%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Gaussiancity
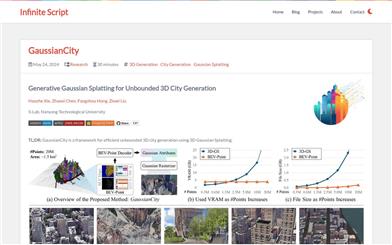
GaussianCityは、3Dガウス描画技術に基づいた、境界のない大規模な3D都市を効率的に生成することに特化したフレームワークです。この技術は、コンパクトな3Dシーン表現と空間認識型ガウス属性デコーダを通じて、従来の方法が大規模な都市景観を生成する際に直面するメモリと計算のボトルネックを解決します。主な利点として、単一の前方パスで高速に大規模な3D都市を生成できることがあり、既存技術を大幅に上回ります。本製品は南洋理工大学S-Labチームによって開発され、関連論文はCVPR 2025に掲載されています。コードとモデルはオープンソースであり、3D都市環境を効率的に生成する必要がある研究者や開発者向けです。
3Dモデリング
42.8K

Diffsplat
DiffSplatは、テキストプロンプトと単一視点画像から3Dガウシアン点群を高速に生成できる革新的な3D生成技術です。大規模に事前学習されたテキストツーイメージ拡散モデルを活用することで、効率的な3Dコンテンツ生成を実現しています。従来の3D生成手法におけるデータセットの限定性や、2D事前学習モデルの有効活用が難しいという問題を解決しつつ、3Dの一貫性を維持しています。DiffSplatの主な利点としては、高速な生成速度(1~2秒で完了)、高品質な3D出力、そして多様な入力条件への対応が挙げられます。本モデルは、特に高品質な3Dモデルの高速生成が必要な場面において、学術研究や産業用途で幅広い将来性を持っています。
3Dモデリング
50.0K

TRELLIS
TRELLISは、統一された構造化潜在表現と修正流変換器に基づくネイティブな3D生成モデルです。多様で高品質な3Dアセットの作成を実現します。このモデルは、疎な3Dメッシュと、強力なビジョン基礎モデルから抽出された高密度な多視点視覚特徴を統合することで、構造(幾何学)とテクスチャ(外観)情報を包括的に捉え、同時にデコード過程において柔軟性を維持します。TRELLISモデルは最大20億パラメータを処理でき、50万個もの多様なオブジェクトを含む大規模な3Dアセットデータセットでトレーニングされています。テキストまたは画像条件下で高品質な結果を生成し、規模の近い最新の方式を含め、既存の方法を著しく凌駕します。TRELLISはまた、柔軟な出力形式の選択と局所的な3D編集機能を提供しており、これは以前のモデルにはないものです。コード、モデル、データは公開されます。
3Dモデル
70.7K
世界生成
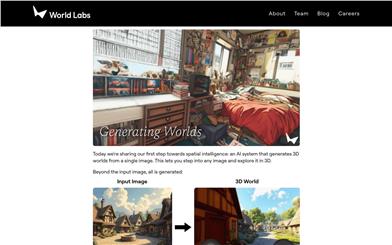
これは、一枚の画像から3D世界を生成できるAIシステムです。ユーザーは任意の画像に入り込み、3Dで探索できます。この技術は制御と一貫性を改善し、映画、ゲーム、シミュレーター、その他のデジタル表現の制作方法を一変させます。空間知能の第一歩を代表するもので、ブラウザでリアルタイムレンダリングされた生成世界を通じて、ユーザーは様々なカメラ効果、3D効果を体験し、名画を深く探求できます。
3Dモデリング
47.5K
Genxd
GenXDは、3Dおよび4Dシーン生成に特化したフレームワークです。日常生活でよく見られるカメラや物体の動きを利用して、一般的な3Dおよび4D生成の共同研究を行います。コミュニティには大規模な4Dデータが不足しているため、GenXDはまず、ビデオからカメラの姿勢と物体の動きの強度を取得するデータ策定プロセスを提案しました。このプロセスに基づいて、GenXDは大規模な現実世界の4DシーンデータセットであるCamVid-30Kを導入しました。すべての3Dおよび4Dデータを利用することで、GenXDフレームワークはあらゆる3Dまたは4Dシーンを生成できます。カメラと物体の動きを分離し、3Dおよび4Dデータからシームレスに学習するマルチビュー時間モジュールを提案しています。さらに、GenXDは、複数の条件付きビューをサポートするために、マスク潜在条件を採用しています。GenXDは、カメラの軌跡に従うビデオと、3D表現に昇格できる一貫性のある3Dビューを生成できます。様々な現実世界および合成データセットで広範な評価を行い、GenXDが3Dおよび4D生成において、従来の方法と比較して有効性と多機能性を備えていることを示しました。
3Dモデリング
50.0K
Hunyuan3d 1
Hunyuan3D-1は、テキストから3D、画像から3Dへの生成を可能にする、テンセントが開発した統合フレームワークです。このフレームワークは二段階の手法を採用しており、第一段階では多視点拡散モデルを用いて複数の視点からのRGB画像を高速に生成し、第二段階ではフィードフォワード再構成モデルを用いて3Dアセットを高速に再構成します。Hunyuan3D-1.0は速度と品質のバランスに優れており、生成時間を大幅に短縮しながら、生成されるアセットの品質と多様性を維持しています。
3Dモデリング
54.6K
中国語精選

