ホーム
AIツール
AIモデル
MCP
AIニュース
JA
ホーム
すべてのカテゴリ
AI言語学習
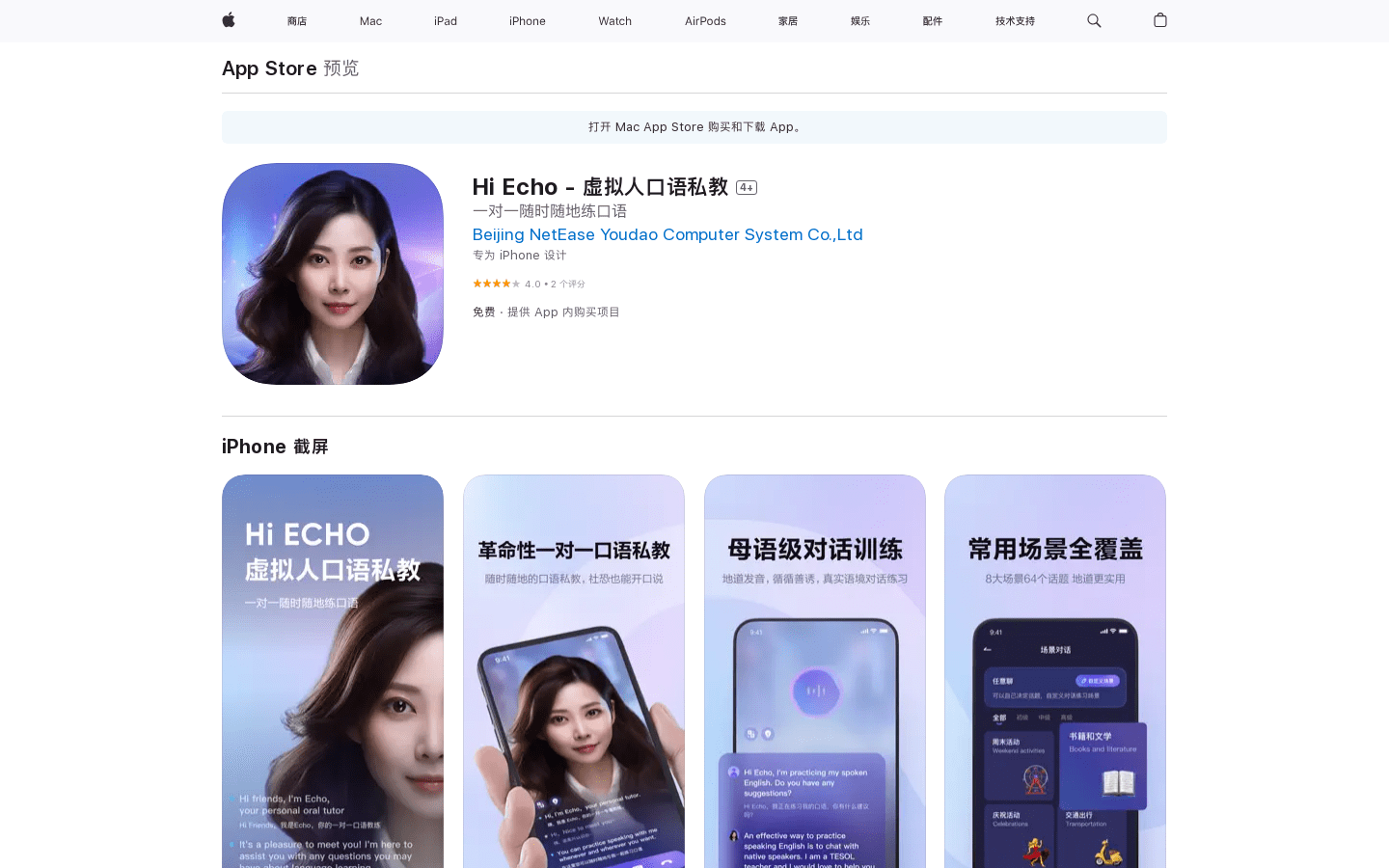
Hi Echo
Hi Echo
AI言語学習
AI音声認識
#英語学習
#英会話練習
#音声認識
#ストレス軽減
通常製品
商用
紹介 :
Hi Echoは、いつでもどこでもマンツーマンの英会話練習ができる学習アプリです。様々な会話シーンやトピックを網羅しており、システムがユーザーの発音を評価し、改善提案を提供します。これにより、英会話能力を迅速に高めることができます。人目を気にせず、いつでもどこでも英会話練習に励むことができます。
ターゲットユーザー :
本アプリは英語のスピーキング能力向上に役立ち、特に英検?TOEFL?IELTSなどのスピーキング試験対策に最適です。また、スキマ時間を使った英会話練習にも活用できます。
総訪問数:
124.3M
最も高い割合の地域:
US(28.84%)
ウェブサイト閲覧数 : 92.7K
サイトを開く
製品紹介
ウェブサイトトラフィック
類似のオープンソース製品
代替品
使用シナリオ
通勤?通学中の空き時間に英会話練習
IELTSやTOEFLのスピーキング試験対策として活用
英語のスピーキングに自信がない方は、日常的な練習にご利用ください
製品特徴
様々な英会話練習シーンを提供
音声認識によるユーザーの発音評価
英会話能力向上のためのアドバイスを提供
英会話練習の完全なレポートを提供
トラフィックソース
直接訪問
39.70%
外部リンク
29.80%
メール
0.13%
オーガニック検索
23.79%
ソーシャルメディア
3.16%
ディスプレイ広告
3.42%
最新のトラフィック状況
月間訪問数
1.17m
平均訪問時間
49.85
訪問あたりのページ数
1.54
直帰率
74.30%
総トラフィック傾向チャート
地理的トラフィック分布
月間訪問数
1.17m
United States
28.84%
Japan
6.55%
China
5.79%
United Kingdom
3.53%
India
3.48%
グローバル地理的トラフィック分布マップ
類似のオープンソース製品
Reverb
Reverbは、音声認識(ASR)にWeNetフレームワーク、話者分離にPyannoteフレームワークを用いた、オープンソースの音声認識と話者分離モデル推論コードです。詳細なモデルの説明を提供しており、Hugging Faceからモデルをダウンロードできます。Reverbは、開発者や研究者が様々な音声処理タスクを支援するための、高品質の音声認識と話者分離ツールを提供することを目的としています。
AI音声認識
高品質新製品
Whisper Large V3 Turbo
Whisper large-v3-turboは、OpenAIが開発した高度な自動音声認識(ASR)および音声翻訳モデルです。500万時間以上のラベル付け済みデータでトレーニングされており、ゼロショット設定で多くのデータセットやドメインに汎化できます。このモデルはWhisper large-v3を微調整したバージョンで、速度向上のためデコード層が32から4に削減されていますが、わずかに品質が低下する可能性があります。
AI音声認識
Omnisensevoice
