%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Multimodal

Omnigen2
OmniGen2 is an efficient multimodal generation model that combines visual language models and diffusion models, enabling functions such as visual understanding, image generation, and editing. Its open-source nature provides researchers and developers with a strong foundation to explore personalized and controllable AI generation.
Image Generation
40.8K
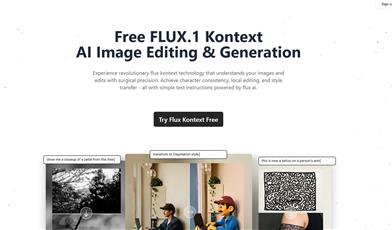
Fluxx.ai
FLUX.1 Kontext is a revolutionary multimodal AI model that combines text instructions with image editing and generation to enable precise localized editing while maintaining role consistency and style continuity. This product is suitable for professional workflows in marketing content creation, film production, and design.
AI Design Tools
39.5K
Chinese Picks
Hunyuancustom
HunyuanCustom is a multimodal customized video generation framework designed to generate specific-topic videos based on user-defined conditions. The technology excels in identity consistency and support for multiple input modes, capable of processing text, images, audio, and video inputs, applicable to various scenarios such as virtual human advertising and video editing.
Multimodal
38.9K

Liquid
Liquid is an autoregressive generative model that facilitates seamless integration of visual understanding and text generation by decomposing images into discrete codes and sharing feature space with text tokens. The main advantage of this model is the elimination of the need for externally pre-trained visual embeddings, reducing resource dependence, while simultaneously discovering a synergistic effect between understanding and generation tasks through the law of scaling.
Image Generation
40.6K
Fresh Picks

Internvl3
InternVL3 is a multimodal large language model (MLLM) open-sourced by OpenGVLab, possessing superior multimodal perception and reasoning capabilities. This model series includes 7 sizes ranging from 1B to 78B parameters, capable of simultaneously processing various information types such as text, images, and videos, demonstrating excellent overall performance. InternVL3 excels in industrial image analysis and 3D visual perception, with its overall text performance even surpassing the Qwen2.5 series. The open-sourcing of this model provides strong support for multimodal application development and helps promote the application of multimodal technology in more fields.
AI Model
37.3K

Dreamactor M1
DreamActor-M1 is a human animation framework based on Diffusion Transformer (DiT), designed to achieve fine-grained overall controllability, multi-scale adaptability, and long-term temporal consistency. The model, through blending guidance, can generate high-expressiveness and realistic human videos suitable for various scenarios from portrait to full-body animation. Its main advantages lie in its high fidelity and identity preservation, bringing new possibilities to human behavior animation.
Video Production
37.5K
English Picks
Gemini 2.5
Gemini 2.5 is Google's most advanced AI model, featuring efficient reasoning and coding capabilities. It can handle complex problems and excels in various benchmark tests. This model introduces novel thinking capabilities, combining an enhanced base model with post-training to support more complex tasks, aiming to provide strong support for developers and businesses. Gemini 2.5 Pro is available in Google AI Studio and the Gemini app, suitable for users requiring advanced reasoning and coding capabilities.
AI Model
44.4K
Mistral Small 3.1
Mistral-Small-3.1-24B-Base-2503 is an advanced open-source model with 24 billion parameters, supporting multilingual and long-context processing, suitable for text and visual tasks. It is the base model of Mistral Small 3.1, possessing strong multimodal capabilities and suitable for enterprise needs.
AI Model
69.0K

