%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
Durt
DuRTはmacOSシステムに特化した音声認識と翻訳ツールです。ローカルAIモデルとシステムサービスを使用して音声のリアルタイム認識と翻訳を実現し、複数の音声認識方法をサポートすることで、認識精度と対応言語の範囲を向上させています。この製品は、結果をフローティングウィンドウ形式で表示するため、ユーザーは使用中に迅速に情報を入手できます。主な利点としては、高い精度、プライバシー保護(ユーザー情報の収集なし)、そして便利な操作性などが挙げられます。DuRTは、高効率な生産性ツールとして位置付けられており、多言語環境下でのコミュニケーションと作業をより効率的に行うことを目的としています。現在、Mac App Storeからダウンロードできますが、具体的な価格はページには明記されていません。
言語識別
44.4K
Elevenlabs Scribe
Scribeは、ElevenLabsが開発した高精度な音声テキスト変換モデルであり、現実世界のオーディオの予測不可能性に対処することを目的としています。99言語に対応し、単語レベルのタイムスタンプ、話者分離、オーディオイベントのマーキングなどの機能を提供します。Scribeは、FLEURSとCommon Voiceのベンチマークテストで卓越したパフォーマンスを示し、Gemini 2.0 Flash、Whisper Large V3、Deepgram Nova-3などのトップモデルを上回っています。従来のサービスが不十分な言語(セルビア語、広東語、マラヤーラム語など)におけるエラー率を大幅に削減しており、これらの言語は競合モデルではエラー率が40%を超えることが一般的です。Scribeは開発者向けにAPIインターフェースを提供しており、リアルタイムアプリケーションに対応する低遅延バージョンも近日中にリリース予定です。
言語識別
46.1K

Step Audio
Step-Audioは、業界初のプロダクションレベルのオープンソースインテリジェント音声対話フレームワークであり、音声理解と生成能力を統合し、多言語対応、感情表現、方言、話速、リズムスタイルの制御をサポートしています。そのコアテクノロジーには、130Bパラメータのマルチモーダルモデル、生成データエンジン、精密音声制御、拡張インテリジェンスが含まれます。このフレームワークは、オープンソースモデルとツールを通じて、インテリジェント音声対話技術の発展を促進し、さまざまな音声アプリケーションシナリオに適用できます。
言語識別
62.4K

Fireredasr AED L
FireRedASR-AED-Lは、高効率と高性能な音声認識ニーズに応えるために設計された、オープンソースの産業レベル自動音声認識モデルです。本モデルは、アテンション機構に基づくエンコーダ?デコーダアーキテクチャを採用し、標準中国語、中国語の方言、英語など複数の言語に対応しています。公開されている標準中国語音声認識ベンチマークテストにおいて最高レベルの精度を達成し、歌の歌詞認識においても優れた性能を発揮します。主な利点として、高性能、低遅延、幅広い適用性があり、様々な音声対話シーンに適しています。オープンソースであるため、開発者は自由にコードを使用?変更でき、音声認識技術の発展を促進します。
言語識別
48.3K
Fireredasr
FireRedASRは、Encoder-DecoderとLLMを統合したアーキテクチャを採用した、オープンソースの工業レベル標準中国語自動音声認識モデルです。高性能と高効率のニーズに対応するため、FireRedASR-LLMとFireRedASR-AEDの2つのバリアントが含まれています。このモデルは標準中国語ベンチマークテストで優れた性能を示し、方言や英語の音声認識にも良好な結果を示します。スマートアシスタント、動画字幕生成など、効率的な音声テキスト変換を必要とする工業レベルのアプリケーションに適しています。モデルはオープンソースであるため、開発者は容易に統合および最適化できます。
言語識別
46.9K
Pengchengstarling
