%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Stable Diffusion
Lanpaint
LanPaint is an image inpainting plugin for stable diffusion models. Through multiple rounds of iterative inference, it can achieve high-quality image inpainting without additional training. The importance of this technology lies in its provision of a solution that allows users to obtain accurate inpainting results without complex training, greatly reducing the barrier to entry. LanPaint is suitable for any stable diffusion model, including user-defined models, and has wide applicability and flexibility. It is mainly aimed at creators and developers who need high-quality image inpainting, especially those who want to get quick inpainting results without additional training.
Image Editing
64.6K
Animagine XL 4.0
Animagine XL 4.0 is an anime-themed generation model fine-tuned from Stable Diffusion XL 1.0. It has been trained on 8.4 million diverse anime-style images for a total of 2650 hours. The model focuses on generating and modifying anime-themed images based on text prompts, supporting various special tags to control different aspects of image generation. Its main advantages include high-quality image generation, rich anime style details, and precise restoration of specific characters and styles. The model was developed by Cagliostro Research Lab and is licensed under CreativeML Open RAIL++-M, allowing for commercial use and modification.
Image Generation
75.3K
Tryoffdiff
TryOffDiff is a high-fidelity garment reconstruction technology that generates standardized garment images from a single photo of an individual wearing clothing. Unlike traditional virtual try-ons, this technology aims to extract normative garment images, which poses unique challenges in capturing garment shape, texture, and complex patterns. TryOffDiff ensures high fidelity and detail retention by utilizing Stable Diffusion and SigLIP-based visual conditions. Experiments on the VITON-HD dataset demonstrate that its approach outperforms baseline methods based on pose transfer and virtual try-on while requiring fewer preprocessing and postprocessing steps. TryOffDiff not only enhances the quality of e-commerce product images but also advances the evaluation of generative models and inspires future work in high-fidelity reconstruction.
AI design tools
77.8K
SD3.5 Large IP Adapter
The SD3.5-Large-IP-Adapter is an IP adapter developed by the InstantX Team, based on the Stable Diffusion 3.5 Large model. This model analogizes image processing to text processing, boasting strong image generation capabilities and the potential for enhanced quality and effects through adapter technology. Its significance lies in promoting the advancement of image generation technology, particularly in creative work and artistic expression. Background information indicates that the model is a sponsored project by Hugging Face and fal.ai, adhering to the stabilityai-ai-community licensing agreement.
AI Models
80.0K
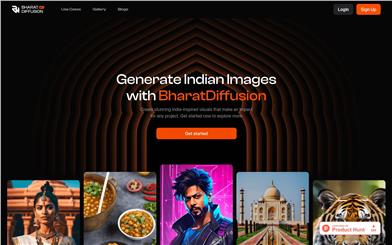
Bharatdiffusion
BharatDiffusion is an AI-based image generation model specifically fine-tuned to capture the diverse landscapes, cultures, and heritage of India, capable of producing high-quality images that reflect India's rich cultural tapestry. This model employs Stable Diffusion technology for all image generation, ensuring that the content resonates with the diversity and vibrancy of India.
Image Generation
61.5K
Sd Ppp
sd-ppp is a plugin that allows users to communicate between Adobe Photoshop and various Stable Diffusion interfaces such as SD/SDForge/ComfyUI. It supports multi-layer operations, including text and image layers, allows for handling multiple documents and instances of Photoshop, and enables work in specific areas of documents. This plugin is a powerful tool for designers and artists as it streamlines workflows, enhances creative efficiency, and allows them to leverage the robust capabilities of Stable Diffusion to enrich their design and artistic endeavors.
Stable Diffusion
128.9K
Comfyui Object Migration
Comfyui_Object_Migration is an experimental project focused on the Stable Diffusion (SD) model. This project achieves high consistency of the same object or character in a single generated image through the self-attention abilities of the DIT model. It has developed an efficient migration method by simplifying preprocessing logic, enabling the model to focus on the desired content and providing remarkable consistency. A migration model for clothing has been developed, allowing transitions from cartoon-style clothing to real-world styles or vice versa, stimulating design creativity through weight control.
DIT model
56.0K
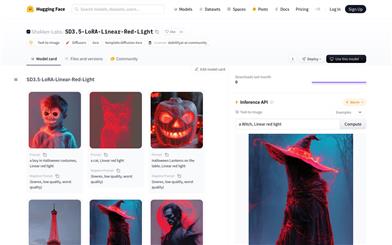
SD3.5 LoRA Linear Red Light
SD3.5-LoRA-Linear-Red-Light is an AI model for text-to-image generation that utilizes LoRA (Low-Rank Adaptation) technology. This model can generate high-quality images based on user-provided text prompts, achieving efficient model fine-tuning at a lower computational cost while maintaining diversity and quality in generated images. It is based on the Stable Diffusion 3.5 Large model and has been optimized to meet specific image generation requirements.
Image Generation
67.1K
Realanime
RealAnime - Detailed V1 is a LoRA model based on Stable Diffusion, specifically designed to produce realistic anime-style images. Utilizing advanced deep learning technology, it can understand and generate high-quality anime character images, catering to the needs of both anime fans and professional illustrators. Its significance lies in greatly enhancing the efficiency and quality of anime image generation, providing robust technical support for the anime industry. Currently, this model is available on the Tensor.Art platform, allowing users to utilize it online without the need for installation. Pricing permits users to unlock download rights through the Buffet plan, offering a more flexible usage option.
AI image generation
83.4K
FLUX.1 Dev Controlnet Canny Alpha
FLUX.1-dev-Controlnet-Canny-alpha is an image generation model based on control networks, belonging to the Stable Diffusion series. It utilizes advanced Diffusers technology to provide users with high-quality image generation services through text-to-image conversion. This model is particularly suitable for scenarios that require precise control over image details and styles.
AI image generation
73.4K
Flux RealismLora
flux-RealismLora, developed by the XLabs AI team, utilizes LoRA technology based on the FLUX.1-dev model to generate realistic images. This technology generates images from text prompts and supports various styles, including animation, fantasy, and natural cinema styles. XLabs AI provides training scripts and configuration files to facilitate model training and usage.
AI image generation
68.2K
English Picks