OmniSenseVoiceは、SenseVoiceを最適化した音声認識モデルです。高速推論と高精度なタイムスタンプに特化し、よりスマートで高速な音声文字起こしを提供します。
AI音声認識
Crisperwhisper
CrisperWhisperは、OpenAIのWhisperモデルを高度に改良したモデルで、高速かつ正確な単語単位の音声認識を目的として設計されています。正確な単語レベルのタイムスタンプを提供します。元のWhisperモデルと比較して、CrisperWhisperは、つなぎ言葉、間、吃音、誤った開始など、発話されたすべての単語を単語単位で転写することに重点を置いています。TED、AMIなどの単語単位データセットで最高ランクを獲得しており、INTERSPEECH 2024で発表されました。
AI音声認識
高品質新製品
Seed ASR
Seed-ASRは、バイトダンス社が開発した大規模言語モデル(Large Language Model, LLM)に基づく音声認識モデルです。連続音声表現とコンテキスト情報をLLMに入力することで、LLMの能力を活用し、大規模な訓練とコンテキスト認識能力によって、複数領域、アクセント/方言、言語を含む包括的な評価セットでのパフォーマンスを大幅に向上させました。最近発表された大規模ASRモデルと比較して、Seed-ASRは中国語と英語の共通テストセットで10~40%の単語誤り率の低減を実現し、その強力な性能をさらに証明しています。
AI音声認識
Whisper Diarization
whisper-diarizationは、Whisperによる自動音声認識(ASR)、音声活動検出(VAD)、話者埋め込み技術を統合したオープンソースプロジェクトです。音声部分のみを抽出して話者埋め込みの精度を向上させ、Whisperで転写テキストを生成し、WhisperXでタイムスタンプの補正とアライメントを行い、時間ずれによる分離エラーを削減します。その後、MarbleNetを用いてVADと分離を行い無音部分を排除し、TitaNetを用いて話者埋め込みを抽出し各セグメントの話者を識別し、最後にWhisperXで生成されたタイムスタンプと結果を関連付けて、タイムスタンプに基づいて単語ごとの話者を検出し、句読点モデルを用いて微小な時間ずれを補正するために再アライメントを行います。
AI音声認識
Sensevoicesmall
SenseVoiceSmallは、自動音声認識(ASR)、言語識別(LID)、音声感情認識(SER)、および音声イベント検出(AED)を含む、複数の音声理解機能を備えた音声基礎モデルです。40万時間以上のデータで学習されており、50以上の言語に対応し、Whisperモデルを上回る認識性能を実現しています。小型モデルであるSenseVoice-Smallは非自己回帰型エンドツーエンドフレームワークを採用しており、推論遅延が極めて低く、10秒の音声処理にわずか70ミリ秒しかかかりません。これはWhisper-Largeと比べて15倍高速です。さらに、SenseVoiceは便利な微調整スクリプトと戦略、多重同時処理要求に対応するサービス展開パイプラインを提供しており、クライアント言語にはPython、C++、HTML、Java、C#などがあります。
AI音声認識
Emilia