PengChengStarlingは、多言語自動音声認識(ASR)に特化したオープンソースツールキットで、icefallプロジェクトをベースに開発されています。データ処理、モデル訓練、推論、微調整、デプロイといったASRの全プロセスをサポートしています。パラメータ設定の最適化とRNN-Transducerアーキテクチャへの言語IDの統合により、多言語ASRシステムのパフォーマンスを大幅に向上させています。主な利点としては、効率的な多言語サポート、柔軟な設定設計、強力な推論性能が挙げられます。PengChengStarlingのモデルは、様々な言語で優れた性能を発揮し、モデルサイズが小さく推論速度が非常に速いため、効率的な音声認識が必要な場面に最適です。
言語識別
49.1K
Whisper Turbo.online
Whisper Turboは、Whisper Large-v3モデルをベースに最適化された音声認識ツールで、高速な音声書き起こしに特化して設計されています。最先端のAI技術を活用することで、様々な音声源からの音声を効率的にテキストに変換し、複数の言語とアクセントに対応しています。このツールは無料で提供され、ユーザーの時間と労力の節約、生産性向上を支援することを目的としています。特に、ブログ主、コンテンツクリエイター、企業など、音声内容の迅速かつ正確な書き起こしが必要なユーザーを対象としており、音声からテキストへの変換ソリューションを簡単に提供します。
言語識別
49.1K
Realtimestt
RealtimeSTTは、音声をリアルタイムでテキストに変換できるオープンソースの音声認識モデルです。高度な音声活動検出技術により、音声の開始と終了を自動的に検出し、手動操作は不要です。さらに、ウェイクワードアクティベーション機能もサポートしており、特定のウェイクワードを発話することで音声認識を開始できます。このモデルは低遅延で高効率であり、音声アシスタントや会議記録など、リアルタイムの音声転写が必要なアプリケーションシナリオに適しています。Pythonベースで開発されており、統合と使用が容易で、GitHubでオープンソースとして公開されており、活発なコミュニティがあり、継続的に更新と改善が行われています。
言語識別
51.9K

Minmo
MinMoは、阿里巴巴グループの通義实验室が開発した、約80億パラメータを持つマルチモーダル大規模言語モデルです。シームレスな音声インタラクションの実現に特化しており、音声テキストアライメント、テキスト音声アライメント、音声音声アライメント、全二重インタラクションアライメントを含む複数段階のトレーニングを経て、140万時間におよぶ多様な音声データと幅広い音声タスクでトレーニングされています。MinMoは音声理解と生成における様々なベンチマークテストで最先端の性能を達成しており、同時にテキストの大規模言語モデルの能力も維持し、全二重対話(ユーザーとシステム間の同時双方向通信)をサポートしています。さらに、MinMoは、音声生成において従来のモデルを凌駕する、新規かつシンプルな音声デコーダを提案しています。MinMoの指示遵守能力は強化されており、ユーザーの指示に従って、感情、方言、話速などの詳細を含む音声生成を制御し、特定の音声を模倣することができます。MinMoの音声テキスト変換の遅延は約100ミリ秒、全二重遅延は理論上約600ミリ秒、実際は約800ミリ秒です。MinMoの開発は、従来のマルチモーダルモデルのアライメントにおける主な制約を克服し、ユーザーにより自然でスムーズ、人間味のある音声インタラクション体験を提供することを目的としています。
言語識別
47.5K
Betterwhisperx
BetterWhisperXは、WhisperXを改良した自動音声認識モデルです。高速な音声テキスト変換サービスを提供し、単語レベルの時間スタンプと話者識別機能を備えています。大量のオーディオデータ処理を行う研究者や開発者にとって非常に重要であり、音声データ処理の効率と精度を大幅に向上させることができます。OpenAIのWhisperモデルをベースに、更なる最適化と改良が加えられています。現在、このプロジェクトは無料でオープンソースであり、開発者コミュニティにより効率的で正確な音声認識ツールを提供することを目指しています。
言語識別
61.3K
Livekitプラグインターン検出器
LiveKit Plugins Turn Detectorは、LiveKitエージェント向けのプラグインです。カスタムのオープンウェイトモデルを使用して、ユーザーの発言がいつ終了したかを判断することで、エンドツーエンドの発言終了検出を実現します。従来の音声活動検出(VAD)モデルと比較して、このプラグインは、このタスクのために特別にトレーニングされた言語モデルを利用することで、より正確で堅牢な発言終了検出方法を提供します。現在のバージョンは英語のみをサポートしており、他の言語には使用できません。