Amuse
Amuse 2.0 Beta is a desktop client software launched by AMD, designed specifically for users of AMD Ryzen? AI 300 series processors and Radeon? RX 7000 series graphics cards. It offers an AI image generation and optimization experience that combines the Stable Diffusion model with AMD XDNA? super-resolution technology, enabling high-quality AI image generation without complex installation or configuration.
Image Generation
107.9K
English Picks
Stability Matrix
Stability Matrix is a user-friendly desktop client designed to simplify the image generation process of Stable Diffusion. It helps users easily manage and generate images through one-click installation and seamless model integration, eliminating the need for in-depth technical knowledge. The tool supports multiple operating systems and effectively manages model resources, reducing the user’s learning curve. Stability Matrix offers stability and flexibility, making it especially suitable for image creators, designers, and digital artists.
Image Generation
81.7K
English Picks
Tensor.art
Tensor.Art is a free online image generation and model hosting platform that offers a variety of AI tools and functionalities. It enables users to generate images from text descriptions and customize and fine-tune AI models. Powered by advanced Stable Diffusion technology, the platform supports diverse node and workflow combinations, catering to the needs of users ranging from beginners to professional designers.
Image Generation
140.5K
Asyncdiff
AsyncDiff is a method for accelerating diffusion models through asynchronous denoising parallelization. It divides the noise prediction model into multiple components and distributes them across different devices, enabling parallel processing. This approach significantly reduces inference latency while having a minimal impact on generation quality. AsyncDiff supports a variety of diffusion models, including Stable Diffusion 2.1, Stable Diffusion 1.5, Stable Diffusion x4 Upscaler, Stable Diffusion XL 1.0, ControlNet, Stable Video Diffusion, and AnimateDiff.
AI image generation
55.8K
Easysdxlwebui
EasySdxlWebUi is an open-source project aimed at simplifying the installation and usage of SdxlWebUi, enabling users to more easily leverage tools like Stable Diffusion web UI and forge for image generation. The project supports multiple extended functionalities, allowing users to configure parameters and generate images through a web interface. It also supports customized and automated installation, making it suitable for users who need to quickly get started and efficiently generate images.
AI image generation
65.1K
Consistent Character
cog-consistent-character is an AI-powered image generation model that lets users create images of a given character in various poses. Leveraging Stable Diffusion technology and offering a user-friendly interface through ComfyUI, it enables even those without programming experience to easily generate high-quality images.
AI image generation
83.6K
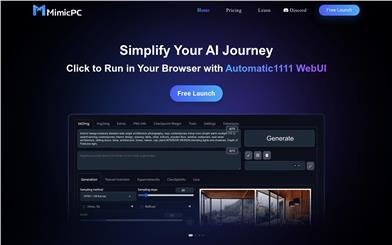
Mimicpc
MimicPC is a platform that runs on any device and browser, giving you access to and the ability to use popular open-source AI applications from around the world without the need for expensive hardware or technical knowledge of installation and maintenance.
AI information platform
59.3K

