%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

使用場景
在線零售商使用ViViD提供個性化的虛擬試穿服務,吸引顧客並提高銷售。
服裝設計師利用ViViD展示新設計,吸引潛在買家。
視頻內容創作者使用ViViD增加視頻內容的互動性和趣味性。
產品特色
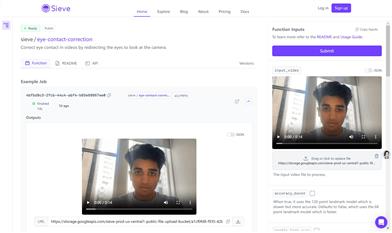
服裝編碼器:提取服裝的精細語義特徵。
注意力特徵融合機制:將服裝細節注入目標視頻中。
姿態編碼器:編碼姿態信號,學習服裝與人體姿態的交互。
時間模塊:插入文本到圖像穩定擴散模型中,生成連貫逼真的視頻。
大規模數據集:提供多樣化服裝類型和高分辨率的視頻試穿數據。
公開可用:代碼、數據集和權重將公開提供。
使用教程
1. 訪問ViViD項目頁面並下載所需的代碼和數據集。
%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%230080ff;%20}%20%3c/style%3e%3c/defs%3e%3cpath%20class='st0'%20d='M16.2,11.1c.4.5.4,1.2,0,1.8l-4.7,7.1h-3.8l5.3-8L7.6,4h3.8l4.7,7.1Z'/%3e%3c/svg%3e)
2. 根據提供的文檔安裝必要的依賴和環境。
3. 運行服裝編碼器提取服裝特徵。
4. 使用姿態編碼器處理目標視頻,提取人體姿態信息。
5. 利用ViViD模型將服裝特徵融合到目標視頻中。
6. 調整參數以優化視頻試穿效果。
7. 輸出最終的虛擬試穿視頻。







精選AI產品推薦
Motionshop
Motionshop是一個 AI 角色動畫的網站,它能夠根據上傳的視頻自動檢測視頻中的人物,並替換成 3D 卡通角色模型,生成有趣的 AI 視頻。該產品提供簡單易用的界面和強大的 AI 算法,讓用戶能夠輕鬆將自己的視頻內容轉化為生動有趣的動畫作品。
AI視頻編輯
6.4M
Video Subtitle Remover (VSR)
Video-subtitle-remover (VSR) 是一款基於AI技術,將視頻中的硬字幕去除的軟件。主要功能包括無損分辨率去除視頻中的硬字幕,通過AI算法模型對去除字幕的區域進行填充,支持自定義字幕位置去除,以及批量去除圖片水印文本。優勢在於無需第三方API,本地實現,操作簡便,效果顯著。
AI視頻編輯
835.2K