Emiliaは、大規模音声生成研究向けに設計された、オープンソースの多言語野外音声データセットです。10万1千時間以上の高品質音声データ(6言語)と対応するテキスト転写を含み、脱線トーク、インタビュー、討論、スポーツ実況、オーディオブックなど、様々な話し方やコンテンツタイプを網羅しています。
AI音声認識
GPT 4による英単語辞書
GPT-4モデルによって生成された英単語学習ツール「DictionaryByGPT-4」は、8000語以上の単語を分析し、各単語について、意味、例文、語根?接辞、活用形、文化的背景、記憶テクニック、小話などを網羅的に提供することで、単語の由来、使用場面、記憶方法の深い理解を支援します。英語の語彙力と理解力を向上させたい学習者にとって最適な製品です。
AI言語学習
代替品
中国語精選
Enjoy App
Enjoy Appは、AI技術を用いて発音矯正、学習記録の追跡、豊富なオンライン教材による学習を支援する英語学習アプリです。煩雑な方法論を省き、実践的な学習を推奨。1000時間の集中的なトレーニングを通して英語習得を目指します。音声?動画の可視化されたシャドーイング、AIによる自然な会話、記憶力強化システムを搭載しており、英語学習の強力なツールです。課金モデルは機能利用ベースで、新規ユーザーには初期クレジットが提供され、追加課金でより多くのサービスが利用可能です。
AI言語学習
Reverb
Reverbは、音声認識(ASR)にWeNetフレームワーク、話者分離にPyannoteフレームワークを用いた、オープンソースの音声認識と話者分離モデル推論コードです。詳細なモデルの説明を提供しており、Hugging Faceからモデルをダウンロードできます。Reverbは、開発者や研究者が様々な音声処理タスクを支援するための、高品質の音声認識と話者分離ツールを提供することを目的としています。
AI音声認識
高品質新製品
Whisper Large V3 Turbo
Whisper large-v3-turboは、OpenAIが開発した高度な自動音声認識(ASR)および音声翻訳モデルです。500万時間以上のラベル付け済みデータでトレーニングされており、ゼロショット設定で多くのデータセットやドメインに汎化できます。このモデルはWhisper large-v3を微調整したバージョンで、速度向上のためデコード層が32から4に削減されていますが、わずかに品質が低下する可能性があります。
AI音声認識
海外精選
リアルタイムAPI
リアルタイムAPIは、OpenAIが提供する低遅延の音声インタラクションAPIです。開発者はこのAPIを使用して、アプリケーションに高速な音声対音声エクスペリエンスを構築できます。このAPIは自然言語の音声対音声対話をサポートし、ChatGPTの高機能音声モードと同様に、会話の中断を処理できます。WebSocket接続を介して機能呼び出しをサポートしており、音声アシスタントがユーザーのリクエストに応答し、アクションをトリガーしたり、新しいコンテキストを導入したりできます。このAPIの提供により、開発者は音声エクスペリエンスを構築するために複数のモデルを組み合わせる必要がなくなり、単一のAPI呼び出しで自然な対話エクスペリエンスを実現できます。
AI音声認識
Omnisensevoice
OmniSenseVoiceは、SenseVoiceを最適化した音声認識モデルです。高速推論と高精度なタイムスタンプに特化し、よりスマートで高速な音声文字起こしを提供します。