Mistralocr.net
Mistral OCR is an advanced optical character recognition API developed by Mistral AI, designed to extract and structure document content with unparalleled accuracy. It can handle complex documents containing text, images, tables, and equations, outputting results in Markdown format for easy integration with AI systems and Retrieval Augmented Generation (RAG) systems. Its high accuracy, speed, and multimodal processing capabilities make it excel in large-scale document processing scenarios, particularly suitable for research, legal, customer service, and historical document preservation fields. Mistral OCR is priced at $1 per 1000 pages for standard usage, with bulk processing reaching $2 per 1000 pages, and also offers enterprise self-hosting options to meet specific privacy needs.
API Services
68.4K
English Picks
Gemini Robotics
Gemini Robotics is an advanced artificial intelligence model from Google DeepMind, designed for robotic applications. Based on the Gemini 2.0 architecture, it fuses vision, language, and action (VLA), enabling robots to perform complex real-world tasks. The importance of this technology lies in its advancement of robots from the laboratory to everyday life and industrial applications, laying the foundation for the future development of intelligent robots. Key advantages of Gemini Robotics include strong generalization capabilities, interactivity, and dexterity, allowing it to adapt to different tasks and environments. Currently, the technology is in the research and development phase, and specific pricing and market positioning have not yet been defined.
AI Model
69.0K
R1 Omni
R1-Omni is an innovative multimodal emotion recognition model that enhances model reasoning and generalization capabilities through reinforcement learning. Developed based on HumanOmni-0.5B, it focuses on emotion recognition tasks and can perform emotion analysis using visual and audio modal information. Its main advantages include strong reasoning capabilities, significantly improved emotion recognition performance, and excellent performance on out-of-distribution data. This model is suitable for scenarios requiring multimodal understanding, such as sentiment analysis and intelligent customer service, and has significant research and application value.
Emotional companionship
80.6K
Chinese Picks

GO 1
AgiBot's general-purpose embodied base large model, GO-1, is a revolutionary AI model. Based on the innovative Vision-Language-Latent-Action (ViLLA) architecture, this model uses a multi-modal large model (VLM) and a Mixture-of-Experts (MoE) system to achieve efficient conversion from visual and language input to robot action execution. GO-1 can learn from human videos and real robot data, possesses strong generalization capabilities, and can quickly adapt to new tasks and environments with minimal or even zero data. Its main advantages include efficient learning ability, strong generalization performance, and adaptability to various robot bodies. The launch of this model marks a significant step towards the generalization, openness, and intelligence of embodied intelligence, and is expected to play an important role in commercial, industrial, and household applications.
AI Model
65.1K
English Picks
Openai Agents SDK
The OpenAI Agents SDK is a development kit for building autonomous agents. It leverages OpenAI's advanced model capabilities, such as advanced reasoning, multi-modal interaction, and new safety technologies, providing developers with a simplified way to build, deploy, and scale reliable agent applications. The toolkit supports orchestration of both single-agent and multi-agent workflows and integrates observability tools to help developers track and optimize the agent's execution process. Key advantages include easily configurable LLM models, an intelligent agent handover mechanism, configurable safety checks, and powerful debugging and performance optimization features. This toolkit is suitable for enterprises and developers who need to automate complex tasks, aiming to improve productivity and efficiency through agent technology.
Development & Tools
96.3K
Smolvlm2
SmolVLM2 is a lightweight video language model designed to generate related text descriptions or video highlights by analyzing video content. This model is efficient and has low resource consumption, making it suitable for running on various devices, including mobile devices and desktop clients. Its main advantages are the ability to quickly process video data and generate high-quality text output, providing strong technical support for video content creation, video analysis, and education. Developed by the Hugging Face team, it's positioned as an efficient, lightweight video processing tool and is currently in the experimental stage; users can try it for free.
Video Editing
70.1K
English Picks
Inception Labs
Inception Labs is a company focused on developing diffusion-based large language models (dLLMs). Its technology is inspired by advanced image and video generation systems such as Midjourney and Sora. Through diffusion models, Inception Labs offers speeds 5-10 times faster than traditional autoregressive models, higher efficiency, and stronger generative control. Its models support parallel text generation, can correct errors and hallucinations, are suitable for multimodal tasks, and excel in reasoning and structured data generation. The company is composed of researchers and engineers from Stanford, UCLA, and Cornell University and is a pioneer in the field of diffusion models.
AI Model
67.1K
English Picks

Aya Vision
Aya Vision is an advanced visual model developed by the Cohere For AI team, focusing on multilingual and multimodal tasks and supporting 23 languages. The model significantly improves the performance of visual and text tasks through innovative algorithmic breakthroughs such as synthetic annotation, multilingual data augmentation, and multimodal model fusion. Its main advantages include efficiency (performing well even with limited computing resources) and extensive multilingual support. The release of Aya Vision aims to advance the forefront of multilingual and multimodal research and provide technical support to the global research community.
AI model
54.1K