Https
ComfyFlow is a workflow application creation platform built on top of ComfyUI, enabling you to quickly build and share workflow applications with others. Leveraging the power of Stable Diffusion and ComfyUI technology, it offers simplicity, full hosting, and free usage.
Development & Tools
54.1K
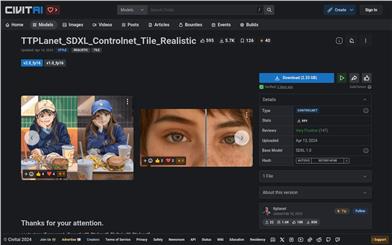
Ttplanet SDXL Controlnet Tile Realistic
This is a SDXL-based ControlNet Tile model trained on the Hugging Face Diffusers dataset and is compatible with Stable Diffusion SDXL ControlNet. It was initially developed for my own realistic model training, used in the ultimate upscaling process to enhance image details. With the right workflow, it can provide good results for high-detail, high-resolution image repair. As most open-source models lack SDXL Tile models, I decided to share this one. This model supports high-resolution repair, style transfer, and image enhancement functions, providing you with a high-quality image processing experience.
AI Image Generation
104.9K
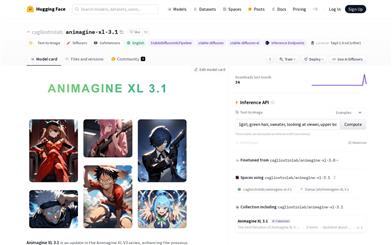
Animagine XL 3.1
Animagine XL 3.1 is a text-to-image generation model capable of producing high-quality anime-style images from text prompts. Built upon the foundation of Stable Diffusion XL, it has been specifically optimized for anime aesthetics. The model boasts an expanded knowledge base of anime characters, an optimized dataset, and new aesthetic tags, resulting in improved image quality and accuracy. It aims to provide a valuable resource for anime enthusiasts, artists, and content creators.
AI dynamic image generation
250.9K
Ip Composition Adapter
This adapter is designed for Stable Diffusion 1.5 to inject general image compositions into the model while largely ignoring style and content. For example, a portrait of a person raising their hand will generate an image of a completely different person raising their hand. The advantage of this adapter is that it allows for more flexible control, unlike Control Nets, which strictly match the control image. The product was conceived by POM with BANODOCO, trained by ostris, and released by them.
AI image generation
153.7K
Diffusion Client
The diffusion-client is an Android client for Stable Diffusion, offering robust image generation capabilities including text-to-image, image-to-image, and image repair features. The app supports various models and includes controls for fine-tuning the generation effects. Additionally, it features advanced functions such as history record management and tag extraction, and supports expansion plugins that can connect to models like Civitai.
AI image generation
427.8K
Creative Upscaler
Creative Upscaler is an AI-based image generator that allows anyone to quickly and easily create high-quality artworks. It integrates a variety of cutting-edge machine learning algorithms such as Stable Diffusion, DALL-E 2, VQGAN+CLIP, and supports generating images in various styles. Users simply provide a text description, and Creative Upscaler can automatically generate the images. Additionally, it features a Creative Image Aerator, which can convert low-resolution images into high-definition images. Creative Upscaler is completely free to use, boasts a large and active community, and is the best choice for exploring AI art.
Image Generation
288.1K
Diffusionhub
DiffusionHub is a stable Diffusion cloud platform that enables users to easily launch instances, store generation results, and create without the need for a GPU. Explore Automatic1111, Comfy, and Kohya for a seamless creative experience.
AI Model
54.1K
Stable Diffusion WebUI Forge
Stable Diffusion WebUI Forge, developed with Stable Diffusion WebUI and Gradio, aims to optimize resource management and accelerate inference. Compared to the original WebUI, Forge can boost SDXL inference speed by 30-75% at 1024px resolution, increase the maximum resolution by 2-3 times, and enlarge the maximum batch size by 4-6 times. Forge retains all the functionalities of the original WebUI while adding samplers like DDPM, DPM++, and LCM, enabling algorithms such as Free U, SVD, and Zero123. Its UNet Patcher allows developers to implement algorithms with minimal code. Forge also optimizes control network usage, achieving true zero-memory occupancy calls.
AI image generation
810.6K
Stable Cascade
Stable Cascade is a text-to-image generation model based on the Würstchen architecture. Compared to other models, it uses a smaller latent space for training and inference, resulting in significant improvements in both training and inference speed. The model can run on consumer-grade hardware, lowering the barrier to entry. Stable Cascade has shown outstanding performance in human evaluations, outperforming other models in both prompt alignment and image quality. Overall, it is an efficient, user-friendly, and powerful text-to-image AI model.
AI image generation
163.7K
Segmoe
SegMoE is a powerful framework that can dynamically combine Stable Diffusion models into expert mixtures within minutes, without requiring any training. It enables the instant creation of larger models, providing more knowledge, better adherence, and improved image quality. Inspired by mergekit's mixtral branch, SegMoE is specifically designed for Stable Diffusion models. It is easy to install and use, making it ideal for image generation and synthesis tasks.
AI image generation
108.5K
Taiyi Diffusion XL
Taiyi-Diffusion-XL is an open-source text-to-image generation model based on the Stable Diffusion framework, supporting both English and Chinese text-to-image generation. It represents a significant advancement over previous Chinese text-to-image models. The model can generate photo-realistic images based on textual descriptions, supports various image styles, and boasts high quality and diversity in generated images. It adopts an innovative training approach, extends vocabulary and position encoding to support long texts and Chinese, and is trained on large-scale bilingual datasets, ensuring its robust English and Chinese generation capabilities.
AI image generation
124.8K