言語識別
49.7K

Boldvoice Accent Oracle
BoldVoice Accent Oracleは、オンラインで利用できるツールです。短時間で英語を話すユーザーのアクセントを識別し、母語を推測します。この技術の重要性は、学習者が自身の発音の特徴を理解し、それに合わせた改善を行うことができる点にあります。製品の背景情報によると、BoldVoiceは技術を通じて人々のコミュニケーション能力向上を目指しており、このツールは教育や言語学習分野で活用される可能性があります。価格についてはウェブサイトでは明示されていませんが、教育的な性質を考慮すると、無料トライアルや基本サービスの無料提供、高度な機能の有料化といったモデルが考えられます。
言語識別
122.3K
Moonshine Web
Moonshine Webは、ReactとViteを用いて構築されたシンプルなアプリケーションです。高速かつ正確な自動音声認識(ASR)向けに最適化された強力な音声認識モデルであるMoonshine Baseを搭載しています。リソースに制限のあるデバイスにも対応可能です。このアプリケーションはブラウザ上でローカルに動作し、Transformers.jsとWebGPUによる高速化(またはWASMを代替として)を採用しています。サーバー不要でローカル音声認識を実現できる点が重要であり、音声データの迅速な処理が必要なアプリケーションに最適です。
言語識別
51.3K
高品質新製品
Omniaudio 2.6B
OmniAudio-2.6Bは、26億パラメーターのマルチモーダルモデルであり、テキストと音声の入力をシームレスに処理できます。Gemma-2B、Whisper turbo、およびカスタム投影モジュールを組み合わせることで、従来のASRとLLMモデルを直列に接続する方法とは異なり、これらの機能を効率的なアーキテクチャに統合し、最小限の遅延とリソース消費を実現しています。これにより、スマートフォン、ノートパソコン、ロボットなどのエッジデバイスで安全かつ迅速に音声テキストを直接処理できます。
言語識別
49.1K
Transcribro
Transcribroは、Androidプラットフォーム上で動作する、プライベートでデバイスローカルの音声認識キーボードおよびテキストサービスアプリです。OpenAI Whisperシリーズのモデルをwhisper.cppを使用して実行し、Silero VADによる音声活動検出機能を備えています。音声入力キーボードを提供し、音声によるテキスト入力が可能です。他のアプリからも明示的に使用でき、ユーザーが選択した音声テキスト変換アプリとして設定することもできます。一部のアプリでは、音声テキスト変換にTranscribroが使用される場合があります。Transcribroは、ユーザーにより安全でプライベートな音声テキスト変換ソリューションを提供することを目的としており、クラウド処理によるプライバシー侵害のリスクを回避します。このアプリはオープンソースであり、ユーザーは自由にコードの閲覧、修正、配布を行うことができます。
言語識別
53.5K
Universal 2
Universal-2はAssemblyAIが提供する最新の自動音声認識モデルです。前世代のUniversal-1を上回る精度と正確さで、人間の言語の複雑さをより的確に捉え、二次チェック不要の音声データを提供します。この技術の重要性は、製品体験に対するより鋭い洞察、迅速なワークフロー、そして一流の製品体験を提供することにあります。Universal-2は、専門用語認識、テキスト整形、英数字認識において顕著な改善が見られ、実運用における単語誤り率を削減します。
言語識別
45.8K
Moonshine
