%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
RF DETR
RF-DETRは、エッジデバイスに高精度とリアルタイム性能を提供することを目的とした、Transformerベースのリアルタイム物体検出モデルです。Microsoft COCOベンチマークで60 APを超える競争力のある性能と高速な推論速度を備え、様々な実用的なアプリケーションシナリオに適しています。RF-DETRは、現実世界の物体検出問題を解決することを目的としており、防犯、自動運転、スマート監視など、高効率かつ正確な検出が必要な業界に適しています。
["ラクシー パチャーン],["AI モデル]
51.6K
エイジェンティック物体検出
エイジェンティック物体検出は、テキストプロンプトによって画像内の対象物を正確に識別できる、高度な推論駆動型物体検出技術です。大量のカスタムトレーニングデータが不要で、人間並みの精度を実現します。本技術は、デザインパターンを用いて対象物の固有属性(色、形状、テクスチャなど)を深く推論することで、様々なシーンにおいてよりスマートで正確な識別を実現します。主な利点として、高精度、大量のトレーニングデータが不要、複雑なシーンにも対応可能といった点が挙げられます。製造業、農業、医療など、高精度な画像認識が求められる業界に適しており、企業の生産性向上と品質管理レベルの向上に貢献します。現在、製品は試用段階であり、ユーザーは無料で機能を試用できます。
AIモデル
53.3K
中国語精選
DINO X
DINO-Xは物体認識を中核とした大規模ビジョンモデルであり、オープンセット検出、インテリジェントな質問応答、人体姿勢推定、物体カウント、衣服の色変更といったコア機能を備えています。既知の物体だけでなく、未知のカテゴリにも柔軟に対応し、高度なアルゴリズムにより優れた適応性と堅牢性を誇ります。予測不可能な様々な課題にも正確に対応し、複雑なビジュアルデータに対する包括的なソリューションを提供します。DINO-Xは、ロボット工学、農業、小売業、セキュリティ監視、交通管理、製造業、スマートホーム、物流?倉庫、エンターテインメントメディアなど、幅広い用途に適用可能であり、DeepDataSpace社がコンピュータビジョン技術分野で開発した主力製品です。
物体検出
64.0K
Claude Vision物体検出
Claude Vision物体検出は、Pythonベースのツールで、Claude 3.5 Sonnet Vision APIを使用して画像内の物体を検出し、視覚化します。このツールは、検出された物体の周囲に自動的に境界ボックスを描画し、ラベル付けを行い、信頼度スコアを表示します。単一の画像またはディレクトリ全体の画像を処理でき、高精度の信頼度スコアと、検出された各物体に対する鮮やかで異なる色を使用します。さらに、検出結果付きの注釈付き画像を保存することもできます。
画像編集
48.3K
D FINE
D-FINEは、DETRにおける境界ボックス回帰タスクを細粒度分布細化(FDR)として再定義し、グローバル最適位置自己蒸留(GO-LSD)を導入することで、追加の推論やトレーニングコストなしに優れた性能を実現する、強力なリアルタイム物体検出モデルです。中国科学院の研究者によって開発され、物体検出の精度と効率の向上を目指しています。
モデルトレーニングとデプロイ
45.8K

YOLO11
Ultralytics YOLO11は、以前のYOLOシリーズモデルをさらに発展させたもので、性能と柔軟性を向上させるための新機能と改良が導入されています。YOLO11は高速、高精度、使いやすさを目指しており、幅広い物体検出、追跡、インスタンスセグメンテーション、画像分類、姿勢推定タスクに最適です。
AI画像検出識別
67.9K

Bonding W Geimini
bonding_w_geiminiは、Streamlitフレームワークを基盤とした画像処理アプリケーションです。ユーザーは画像をアップロードし、Gemini APIを通じて物体検出を行い、検出された物体の境界ボックスを画像上に直接描画できます。このアプリケーションは機械学習モデルを利用して画像内の物体を認識?特定し、画像分析、データアノテーション、自動画像処理などの分野で重要な役割を果たします。
AI画像検出識別
50.2K
Florence 2 Large
Florence-2-largeは、マイクロソフトが開発した高度なビジョン基礎モデルです。プロンプトベースのアプローチを採用し、幅広いビジョンおよびビジョン?言語タスクに対応します。このモデルは、シンプルなテキストプロンプトを解釈して、画像キャプション生成、物体検出、セグメンテーションなどのタスクを実行できます。5億4千万枚の画像に54億個の注釈が付いたFLD-5Bデータセットを活用し、マルチタスク学習に長けています。シーケンスツーシーケンスアーキテクチャにより、ゼロショットおよびファインチューニング設定の両方で優れたパフォーマンスを発揮し、競争力のあるビジョン基礎モデルであることが証明されています。
AI画像生成
61.3K
Yolov10:
YOLOv10は、リアルタイム性能を維持しながら高精度な物体検出を実現する、次世代の物体検出モデルです。後処理とモデルアーキテクチャの最適化により、計算冗長性を削減し、効率と性能を向上させています。YOLOv10は、YOLOv10-Sなど、様々なモデル規模において最先端の性能と効率を達成しています。例えば、YOLOv10-Sは、同等のAPにおいてRT-DETR-R18よりも1.8倍高速でありながら、パラメータ数とFLOPsは2.8倍削減されています。
AIモデル
77.0K
Grounding DINO 1.5 API
Grounding DINO 1.5は、IDEA Researchによって開発された、オープンワールド物体検出技術の限界を押し上げることを目指した高度なモデルシリーズです。このシリーズには、Grounding DINO 1.5 ProとGrounding DINO 1.5 Edgeの2つのモデルが含まれており、それぞれ広範なアプリケーションシナリオとエッジコンピューティングシナリオ向けに最適化されています。
AI画像検出識別
72.3K
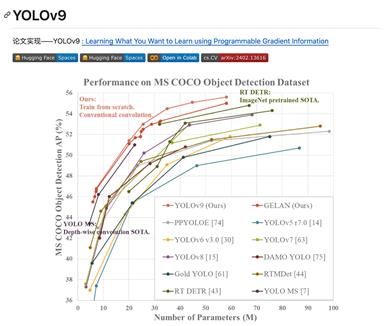
Yolov9
yolov9はYOLOv9論文に基づいた実装であり、プログラマブルな勾配情報を使用して、ユーザーが学習させたい内容を学習します。このプロジェクトはオープンソースの深層学習モデルであり、主に物体検出タスクに使用され、高効率と高精度を特徴としています。
AI画像検出識別
158.4K

