%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
中国語精選

GO 1
智元汎用具象基盤大規模モデルGO-1は、智元が発表した革新的な人工知能モデルです。このモデルは、革新的なVision-Language-Latent-Action(ViLLA)アーキテクチャに基づいており、マルチモーダル大規模モデル(VLM)と混合専門家(MoE)システムを通じて、視覚と言語入力からロボット動作の実行までの効率的な変換を実現しています。GO-1は、人間のビデオと実際のロボットデータを使用して学習することができ、強力な汎化能力を備えており、非常に少ないデータ、あるいはゼロショットでも新しいタスクや環境に迅速に適応できます。主な利点としては、効率的な学習能力、強力な汎化性能、そして様々なロボット本体への適合性があります。このモデルの発表は、具象知能が汎用化、オープン化、知能化の方向へ大きく前進したことを示しており、商業、産業、家庭など多くの分野で重要な役割を果たすことが期待されます。
AIモデル
45.8K
R1 V
R1-Vは、視覚言語モデル(VLM)の汎化能力に特化したプロジェクトです。検証可能な報酬による強化学習(RLVR)技術を用いることで、特に分布外(OOD)テストにおいて、VLMの視覚カウントタスクにおける汎化能力を大幅に向上させました。この技術の重要性は、わずか2.62ドルのトレーニングコストで、大規模モデルを効率的に最適化できる点にあり、視覚言語モデルの実用化に新たな道を切り開きます。プロジェクトの背景は、既存のVLMトレーニング方法の改善に基づいており、革新的なトレーニング戦略を通じて、複雑な視覚タスクにおけるモデルのパフォーマンス向上を目指しています。R1-Vのオープンソース性も、研究者や開発者が高度なVLM技術を探求し、応用するための重要なリソースとなっています。
AIモデル
56.3K
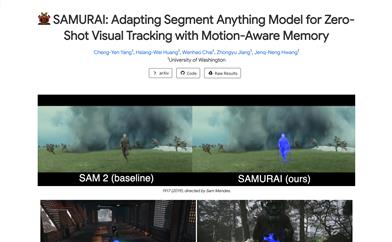
SAMURAI
SAMURAIは、Segment Anything Model 2 (SAM 2)をベースとしたビジュアルオブジェクトトラッキングモデルです。高速移動する物体や自己遮蔽する物体のビジュアルトラッキングタスクに特化して設計されています。時間的運動手がかりと運動知覚メモリ選択メカニズムを導入することで、物体の運動を効果的に予測し、マスク選択を最適化します。再トレーニングや微調整なしで、堅牢かつ正確なトラッキングを実現します。SAMURAIはリアルタイム環境で動作し、複数のベンチマークデータセットで強力なゼロショット性能を示しており、微調整なしで汎化できる能力を実証しています。評価において、SAMURAIは成功率と精度において既存のトラッカーと比較して大幅な向上を示しました。例えば、LaSOT-extではAUCが7.1%向上し、GOT-10kではAOが3.5%向上しました。さらに、LaSOTにおける教師あり学習手法と比較しても競争力を示しており、複雑なトラッキングシーンにおける堅牢性と動的環境における潜在的な実用性を強調しています。
ゼロショット学習
53.0K

Maniwav
ManiWAVは、野外の音声と映像データを用いてロボット操作スキルを学習することを目的とした研究プロジェクトです。人間の操作デモンストレーションから同期した音声と映像のフィードバックを収集し、対応する戦略インターフェースを通じて、デモンストレーションから直接ロボット操作戦略を学習します。本モデルは、ロボットが接触事象やパターンをパッシブに感知したり、物体表面の材質や状態をアクティブに感知する必要がある、接触が豊富な4つの操作タスクを通じて、システムの能力を実証しています。さらに、多様な野外の人のデモンストレーションを学習することで、未経験の野外環境にも一般化することができます。
AI機械人
47.2K

マルチモーダル大規模言語モデル
本ツールは、最新の独自開発およびオープンソースのMLLMを定性的研究することにより、テキスト、コード、画像、動画の4つのモダリティから、その汎化能力、信頼性、因果推論能力を評価し、MLLMの透明性を高めることを目的としています。これらの属性は、様々な下流アプリケーションを支えるMLLMの信頼性を定義する上で重要な要素であると考えています。具体的には、クローズドソースのGPT-4とGemini、ならびに6つのオープンソースLLMおよびMLLMを評価しました。全体として、230個の手動設計された事例を評価し、定性的な結果は12個のスコア(モダリティ4つ×属性3つ)に要約されています。合計で14の経験的知見を明らかにし、独自開発とオープンソースのMLLMの能力と限界を理解し、より信頼性の高い多様なモダリティの下流アプリケーションをサポートすることに役立てます。
AIモデル評価
48.3K
中国語精選

Instructvideo
InstructVideoは、人間からのフィードバックによる報酬強化学習を用いて、テキストからビデオへの拡散モデルを指導する手法です。編集方式による報酬強化学習を採用することで、微調整コストの削減と効率の向上を実現しています。確立された画像報酬モデルを用い、セグメント化された疎なサンプリングと時間減衰報酬によって報酬信号を提供することで、生成ビデオの画質を大幅に向上させています。InstructVideoは、生成ビデオの画質向上だけでなく、高い汎化能力も維持します。詳細については、公式ウェブサイトをご覧ください。
AI動画生成
131.7K

GLEE
GLEEは、画像と動画に対する汎用オブジェクト基礎モデルです。統一されたフレームワークを通じて、画像と動画内のオブジェクトの定位と識別を実現し、様々なオブジェクト認識タスクに適用できます。GLEEは、異なる監督レベルの様々なデータソースを統合して学習することで、汎用的なオブジェクト表現を形成し、最先端の性能を維持しつつ、ゼロショット転移と汎化を効果的に行うことができます。また、優れた拡張性と堅牢性を備えています。
AI画像検出識別
73.1K
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
43.1K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
42.0K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.8K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
41.1K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
42.0K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
40.3K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M