Moonshineは、リソースの限られたデバイス向けに最適化された音声テキスト変換モデルシリーズです。リアルタイムでのオンデバイスアプリケーション(現場での転写や音声コマンド認識など)に最適です。HuggingFaceが管理するOpenASRランキングで使用されているテストデータセットにおいて、Moonshineの単語誤り率(WER)は、同規模のOpenAI Whisperモデルを上回っています。さらに、Moonshineの計算需要は入力音声の長さに応じて変化するため、短い入力音声はより高速に処理されます。これは、すべての音声を30秒のブロックとして処理するWhisperモデルとは異なります。Moonshineは、10秒の音声断片をWhisperの5倍の速度で処理しながら、同等かそれ以上のWERを維持します。
言語識別
52.7K
GLM 4 Voice
GLM-4-Voiceは、清華大学チームが開発したエンドツーエンドの音声モデルです。日本語と英語の音声を直接理解し生成することで、リアルタイムの音声対話を可能にします。高度な音声認識と音声合成技術により、音声からテキスト、そして再び音声へのシームレスな変換を実現し、低遅延かつ高精度な対話能力を備えています。音声モーダルにおける知性と合成表現力に最適化されており、リアルタイムの音声インタラクションが必要な場面に適しています。
言語識別
60.7K
Whispo
Whispoは、人工知能技術を活用した音声書き起こしツールです。ユーザーの音声をリアルタイムでテキストに変換します。OpenAI Whisper技術を用いた音声認識機能を搭載し、カスタムAPIによる音声書き起こしや、大規模言語モデルによる書き起こし後処理にも対応しています。macOS(Apple Silicon)とWindows x64に対応し、すべてのデータはローカルに保存されるため、ユーザーのプライバシーを保護します。プログラミング、執筆、日常メモなど、大量のテキスト入力が必要なユーザーの作業効率向上を目指して設計されました。現在、無料トライアルを提供していますが、具体的な価格設定はページ上では明示されていません。
言語識別
49.4K
高品質新製品
Wisprによるflow
Flow by Wisprは、音声入力の効率を向上させることに特化したアプリケーションです。高度な音声認識技術により、従来のキーボード入力よりも3倍の速度で文字入力が可能です。作家、ジャーナリスト、学生、専門家など、テキストの迅速な記録と編集が必要なユーザーに最適です。現在、Appleシリコンチップ搭載のMacコンピューターのみ対応しており、将来的には他のプラットフォームにも展開予定です。
言語識別
52.7K
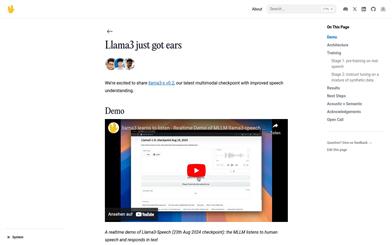
Llama3 S V0.2
Llama3-s v0.2は、Homebrew Computer Companyが開発したマルチモーダルチェックポイントであり、音声理解能力の向上に焦点を当てています。このモデルは、早期融合セマンティックマーキングの手法を用いて、コミュニティからのフィードバックを基に改善されています。これにより、モデル構造の簡素化、圧縮効率の向上、そして一貫した音声特徴抽出を実現しています。Llama3-s v0.2は複数の音声理解ベンチマークテストで安定したパフォーマンスを示しており、リアルタイムデモも提供されているため、ユーザーは実際にその機能を体験できます。モデルはまだ初期開発段階であるため、オーディオ圧縮に敏感であることや、10秒を超えるオーディオを処理できないなどの制限がありますが、チームは将来のアップデートでこれらの問題を解決する予定です。
言語識別
51.3K
高品質新製品
音声チャット
音声チャットは、音声ファイル処理に特化したウェブサイトです。講義、会議、面接などの音声ファイルをアップロードし、会話分析を行うことができます。高度な音声処理技術により、会話内容の要点を迅速に把握し、学習や業務効率の向上を支援します。
言語識別
56.6K
海外精選
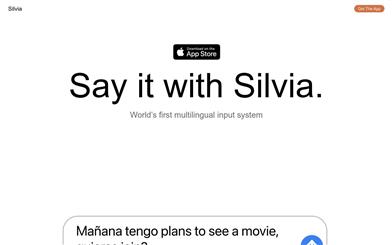
Silvia
Silviaは、ユーザーの発話方法に適応する音声入力システムです。ユーザーは様々な言語間を自由に切り替えられ、文中でもシームレスな切り替えが可能です。現在、英語とスペイン語に対応しており、フランス語、ルーマニア語、ドイツ語、オランダ語への対応も間近です。Apple App Storeの拡張機能として提供されるSilviaは、iMessage、WhatsApp、Signal、Telegram、Messengerなど、あらゆるチャットプラットフォームで使用でき、文字入力が必要なあらゆる場面で音声入力を活用できます。
言語識別
50.5K
高品質新製品

Say My Name!
