%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

使用場景
研究人員使用Qwen2-Audio進行語音識別和情感分析的學術研究
開發者利用Qwen2-Audio開發智能語音助手應用
企業集成Qwen2-Audio到客服系統中,提供自動化的語音服務
產品特色
支持自由的語音交互,無需文本輸入
能夠提供音頻和文本指令進行音頻分析
在多個標準基準測試中表現優異,如ASR、S2TT、SER等
即將發佈兩個模型系列:Qwen2-Audio和Qwen2-Audio-Chat
三階段訓練過程的架構概覽
提供所有評估腳本以復現結果
使用教程
訪問Qwen2-Audio的GitHub頁面,瞭解模型的基本信息和文檔
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
閱讀README.md文件,獲取模型的安裝和使用指南
根據評估腳本在本地環境中復現模型的性能
探索模型的兩種交互模式:語音聊天和音頻分析
將模型集成到自己的項目中,根據需要進行定製和優化










精選AI產品推薦
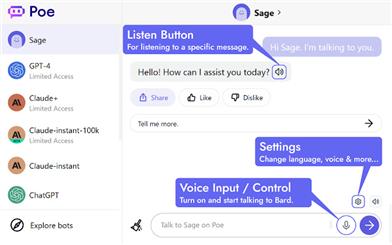
Talk To Poe AI
Talk to Poe AI是一個插件,為Poe的所有AI,包括Sage、GPT-4和Claude+,提供了語音控制和朗讀功能。您可以使用語音與Poe的AI進行對話,並以多種語言聽取其回覆。該插件還可以將AI的回覆以清晰自然的語音讀出,支持多種語言。安裝簡便,無需鍵盤輸入,讓您更輕鬆地與AI交流。
AI語音助手
421.7K
Omnireader AI Powered Free Text To Speech
OmniReader是一款AI語音朗讀工具,可以輕鬆地將網頁、EPUB、PDF等內容朗讀出來。它使用逼真的AI聲音,提供多語言支持,並具備將PDF和EPUB轉換為音頻的功能。OmniReader還可以與AI互動,通過語音與Claude或chatGPT對話。
AI語音助手
382.8K