%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Medtrinity 25M
Overview :
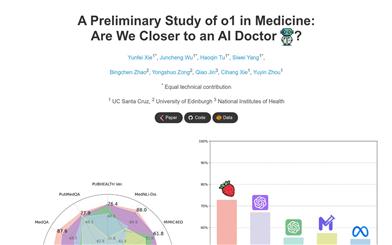
MedTrinity-25M is a large-scale multimodal dataset featuring multi-granular medical annotations. Developed by multiple authors, it aims to advance research in medical image and text processing. The dataset's construction involves steps such as data extraction and multi-granular text description generation, supporting various medical image analysis tasks, such as visual question answering (VQA) and pathology image analysis.
Target Users :
MedTrinity-25M is primarily aimed at researchers and developers in the fields of medical image processing and natural language processing. It offers a rich collection of medical images and textual data, facilitating model training, algorithm testing, and the development of new methods.
Use Cases
Researchers utilized the MedTrinity-25M dataset to train a deep learning model capable of identifying lesions in medical images.
Developers leveraged the dataset to create a system for automatically generating medical image reports.
Educational institutions use MedTrinity-25M as a teaching resource to help students understand the complexities of medical image analysis.
Features
Data extraction: Extract key information from collected data, including metadata integration to generate rough titles, region-of-interest localization, and medical knowledge collection.
Multi-granular text description generation: Utilize this information to prompt large language models to generate fine-grained annotations.
Model training and evaluation: Provide scripts for model training and evaluation, supporting pre-training and fine-tuning on specific datasets.
Model library: Offer various pre-trained models, such as LLaVA-Med++, supporting fine-tuning on specific medical image analysis tasks.
Quick start guide: Provide detailed installation and usage instructions to help users quickly begin using the dataset.
Paper publication: Relevant research findings have been published on arXiv, offering detailed insights into the research background and methods.
Community support: Acknowledges the support of various research and cloud computing projects, providing computational resources for the development and research of the dataset.
How to Use
1. Visit the GitHub page and clone the MedTrinity-25M dataset to your local machine.
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. Install the necessary packages and dependencies according to the quick start guide.
3. Download and install the base model LLaVA-Meta-Llama-3-8B-Instruct-FT-S2.
4. Follow the provided scripts for pre-training and fine-tuning the model.
5. Use the evaluation scripts to assess the performance of the trained model.
6. Utilize the dataset for custom algorithm development and testing according to your research needs.
Featured AI Tools

Tongyi Ren Xin
TongYi Ren Xin is a personal health assistant that provides health report queries, symptom inquiries, drug information, and disease inquiries. All content is AI-generated and intended for medical knowledge popularization only. It does not constitute professional medical advice. Users with health concerns should seek medical attention promptly and follow their doctor's instructions.
AI medical health
154.3K
Medtrinity 25M
MedTrinity-25M is a large-scale multimodal dataset featuring multi-granular medical annotations. Developed by multiple authors, it aims to advance research in medical image and text processing. The dataset's construction involves steps such as data extraction and multi-granular text description generation, supporting various medical image analysis tasks, such as visual question answering (VQA) and pathology image analysis.
AI medical health
85.8K