Say My Name! は、楽しさとパーソナライズを重視した音声認識アプリです。高度な音声認識技術により、デバイスがユーザーの声、特にユーザーの名前を認識し、応答します。このアプリは、デバイスとのインタラクションを楽しくし、操作性を向上させます。Say My Name! の主な利点は、高精度な音声認識、パーソナライズされた音声コマンド設定、そしてユーザーフレンドリーなインターフェースです。
言語識別
46.1K
海外精選
Soundhound
SoundHoundは、革新的な音声認識能力とシンプルな応答方法によって、顧客体験の向上、ブランド価値の強化、そして深いパーソナライゼーションを実現する独立した音声AIプラットフォームです。25言語に対応し、地域の方言や言語のバリエーションも理解します。SoundHound AIは、現代自動車、Snap Inc.、Pandora、クアルコムなど、多くの有名ブランドから信頼されています。
言語識別
48.3K

Boff AI
boff.aiは、人工知能に基づいた音声認識と自然言語処理技術を用いたウェブサイトです。主な利点は、ユーザーの音声入力を迅速かつ正確に認識し、その意図を理解して適切な回答や提案を提供できることです。boff.aiは、インテリジェントな音声アシスタントサービスを提供し、ユーザーがより効率的に情報処理やタスク完了を行うことを支援することを目的としています。
言語識別
45.8K
Talkatoo.com
Talkatooは、平均的なタイピング速度の5倍の速さで内容を転写できる音声入力ソフトウェアです。ユーザーの時間を節約するのに役立ちます。3段階の制御レベルを提供しており、ユーザーはより自動化された方法を選択できます。Talkatooは、記録の検証、自動フォーマット、デスクトップ音声入力などの機能を備えており、獣医などの専門家に最適です。価格はニーズによって異なります。また、SOAP(主訴、現病歴、診断、処方)テンプレートへの自動変換にも対応し、医療記録の効率化を図ります。
言語識別
43.9K
April AI
April AIは、通話中にパーソナライズされたフィードバックを提供することで、スピーキング能力を向上させる製品です。会話をリアルタイムで処理し、通話終了後に要約とフィードバックをメールで送信します。April AIは、より効果的なプレゼンテーションとリーダーシップを身につけるのに役立ち、忙しいユーザーを考慮した設計で、既存の日常業務に簡単に統合できます。
言語識別
45.8K
Speechforms
Speechformsは、音声入力でフォームに入力できるアプリケーションです。キーボードを使わず、より直感的な方法でフォームへの入力が可能になり、未来のフォーム入力を実現します。Speechformsは無料トライアルを提供しています。具体的な価格については、公式ウェブサイトをご覧ください。
言語識別
51.1K
Abox
ABoxは、プライバシー保護、声帯損傷からの回復、性自認の多様な個人の自由な表現を支援する多機能音声変更アプリです。どのようなニーズにも、音声の自由を実現するソリューションを提供します。
言語識別
65.1K
- 1
- 2
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
38.9K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
38.9K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.1K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M