テンセント混元3D
テンセント混元3Dは、既存の3D生成モデルが抱える生成速度と汎化能力の課題を解決することを目指した、オープンソースの3D生成モデルです。このモデルは、二段階の生成方法を採用しています。第一段階では、多視点拡散モデルを用いて多視点画像を高速に生成し、第二段階では、フィードフォワード再構成モデルを用いて3Dアセットを高速に再構成します。混元3D-1.0モデルは、3Dクリエイターやアーティストによる3Dアセットの自動生成を支援し、高速なシングル画像からの3D生成を可能にします。メッシュとテクスチャの抽出を含め、エンドツーエンドの生成を10秒以内で行えます。
3Dモデリング
85.3K

Dreammesh4d
DreamMesh4Dは、メッシュ表現とスパース制御変形技術を組み合わせた新しいフレームワークであり、単眼ビデオから高品質な4Dオブジェクトを生成できます。本技術は、陰的ニューラル放射場(NeRF)または明示的なガウス描画を基底表現として用いることで、従来の方法が抱えていた空間的?時間的一貫性と表面テクスチャ品質に関する課題を解決します。DreamMesh4Dは最新の3Dアニメーションワークフローから着想を得て、ガウス描画を三角メッシュ表面にバインドすることで、テクスチャとメッシュ頂点の微分可能な最適化を実現します。本フレームワークは、単一画像3D生成手法によって提供される粗いメッシュから開始し、スパースな点を均一にサンプリングすることで変形マップを構築し、計算効率の向上と追加の制約の提供を実現します。参照ビュー光度損失、スコア蒸留損失、その他の正則化損失を組み合わせた二段階学習により、静的表面ガウスとメッシュ頂点、そして動的変形ネットワークの学習を行います。DreamMesh4Dは、レンダリング品質と空間的?時間的一貫性の点で従来のビデオから4D生成手法を凌駕しており、そのメッシュベースの表現は最新のジオメトリワークフローと互換性があり、3Dゲームや映画業界における可能性を示しています。
AI動画生成
46.4K
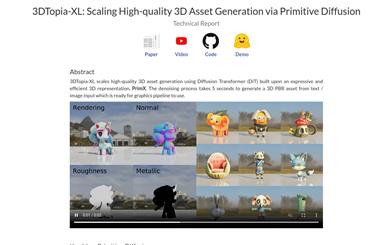
3dtopia XL
3DTopia-XLは、革新的な3D表現手法であるPrimXを用いた、拡散変換器(DiT)ベースの高品質3Dアセット生成技術です。形状、テクスチャ、マテリアルをコンパクトなN x Dテンソルにエンコードします。各トークンは、形状表面に固定されたボリュームプリミティブであり、符号付き距離関数(SDF)、RGB、マテリアルをボクセル化されたペイロードでエンコードします。このプロセスにより、テキスト/画像入力からわずか5秒で3D PBRアセットを生成し、グラフィックスパイプラインで使用できます。
AI画像生成
49.7K
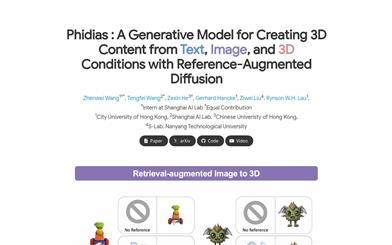
Phidias
Phidiasは、拡散技術を用いた参照強化型の革新的な3D生成モデルです。画像、テキスト、または3D条件から高品質な3Dアセットを生成し、数秒で完了します。メタコントロールネットによる条件強度の動的調整、動的参照ルーティング、自己参照強化という3つの主要コンポーネントを統合することで、生成品質、汎化能力、制御可能性を大幅に向上させています。Phidiasは、テキスト、画像、3D条件を用いた3D生成のための統一フレームワークを提供し、幅広い用途に対応します。
AI画像生成
45.0K

Vfusion3d
VFusion3Dは、事前学習済みのビデオ拡散モデルを基盤とした、拡張性の高い3D生成モデルです。3Dデータの取得困難性とデータ量の少なさという課題を解決するため、ビデオ拡散モデルを微調整して大規模な合成多視点データセットを生成し、単一画像から迅速に3Dアセットを生成できるフィードフォワード型3D生成モデルを学習させました。ユーザー調査では優れた結果を示しており、90%以上のユーザーがVFusion3Dで生成された結果を好む傾向にあります。
AI画像生成
46.6K

Ouroboros3d
Ouroboros3Dは、拡散モデルに基づく多視点画像生成と3D再構成を再帰的拡散プロセスに統合した、統一的な3D生成フレームワークです。本フレームワークは、自己条件付け機構を用いてこれらの2つのモジュールを共同学習させることで、相互に適応し、堅牢な推論を実現します。多視点ノイズ除去プロセスにおいて、多視点拡散モデルは、前の時間ステップで再構成モジュールによってレンダリングされた3D感知マップを追加的な条件として使用します。再帰的拡散フレームワークと3D感知フィードバックの組み合わせにより、幾何学的整合性が向上します。実験結果から、Ouroboros3Dフレームワークは、これら2つの段階を個別に学習する方法や、推論段階でそれらを組み合わせる既存の方法よりも優れた性能を示すことが明らかになりました。
AI画像生成
59.6K