Unitok
UniTok is an innovative visual tokenization technology designed to bridge the gap between visual generation and understanding. Through multi-codebook quantization technology, it significantly improves the representation capability of discrete tokenizers, enabling them to capture richer visual details and semantic information. This technology breaks through the bottleneck of traditional tokenizers in the training process, providing an efficient and unified solution for visual generation and understanding tasks. UniTok excels in image generation and understanding tasks, such as achieving a significant zero-shot accuracy improvement on ImageNet. The main advantages of this technology include efficiency, flexibility, and strong support for multimodal tasks, bringing new possibilities to the field of visual generation and understanding.
AI Model
49.4K
Vidorag
ViDoRAG is a novel multimodal retrieval-augmented generation framework developed by Alibaba's Natural Language Processing team, designed for complex reasoning tasks involving visually rich documents. This framework significantly improves the robustness and accuracy of generative models through dynamic iterative reasoning agents and a Gaussian Mixture Model (GMM)-driven multimodal retrieval strategy. Key advantages of ViDoRAG include efficient handling of visual and textual information, support for multi-hop reasoning, and high scalability. The framework is suitable for scenarios requiring information retrieval and generation from large-scale documents, such as intelligent question answering, document analysis, and content creation. Its open-source nature and flexible, modular design make it a valuable tool for researchers and developers in the multimodal generation field.
AI Model
48.3K
Chinese Picks
Mochii AI
Mochii AI aims to drive human-AI collaboration through adaptive memory, customizable personalities, and seamless cross-platform integration. It supports multiple advanced AI models such as OpenAI, Claude, Gemini, DALL-E, and Stable Diffusion, enabling intelligent conversation, content creation, data analysis, and image generation. The product offers a free tier, requiring no credit card, suitable for professionals looking to enhance their productivity and creativity.
Personal Assistance
49.1K
M2RAG
M2RAG is a benchmark codebase for retrieval-augmented generation in multimodal contexts. It answers questions by retrieving multimodal documents, evaluating the ability of multimodal large language models (MLLMs) to leverage knowledge from multimodal contexts. The model is evaluated on tasks such as image captioning, multimodal question answering, fact verification, and image re-ranking, aiming to improve the effectiveness of models in multimodal contextual learning. M2RAG provides researchers with a standardized testing platform to help advance the development of multimodal language models.
AI Model
50.8K

Theoremexplainagent
TheoremExplainAgent is an AI-powered model focused on generating detailed multimodal explanatory videos for mathematical and scientific theorems. It helps users gain a deeper understanding of complex concepts by combining text and visual animations. This product uses Manim animation technology to generate long videos exceeding 5 minutes, addressing the shortcomings of traditional text explanations, particularly excelling in revealing reasoning errors. Primarily aimed at the education sector to enhance learners' understanding of STEM theorems, its pricing and commercialization strategy are not yet clearly defined.
Education
62.4K
Fresh Picks
Phi 4 Multimodal Instruct
Phi-4-multimodal-instruct is a multimodal foundational model developed by Microsoft, supporting text, image, and audio inputs to generate text outputs. Built upon the research and datasets of Phi-3.5 and Phi-4.0, the model has undergone supervised fine-tuning, direct preference optimization, and reinforcement learning from human feedback to improve instruction following and safety. It supports multilingual text, image, and audio inputs, features a 128K context length, and is applicable to various multimodal tasks such as speech recognition, speech translation, and visual question answering. The model demonstrates significant improvements in multimodal capabilities, particularly excelling in speech and vision tasks. It provides developers with powerful multimodal processing capabilities for building a wide range of multimodal applications.
AI Model
53.0K
Deepseek Japanese
DeepSeek is an advanced language model developed by a Chinese AI lab supported by the High-Flyer Foundation. It focuses on open-source models and innovative training methods. Its R1 series models demonstrate exceptional performance in logical reasoning and problem-solving, employing reinforcement learning and a mixture-of-experts framework to optimize performance and achieve efficient training at low cost. DeepSeek's open-source strategy has fostered community innovation while sparking industry discussion on AI competition and the impact of open-source models. Its free and registration-free access further lowers the barrier to entry, making it suitable for a wide range of applications.
AI Model
55.5K

