%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Extractthinker
紹介 :
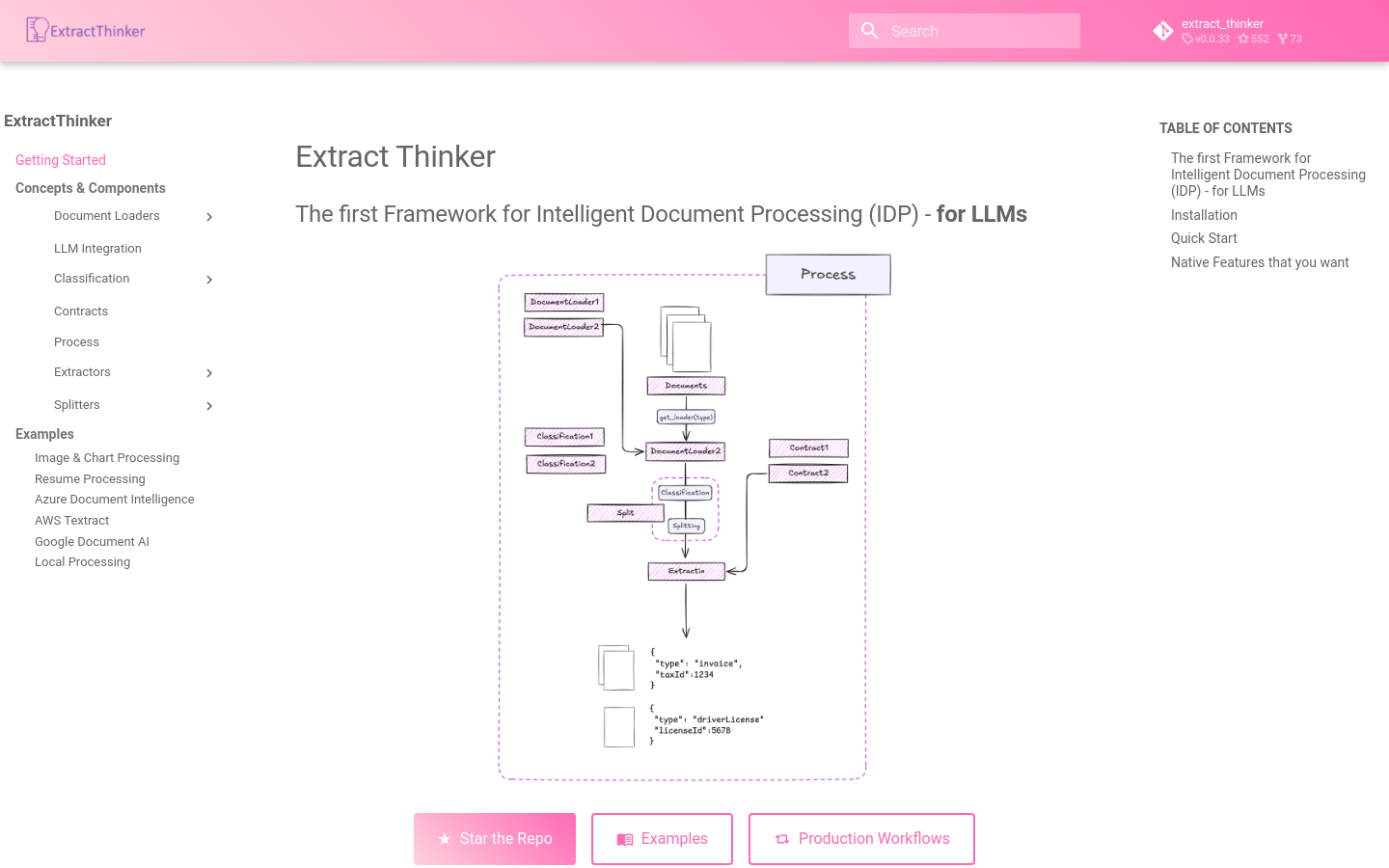
ExtractThinkerは、様々なドキュメントから構造化データを抽出し分類する、柔軟なインテリジェントドキュメントフレームワークです。ドキュメント処理ワークフローのORMのようなものです。「LLMのためのドキュメントインテリジェンス」または「インテリジェントドキュメント処理のLangChain」とも呼ばれています。このフレームワークは、大規模ドキュメントの分割や高度な分類など、ドキュメント処理に必要な特定機能を作成することを目的としています。
ターゲットユーザー :
大量のドキュメントを処理し、そこから構造化データを抽出する必要がある企業や個人(財務アナリスト、データサイエンティスト、法律専門家など)を対象としています。ExtractThinkerは、ドキュメント処理タスクの自動化、効率の向上、手動エラーの削減を支援する柔軟で強力なツールを提供するため、最適なソリューションです。
使用シナリオ
PDFからの請求書データ抽出:ExtractThinkerを使用して、PDFファイルから請求書番号、日付、合計金額を抽出します。
インテリジェントなドキュメント分類:大量のドキュメントを分類し、様々な種類のドキュメントを識別して適切に処理します。
PII検出と処理:機密ドキュメントを処理する際に、個人識別情報を自動的に識別して処理し、データプライバシーを確保します。
製品特徴
Pydanticによるデータ抽出:あらゆる種類のドキュメントから構造化データを抽出し、Pydanticモデルを使用して検証、カスタム機能、プロンプトエンジニアリング機能を実現します。
インテリジェントなドキュメント分類と分割:コンセンサス戦略、イミディエイト/レイジー分割、信頼度しきい値をサポートするインテリジェントなドキュメント分類と分割を行います。
PII検出:ドキュメント内の機密個人情報の自動検出と処理を行い、プライバシーを優先した方法と高度な検証を採用します。
LLMおよびOCR中立:必要に応じて、コスト要件に基づいて、様々なLLMプロバイダーとOCRエンジンを自由に選択、切り替えることができます。
使用チュートリアル
1. ExtractThinkerのインストール:pipを使用してextract_thinkerをインストールします。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 抽出するデータの定義:Contractを継承したクラスを作成し、抽出するデータフィールドを定義します。
3. エクストラクターの初期化:Extractorインスタンスを作成し、ドキュメントローダーとLLMモデルを読み込みます。
4. ドキュメントからのデータ抽出:Extractorのextractメソッドを使用して、指定されたドキュメントからデータ(Contractクラスを渡して)を抽出します。
5. 結果の出力:抽出されたデータ(請求書番号、日付、合計金額など)を出力します。










おすすめAI製品

Pseudoeditor
PseudoEditorは無料で使用できるオンライン擬似コードエディタです。構文の強調表示や自動補完などの機能を備えており、擬似コードの作成を容易にします。さらに、内蔵の擬似コードコンパイラ機能でテストすることも可能です。ダウンロード不要ですぐにご利用いただけます。
開発とツール
3.8M

Coze
Cozeは、次世代AIチャットボット構築プラットフォームです。AIチャットボットアプリケーションの迅速な作成、デバッグ、最適化が可能です。コーディング不要で、チャットボットを簡単に作成し、様々なプラットフォームに公開できます。豊富なプラグインも提供しており、データとの連携、アイデアをボットスキルへの変換、長期記憶の装備、会話の開始など、ボットの機能を拡張できます。
開発とツール
3.7M