%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Liteavatar
LiteAvatarは、リアルタイムチャットシーン向けの音声駆動型リアルタイム2Dアバター生成モデルです。 高効率の音声認識と口型パラメータ予測技術と軽量な2D顔生成モデルを組み合わせることで、CPUのみのデバイスで30fpsのリアルタイム推論を実現します。主な利点としては、高効率の音声特徴抽出、軽量なモデル設計、モバイルデバイスへの高い親和性などが挙げられます。リアルタイムなインタラクションが必要な仮想アバター生成シーン、例えばオンライン会議やバーチャルライブなどに適しており、リアルタイムインタラクションと低ハードウェア要件へのニーズに基づいて開発されました。現在、オープンソースで無料で提供されており、高効率で低リソース消費のリアルタイムアバター生成ソリューションを目指しています。
チャットボット
51.1K
INFP
INFPは、二人間の会話用に設計された音声駆動型のインタラクティブなヘッド生成フレームワークです。二人間の会話のデュアルトラック音声と任意のエージェントの単一肖像画像から、リアルな表情とリズム感のあるヘッドポーズ動作を備えた、言語的、非言語的、インタラクティブなエージェントビデオを動的に合成します。このフレームワークは軽量かつ強力で、ビデオ会議などのリアルタイムコミュニケーションシーンに適しています。INFPは、Interactive(インタラクティブ)、Natural(自然)、Flash(高速)、Person-generic(汎用)を表します。
映像制作
55.2K
MEMO
MEMOは、音声駆動による動画生成のための高度なオープンウェイトモデルです。このモデルは、メモリガイド付き時間モジュールと感情認識音声モジュールにより、長期的な同一性の一貫性とモーションの滑らかさを向上させると同時に、音声内の感情を検出して表情を調整することで、同一性の一貫性があり表情豊かな動画を生成します。MEMOの主な利点には、よりリアルな動画生成、音声と唇の同期性の向上、同一性の一貫性、および表情感情の整合性があります。技術的背景情報によると、MEMOは様々な画像と音声の種類において、よりリアルな動画を生成し、既存の最先端手法を凌駕しています。
映像制作
67.9K
FLOAT
FLOATは、流マッチング生成モデルに基づくオーディオ駆動型の人物ビデオ生成手法です。生成モデリングをピクセルベースの潜在空間から学習済みモーション潜在空間に移行することで、時間的に一貫性のあるモーションデザインを実現しています。本手法は、トランスフォーマーベースのベクトル場予測器を導入し、シンプルかつ効果的なフレーム単位の条件付けメカニズムを備えています。さらに、FLOATは音声駆動型感情増強に対応しており、表現力豊かなモーションを自然に統合できます。広範な実験により、FLOATは視覚品質、モーション忠実度、効率性において、既存のオーディオ駆動型話者像手法を上回ることが示されています。
映像制作
50.8K

Echomimicv2
EchoMimicV2は、アリババグループの支付宝アントフィナンシャル?グループ端末技術部が開発した半身人物アニメーション技術です。参照画像、音声クリップ、一連のジェスチャーから高品質なアニメーションビデオを生成し、音声コンテンツと半身動作の一貫性を確保します。この技術は従来の複雑なアニメーション制作プロセスを簡素化し、Audio-Pose動的調整戦略(姿勢サンプリングと音声拡散を含む)により、半身のディテール、表情、ジェスチャー表現力を強化すると同時に、条件の冗長性を削減します。さらに、頭部部分的アテンションメカニズムを活用してアバターデータをトレーニングフレームワークにシームレスに統合し、推論プロセスでは省略可能にすることで、アニメーション制作を容易にします。EchoMimicV2は、特定段階のノイズ除去損失も設計しており、アニメーションの特定段階での動き、ディテール、低レベルの品質を導きます。この技術は、定量的および定性的評価において既存の方法を上回り、半身人物アニメーション分野におけるそのリーダーシップを示しています。
人物動作
55.8K
Joyvasa
JoyVASAは、拡散モデルに基づく音声駆動型の人物アニメーション技術です。動的な顔の表情と静的な3D顔表現を分離することで、顔の動きと頭の動きを生成します。この技術は、ビデオ品質と唇の同期精度を向上させるだけでなく、動物の顔のアニメーションにも拡張でき、多言語に対応し、訓練と推論の効率も向上しています。JoyVASAの主な利点には、より長いビデオ生成能力、キャラクターのアイデンティティに依存しないモーションシーケンスの生成、および高品質なアニメーションレンダリングが含まれます。
音声駆動
54.9K

Hallo2
Hallo2は、潜在拡散生成モデルに基づく人物画像アニメーション技術です。音声駆動により、高解像度で長時間のビデオを生成します。複数の設計改良を取り入れることで、Halloの機能を拡張し、長時間のビデオ生成、4K解像度のビデオ生成、テキストプロンプトによる表情制御の強化などを実現しました。Hallo2の主な利点としては、高解像度出力、長時間における安定性、テキストプロンプトによる制御性の向上といった点が挙げられ、多様で豊かな肖像アニメーションコンテンツの生成において顕著な優位性を持ちます。
AI画像生成
65.1K
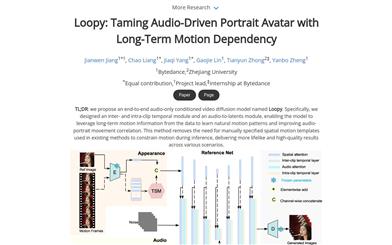
Loopyモデル
Loopyは、エンドツーエンドの音声駆動型ビデオ拡散モデルです。クロス?クリップとインクリップの時間モジュール、および音声から潜在表現へのモジュールを特別に設計することで、データ内の長期的な運動情報を利用して自然な運動パターンを学習し、音声と肖像画の動きの関連性を高めます。この手法により、既存の方法で必要とされていた空間運動テンプレートの手動指定が不要になり、様々なシーンにおいてよりリアルで高品質な結果を実現します。
AI動画生成
94.7K