Interactive3d
Interactive3Dは、インタラクティブな設計によりユーザーに正確な制御能力を提供する、高度な3D生成モデルです。このモデルは、二段階カスケード構造を採用し、異なる3D表現方法を利用することで、生成プロセスのあらゆる中間段階で修正や誘導を可能にします。その重要性は、ユーザーが3Dモデル生成プロセスを精密に制御できることであり、特定のニーズを満たす高品質な3Dモデルの作成を可能にします。
AI 3Dツール
47.2K

GRM
GRMは大規模な再構築モデルであり、疎なビュー画像から0.1秒で3Dアセットを復元し、8秒以内で生成できます。これは、Transformerベースのフィードフォワードモデルであり、多様なビュー情報を効率的に融合し、入力ピクセルを高精度に位置合わせされたガウス分布に変換します。これらのガウス分布は、シーンを表す密集した3Dガウス分布集合に逆投影できます。当社のTransformerアーキテクチャと3Dガウス分布の使用方法は、拡張性が高く効率的な再構築フレームワークを可能にします。数多くの実験結果から、当社の方法は再構築の品質と効率において他の代替案を上回ることが示されています。また、既存の多視点拡散モデルと組み合わせることで、テキストから3D、画像から3Dなどの生成タスクにおけるGRMの可能性も示しています。
AI画像生成
58.2K
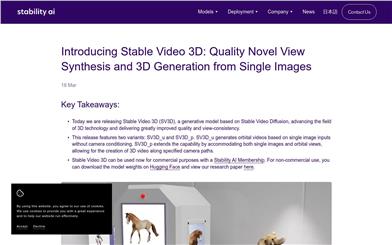
Stable Video 3D
Stable Video 3Dは、Stability AIが発表した新しいモデルであり、3D技術分野において目覚ましい進歩を遂げています。以前発表されたStable Zero123と比較して、大幅に品質が向上し、多視点対応も強化されました。カメラ情報がなくても、一枚の写真を入力として軌道動画を生成でき、指定したカメラパスに沿って3D動画を作成することも可能です。
AI動画生成
152.6K

LGM
LGMは、テキストプロンプトまたは単一視点画像から高解像度3Dモデルを生成するための新しいフレームワークです。その主要な着眼点は以下の通りです。(1) 3D表現:効率的で強力な表現として多視点ガウス特徴を提案し、これらを融合して微分可能なレンダリングを行うことができます。(2) 3Dバックボーン:テキストまたは単一視点画像入力から多視点拡散モデルを利用して生成できる、高スループットのバックボーンとして非対称U-Netを採用しています。広範な実験により、本手法の高忠実度と効率性が示されました。特筆すべきは、トレーニング解像度を512に引き上げた上で3Dオブジェクトの高速生成を維持し、高解像度3Dコンテンツ生成を実現したことでしょう。
3Dモデリング
72.0K
Hexagen3d
HexaGen3Dは、テキストプロンプトから高品質な3Dアセットを生成するための革新的な手法です。大規模な事前学習済み2D拡散モデルを利用し、事前学習済みテキストツーイメージモデルを微調整することで、6つの直交投影と対応する潜在的な三次元体を同時に予測し、その後、これらの潜在値をデコードしてテクスチャメッシュを生成します。HexaGen3Dはサンプルごとの最適化を必要とせず、テキストプロンプトから7秒以内で高品質かつ多様なオブジェクトを推論でき、既存の方法と比べて、品質と遅延のバランスが優れています。さらに、HexaGen3Dは、新しいオブジェクトや組み合わせに対しても高い汎化能力を備えています。
AI 3Dツール
49.1K

Gpteval3d
GPTEval3Dは、GPT-4Vを基盤としたオープンソースの3D生成モデル評価ツールです。テキストから3Dモデルを生成するモデルを自動的に評価し、ELOスコアを算出、既存モデルとの比較ランキングを提供します。シンプルで使いやすい設計となっており、ユーザーによるカスタム評価データセットもサポート。GPT-4Vの評価能力を最大限に活かし、3D生成タスク研究における強力なツールとなります。
AIモデル評価
74.8K

Flythroughs
Flythroughsは、AIと3D生成技術に基づくアプリケーションで、プロフェッショナルな3D Flythroughsを簡単に作成できます。世界最先端の3D生成NeRF技術を採用し、ビデオからリアルな3D体験を生成します。特別なトレーニングや機器は一切不要です。さらに、新しい3DカメラパスAIを搭載し、ワンクリックでリアルな3D体験を生成できます。不動産、建築、観光、エンターテインメントなど幅広い分野で活用でき、空間の流動性と独自性を効果的に表現できます。
AI動画生成
48.6K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
40.8K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.0K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.9K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.2K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.3K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.2K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M