Comfy Textures
Comfy Textures is a Unreal Engine plugin that integrates the editor with ComfyUI, allowing for the quick creation and adjustment of scene textures using generative diffusion models. Supports single-viewpoint and multi-viewpoint texture projection and is suitable for both perspective and orthographic cameras. It also offers texture editing and image-to-image workflows. It can seamlessly work with Unreal Engine versions 5.x and 4.x.
AI image generation
105.7K
- 1
- 2
- 3
Featured AI Tools
Chinese Picks

騰訊混元圖像 2.0
騰訊混元圖像 2.0 是騰訊最新發布的 AI 圖像生成模型,顯著提升了生成速度和畫質。通過超高壓縮倍率的編解碼器和全新擴散架構,使得圖像生成速度可達到毫秒級,避免了傳統生成的等待時間。同時,模型通過強化學習算法與人類美學知識的結合,提升了圖像的真實感和細節表現,適合設計師、創作者等專業用戶使用。
圖片生成
88.3K
English Picks

Lovart
Lovart 是一款革命性的 AI 設計代理,能夠將創意提示轉化為藝術作品,支持從故事板到品牌視覺的多種設計需求。其重要性在於打破傳統設計流程,節省時間並提升創意靈感。Lovart 當前處於測試階段,用戶可加入等候名單,隨時體驗設計的樂趣。
AI設計工具
71.2K

Fastvlm
FastVLM 是一種高效的視覺編碼模型,專為視覺語言模型設計。它通過創新的 FastViTHD 混合視覺編碼器,減少了高分辨率圖像的編碼時間和輸出的 token 數量,使得模型在速度和精度上表現出色。FastVLM 的主要定位是為開發者提供強大的視覺語言處理能力,適用於各種應用場景,尤其在需要快速響應的移動設備上表現優異。
AI模型
55.5K

Keysync
KeySync 是一個針對高分辨率視頻的無洩漏唇同步框架。它解決了傳統唇同步技術中的時間一致性問題,同時通過巧妙的遮罩策略處理表情洩漏和麵部遮擋。KeySync 的優越性體現在其在唇重建和跨同步方面的先進成果,適用於自動配音等實際應用場景。
視頻編輯
53.5K
Manus
Manus 是由 Monica.im 研發的全球首款真正自主的 AI 代理產品,能夠直接交付完整的任務成果,而不僅僅是提供建議或答案。它採用 Multiple Agent 架構,運行在獨立虛擬機中,能夠通過編寫和執行代碼、瀏覽網頁、操作應用等方式直接完成任務。Manus 在 GAIA 基準測試中取得了 SOTA 表現,展現了強大的任務執行能力。其目標是成為用戶在數字世界的‘代理人’,幫助用戶高效完成各種複雜任務。
個人助理
1.5M
Trae國內版
Trae是一款專為中文開發場景設計的AI原生IDE,將AI技術深度集成於開發環境中。它通過智能代碼補全、上下文理解等功能,顯著提升開發效率和代碼質量。Trae的出現填補了國內AI集成開發工具的空白,滿足了中文開發者對高效開發工具的需求。其定位為高端開發工具,旨在為專業開發者提供強大的技術支持,目前尚未明確公開價格,但預計會採用付費模式以匹配其高端定位。
開發與工具
143.8K
English Picks

Pika
Pika是一個視頻製作平臺,用戶可以上傳自己的創意想法,Pika會自動生成相關的視頻。主要功能有:支持多種創意想法轉視頻,視頻效果專業,操作簡單易用。平臺採用免費試用模式,定位面向創意者和視頻愛好者。
視頻生成
18.7M
Chinese Picks

Liblibai
LiblibAI是一箇中國領先的AI創作平臺,提供強大的AI創作能力,幫助創作者實現創意。平臺提供海量免費AI創作模型,用戶可以搜索使用模型進行圖像、文字、音頻等創作。平臺還支持用戶訓練自己的AI模型。平臺定位於廣大創作者用戶,致力於創造條件普惠,服務創意產業,讓每個人都享有創作的樂趣。
AI模型
8.0M