Echomimic
EchoMimicは、音声と選択した顔の特徴点、またはその組み合わせによって、リアルな肖像動画を生成できる先進的な人物画像アニメーションモデルです。斬新なトレーニング戦略により、従来の方法では音声駆動時の不安定性や、顔面キーポイント駆動による不自然な結果といった問題を解決しました。EchoMimicは複数の公開データセットと独自収集データセットで包括的な比較を行い、定量的および定性的評価において優れた性能を示しています。
AI画像生成
355.8K
Aniportrait
AniPortraitは、音声と静止画の人物画像を入力として、話す、歌う動画を生成するプロジェクトです。音声と静止画の人物顔画像から、自然で口の動きが一致したリアルな顔のアニメーションを作成できます。多言語対応、顔の再描画、頭部の姿勢制御に対応しています。音声駆動のアニメーション合成、顔の再現、頭部の姿勢制御、自律型および音声駆動の動画生成、高品質なアニメーション生成、柔軟なモデルとウェイトの設定といった機能を備えています。
AI動画生成
699.4K

Vividtalk
VividTalkは、3D混合事前学習に基づく、ワンショット音声駆動のアバター生成技術です。表情豊かで自然な頭部姿勢、リップシンクを備えたリアルなラップビデオを生成できます。この技術は2段階の汎用フレームワークを採用し、上記すべての特性を備えた高画質のラップビデオの生成をサポートしています。具体的には、第1段階では、2種類の動き(非剛体的な表情運動と剛体的な頭部運動)を学習することで、音声をメッシュにマッピングします。表情運動については、混合形状と頂点を中間表現として採用し、モデルの表現能力を最大化します。自然な頭部運動については、新規の学習可能な頭部姿勢コードブックを提案し、2段階の訓練メカニズムを採用しています。第2段階では、双方向運動VAEとジェネレーターを提案し、メッシュを密集した動きに変換し、フレームごとに高画質ビデオを合成します。広範な実験により、VividTalkはリップシンクとリアルなエンハンスメントを備えた高画質のラップビデオを生成でき、客観的および主観的な比較において、従来最先端の作品を上回ることが実証されました。この技術のコードは、発表後に公開されます。
AI顔画像生成
137.2K
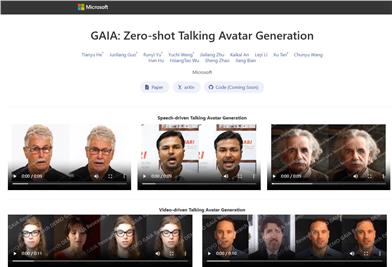
GAIA
GAIAは、音声と単一の肖像画像から自然な会話動画を合成することを目的としています。本研究では、会話アバター生成におけるドメイン固有の事前知識を排除するGAIA(Avatarの生成AI)を導入しました。GAIAは、1)各フレームをモーション表現と外観表現に分解する、2)音声と参照肖像画像を条件としてモーションシーケンスを生成する、という二段階のプロセスで構成されます。大規模で高品質な会話アバターデータセットを収集し、様々な規模でモデルを訓練しました。実験結果は、GAIAの優れた性能、拡張性、柔軟性を裏付けています。本手法には、変分オートエンコーダ(VAE)と拡散モデルが用いられており、拡散モデルは音声シーケンスとビデオクリップ内のランダムなフレームを条件としてモーションシーケンスを生成するように最適化されています。GAIAは、制御可能な会話アバター生成やテキストガイドによるアバター生成など、様々な用途に適用可能です。
AI動画生成
66.8K
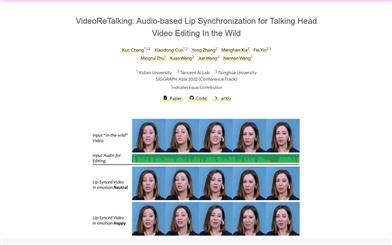
Videoretalking
VideoReTalkingは、入力された音声に合わせて実写の会話シーンの顔の表情を編集し、感情が異なっていても高品質な唇の同期を実現する新しいシステムです。このシステムは、この目標を以下の3つの連続したタスクに分解します。(1)表情編集ネットワークを用いて、標準的な表情の顔のビデオを生成する;(2)音声駆動による唇の同期;(3)写真のような写実性を高めるための顔の強化。会話シーンのビデオが与えられると、まず表情編集ネットワークを使用して各フレームの表情を同じ表情テンプレートで修正し、標準的な表情のビデオを得ます。次に、このビデオと与えられた音声を唇の同期ネットワークに入力して、唇の同期ビデオを生成します。最後に、識別情報に基づいた顔の強化ネットワークと後処理によって、合成された顔の写真のような写実性を高めます。3つのステップ全てで学習に基づいた手法を用いており、全てのモジュールは順番にパイプライン処理され、ユーザーによる介入は一切必要ありません。
AI動画編集
318.2K

イミテーター
イミテーターは、斬新なパーソナライズされた音声駆動型3D顔アニメーション手法です。音声シーケンスとパーソナライズされたスタイル埋め込みを入力として与えることで、唇の閉鎖が正確な個人固有のモーションシーケンスを生成します(唇を閉じる双唇音「m」、「b」、「p」に対応)。短い参照動画(例:5秒)から、対象のスタイル埋め込みを計算できます。
AI動画編集
59.9K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
39.7K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
39.2K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
38.1K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
38.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
39.5K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
38.4K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M