AI音声認識
高品質新製品
Deepgram音声エージェントapi
Deepgram音声エージェントAPIは、人間と機械間の自然でリアルな会話を実現する統合型音声対音声APIです。業界最先端の音声認識と音声合成モデルによって支えられており、自然でリアルタイムに音声の聞き取り、思考、発話を可能にします。Deepgramは、高度な生成AI技術を統合することで、スムーズで人間らしい音声エージェントを実現するビジネス環境を構築し、音声優先AIの未来を切り開くことを目指しています。
AI音声認識
Crisperwhisper
CrisperWhisperは、OpenAIのWhisperモデルを高度に改良したモデルで、高速かつ正確な単語単位の音声認識を目的として設計されています。正確な単語レベルのタイムスタンプを提供します。元のWhisperモデルと比較して、CrisperWhisperは、つなぎ言葉、間、吃音、誤った開始など、発話されたすべての単語を単語単位で転写することに重点を置いています。TED、AMIなどの単語単位データセットで最高ランクを獲得しており、INTERSPEECH 2024で発表されました。
AI音声認識
中国語精選
心辰lingo音声大規模言語モデル
心辰Lingo音声大規模言語モデルは、高度な人工知能音声モデルであり、効率的で正確な音声認識と処理サービスを提供することに特化しています。自然言語を理解し処理することで、人間と機械のインタラクションをよりスムーズで自然なものにします。西湖心辰の強力なAI技術を基盤としており、様々な場面で高品質の音声インタラクション体験を提供することに尽力しています。
AI音声認識
高品質新製品
Seed ASR
Seed-ASRは、バイトダンス社が開発した大規模言語モデル(Large Language Model, LLM)に基づく音声認識モデルです。連続音声表現とコンテキスト情報をLLMに入力することで、LLMの能力を活用し、大規模な訓練とコンテキスト認識能力によって、複数領域、アクセント/方言、言語を含む包括的な評価セットでのパフォーマンスを大幅に向上させました。最近発表された大規模ASRモデルと比較して、Seed-ASRは中国語と英語の共通テストセットで10~40%の単語誤り率の低減を実現し、その強力な性能をさらに証明しています。
AI音声認識
おすすめAI製品
Azure AI Studio 音声サービス
Azure AI Studioは、Microsoft Azureが提供する人工知能サービスのスイートで、音声サービスが含まれています。これらのサービスには、音声認識、音声合成、音声翻訳などの機能が含まれており、開発者がアプリケーションに音声関連のインテリジェント機能を統合するのに役立ちます。
AI音声認識
266.6K
Whisper
Whisperは、汎用的な音声認識モデルです。多様な音声データを用いて大規模に訓練されており、多言語音声認識、音声翻訳、言語識別をこなすマルチタスクモデルです。
AI音声認識
149.3K
未来を切り開く、あなたのAIソリューション知識ベース
English
简体中文
繁體中文
にほんご
© 2025
AIbase
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)