Zerobench
ZeroBench is a benchmark specifically designed to evaluate the visual understanding capabilities of large multimodal models (LMMs). It challenges the limits of current models through 100 meticulously crafted and rigorously vetted complex questions, along with 334 sub-questions. This benchmark aims to address the shortcomings of existing visual benchmarks by offering a more challenging and high-quality evaluation tool. ZeroBench's primary strengths are its high difficulty, lightweight design, diversity, and high quality, enabling it to effectively differentiate model performance. Additionally, it provides detailed sub-question evaluation, helping researchers better understand the reasoning abilities of the models.
AI Model
53.5K
Magma
Magma, developed by Microsoft Research, is a multimodal foundational model designed to enable complex task planning and execution through the combination of vision, language, and action. Pre-trained on large-scale visual-language data, it possesses capabilities in language understanding, spatial intelligence, and action planning, allowing it to excel in tasks such as UI navigation and robot operation. This model provides a powerful foundation framework for multimodal AI agent tasks, with broad application prospects.
Smart Body
56.3K
English Picks
Grok 3
Grok 3 is the newest flagship AI model developed by Elon Musk's AI company, xAI. It represents a significant upgrade in computational power and dataset size, enabling it to handle complex mathematical and scientific problems and support multimodal input. Its primary advantage lies in its robust reasoning capabilities, providing more accurate answers and surpassing existing top-tier models in certain benchmarks. The launch of Grok 3 marks a further step in xAI's development in the AI field, aiming to provide users with more intelligent and efficient AI services. The model is currently primarily available through the Grok APP and X platform, with voice mode and enterprise API interfaces planned for the future. It is positioned as a high-end AI solution mainly targeted at users who require deep reasoning and multimodal interaction.
AI Model
141.0K

Clamp 3
CLaMP 3 is an advanced music information retrieval model that aligns features of musical scores, performance signals, audio recordings, and multilingual text through contrastive learning, supporting cross-modal and cross-lingual music retrieval. It demonstrates strong generalization capabilities by handling unaligned modalities and unseen languages. Trained on the large-scale dataset M4-RAG, which covers various global music traditions, the model supports a variety of music retrieval tasks such as text-to-music and image-to-music.
AI Model
47.5K
Videorag
VideoRAG is an innovative retrieval-augmented generation framework specifically developed for understanding and processing videos with very long contexts. It intelligently combines graph-driven textual knowledge anchoring with hierarchical multimodal context encoding, enabling comprehension of videos of unrestricted lengths. The framework dynamically builds knowledge graphs, maintains semantic coherence across multiple video contexts, and enhances retrieval efficiency through adaptive multimodal fusion mechanisms. Key advantages of VideoRAG include efficient processing of long-context videos, structured video knowledge indexing, and multimodal retrieval capabilities, allowing it to provide comprehensive answers to complex queries. This framework holds significant technical value and application prospects in the field of long video understanding.
Video Editing
51.6K
Medrax
MedRAX is an innovative AI framework specifically developed for intelligent analysis of chest X-rays (CXR). By integrating cutting-edge CXR analysis tools with a multimodal large language model, it can dynamically handle complex medical queries. MedRAX operates without requiring additional training, supports real-time CXR interpretation, and is suitable for various clinical scenarios. Its primary advantages include high flexibility, strong reasoning capabilities, and a transparent workflow. This product targets healthcare professionals, aiming to improve diagnostic efficiency and accuracy while promoting the practical application of medical AI.
Medical image analysis
78.4K
Chinese Picks

Qwen2.5 VL
Qwen2.5-VL is the latest flagship visual language model released by the Qwen team, representing a significant advancement in the field of visual language models. It can not only recognize common objects but also analyze complex content in images, such as text, charts, and icons, and supports understanding of long videos and event localization. The model performs exceptionally well in various benchmark tests, particularly excelling in document understanding and visual agent tasks, showcasing strong visual comprehension and reasoning abilities. Its main advantages include efficient multimodal understanding, powerful long video processing capabilities, and flexible tool invocation features, making it suitable for a variety of application scenarios.
AI Model
92.5K
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
42.0K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
44.4K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
41.7K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
42.8K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
41.4K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
42.0K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
41.1K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M