト駆動型の点群生成プロセスによって連続した3Dシーンを作成し、大規模検証モデルで生成されたシーンを検証します。WonderJourneyは、様々なタイプとスタイルのシーンを含む、多様な視覚効果を表現します。
3Dモデリング
64.3K
Avataar
Avataarは、生成AI技術を用いて、没入感のある視覚コンテンツ制作機能を提供するプラットフォームです。コード不要で、3D空間シーン、仮想キャラクター、インタラクティブ動画を簡単に作成できます。Avataarはクリエイターのストーリーテリングを効率化し、消費者に優れた視覚体験を提供します。Webベースのノーコードソリューションを提供しており、Google、Apple、またはメールアドレスで簡単にログインできます。Avataarは強力なAI生成機能を備え、視覚的な創作を支援し、作業効率を大幅に向上させます。
AI設計ツール
54.1K
Instruct NeRF2NeRF
Instruct-NeRF2NeRFは、NeRFシーンを指示に基づいて編集するためのエディタです。画像条件付き拡散モデル(InstructPix2Pix)を用いて入力画像を段階的に編集し、同時に基盤となるシーンを最適化することで、編集指示に沿った最適化された3Dシーンを作成します。本手法は、大規模な現実世界のシーンの編集にも対応し、従来手法と比較してよりリアルで、目的意識の高い編集を実現できることを示しました。
AI画像生成
57.7K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
41.4K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.8K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.3K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.7K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.8K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.7K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M