Yolov8
YOLOv8は、YOLOシリーズ物体検出モデルの最新版であり、画像や動画内における複数の物体の正確かつ迅速な識別と位置特定、そしてそれらの移動のリアルタイム追跡が可能です。以前のバージョンと比較して、YOLOv8は検出速度と精度が大幅に向上しており、インスタンスセグメンテーションや姿勢推定など、様々な追加のコンピュータビジョンタスクにも対応しています。YOLOv8は様々なフォーマットで異なるハードウェアプラットフォームに展開でき、エンドツーエンドの物体検出ソリューションを提供します。
AI画像検出識別
230.5K
YOLO World
YOLO-Worldは、You Only Look Once (YOLO)シリーズの検出器をベースに、視覚言語モデルと大規模データセットによる事前学習によって、オープンボキャブラリー検出能力を強化した、高度なリアルタイムオープンボキャブラリー物体検出器です。再パラメータ化可能な視覚言語パスアグリゲーションネットワーク(RepVL-PAN)と領域テキストコントラスト損失を採用することで、視覚情報と言語情報の相互作用を促進しています。YOLO-Worldは、ゼロショット方式で様々な物体を効率的に検出し、高い効率性を備えています。チャレンジングなLVISデータセットにおいて、YOLO-WorldはV100上で35.4 APと52.0 FPSを実現し、精度と速度の両面で多くの最先端手法を凌駕しています。さらに、ファインチューニングされたYOLO-Worldは、物体検出やオープンボキャブラリーインスタンスセグメンテーションを含む、多くの下流タスクで優れた性能を発揮します。
AI画像検出識別
115.4K

Actanywhere
ActAnywhereは、前景の主体動作や外観と一致するビデオ背景を自動生成するモデルです。このタスクは、前景の主体動作や外観と一致するだけでなく、アーティストの意図にも沿った背景を合成することを含みます。ActAnywhereは大規模ビデオ拡散モデルを活用し、このタスク向けに特化して開発されました。ActAnywhereは、前景の主体セグメンテーションのシーケンスを入力として、必要なシーンを記述する画像を条件として、条件フレームと整合性のある連続ビデオを生成し、現実的な前景と背景の相互作用を実現します。このモデルは大規模な人とコンピューターのインタラクションビデオデータセットでトレーニングされています。多くの評価により、このモデルは基準モデルよりも明らかに優れた性能を示し、人間以外の主体を含む様々な分布サンプルに対して汎化できることが示されています。
AI動画生成
166.7K
Idict
idictは、137種類の言語に対応したリアルタイム翻訳、物体検出、写真翻訳、テキスト翻訳を提供するアプリです。言語の壁を取り払い、いつでもどこでも円滑なコミュニケーションを支援します。
翻訳
52.4K
Tweetme
クラウド認識は、高度な深層学習アルゴリズムを用いたインテリジェントな画像認識サービスを提供する製品です。リアルタイムで正確に画像内の物体、シーン、テキストを認識?分類します。高精度、高速レスポンス、様々な画像フォーマットのサポート、マルチプラットフォーム統合といった利点を備えています。価格は利用量と機能に応じてカスタマイズ可能です。主な機能には、画像分類、物体検出、シーン認識、テキスト認識などがあります。画像検索、コンテンツフィルタリング、自動運転、防犯監視など、様々な画像処理シーンに適用可能です。
画像編集
57.4K
PIXTA AI AI/MLトレーニングデータサービス
Pixta AIは、大規模データアノテーションとデータ収集ソリューションを提供する企業です。1000名以上の経験豊富なアノテーターと、9000万枚以上の画像、1000万本以上の動画を保有しています。当社のサービスを利用することで、AI開発を加速させることができます。提供するアノテーションとデータ収集サービスは、あらゆるニーズに対応しており、お客様のプロジェクトに合わせてカスタマイズすることも可能です。
データ分析
46.4K

Lobe
Lobeは、カスタム機械学習モデルをトレーニングしてアプリケーションで使用するための、無料で使いやすいツールです。Lobeには、機械学習のアイデアを実現するために必要なものがすべて揃っています。学習させたいサンプルを見せるだけで、アプリケーションで使用できるカスタム機械学習モデルを自動的にトレーニングします。
モデルトレーニングとデプロイ
51.1K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
40.8K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
40.3K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
39.7K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
39.5K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
40.3K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
39.2K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M