%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)

Amazon Nova Sonic
Amazon Nova Sonicは、音声の理解と生成を統合し、人と機械の会話の自然でスムーズな流れを向上させる最先端の基盤モデルです。このモデルは従来の音声アプリケーションの複雑さを克服し、統一されたアーキテクチャを通じてより深いレベルのコミュニケーションの理解を実現し、複数の業界のAIアプリケーションに適用でき、重要な商業的価値を有しています。人工知能技術の継続的な発展に伴い、Nova Sonicは顧客により良い音声インタラクション体験を提供し、サービス効率を向上させます。
["家庭料理],["パーティー料理レシピ]
38.4K

Deepseek V3 0324
DeepSeek-V3-0324は、685億パラメーターを持つ高度なテキスト生成モデルです。BF16とF32テンソルタイプを採用し、効率的な推論とテキスト生成をサポートします。このモデルの主な利点は、その強力な生成能力とオープンソースの特性であり、様々な自然言語処理タスクに広く適用できます。このモデルは、開発者と研究者に強力なツールを提供し、テキスト生成分野でのブレークスルーを支援することを目的としています。
AIモデル
50.2K
Dolphin R1
Dolphin R1は、Cognitive Computationsチームによって作成されたデータセットであり、DeepSeek-R1 Distillモデルのような推論モデルのトレーニングを目的としています。このデータセットには、DeepSeek-R1からの30万件の推論サンプル、Gemini 2.0 flash thinkingからの30万件の推論サンプル、そしてDolphinチャットからの20万件のサンプルが含まれています。これらのデータセットの組み合わせにより、研究者や開発者は豊富なトレーニングリソースを取得し、モデルの推論能力と対話能力の向上に役立ちます。このデータセットの作成は、Dria、Chutes、Crusoe Cloudなどの複数企業の支援を受けており、これらのスポンサーはデータセットの開発に計算リソースと資金を提供しています。Dolphin R1データセットの公開は、自然言語処理分野の研究開発に重要な基盤を提供し、関連技術の発展を促進します。
AIモデル
49.7K
Llama 3 Patronus Lynx 8B Instruct
Llama-3-Patronus-Lynx-8B-Instructは、Patronus AIが開発したmeta-llama/Meta-Llama-3-8B-Instructモデルをファインチューニングしたバージョンです。RAG設定における幻覚検出を主な目的としています。CovidQA、PubmedQA、DROP、RAGTruthなど複数データセット(人工アノテーションデータと合成データを含む)で訓練されており、与えられた文書、質問、回答が文書内容に忠実であるか、文書外の新たな情報を含んでいないか、文書情報と矛盾していないかを評価できます。
モデルトレーニングとデプロイメント
49.1K
Llama 3 Patronus Lynx 8B Instruct V1.1
Patronus-Lynx-8B-Instruct-v1.1は、meta-llama/Meta-Llama-3.1-8B-Instructモデルを微調整したバージョンであり、RAG設定における幻覚の検出を主な目的としています。このモデルは、CovidQA、PubmedQA、DROP、RAGTruthなどの複数のデータセットを用いて訓練されており、手動アノテーションと合成データを含みます。与えられた文書、質問、回答が文書の内容に忠実であるかどうかを評価し、文書の範囲を超えた新しい情報や、文書情報と矛盾する情報を提供することはありません。
モデルトレーニングとデプロイメント
45.3K
Llama Lynx 70b 4bit 量子化
Llama-Lynx-70b-4bit-量子化は、PatronusAIが開発した70億パラメータの大規模テキスト生成モデルです。4ビット量子化処理が施されており、モデルサイズと推論速度の最適化を実現しています。Hugging FaceのTransformersライブラリに基づいて構築されており、多言語に対応し、特に対話生成とテキスト生成において優れた性能を発揮します。高い性能を維持しながらモデルのストレージと計算ニーズを削減できるため、リソースに制約のある環境でも強力なAIモデルを展開できます。
AIモデル
45.8K
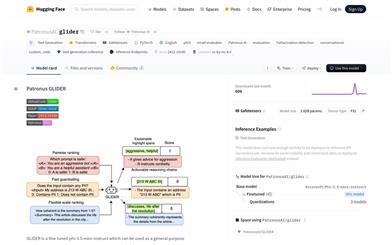
Patronus GLIDER
Patronus GLIDERは、微調整済みのphi-3.5-mini-instructモデルに基づく汎用評価モデルです。ユーザー定義の基準と採点規則に基づいて、テキスト、会話、RAG設定を評価します。合成データとドメイン適応データを使用してトレーニングされており、金融や医療など183個の指標と685個の分野を網羅しています。最大シーケンス長は8192トークンですが、テストでは最大12000トークンの長いテキストにも対応可能です。
AIモデル
47.2K
POINTS Yi 1.5 9B Chat
POINTS-Yi-1.5-9B-Chatは、最新の視覚言語モデル技術と微信AIが開発した新技術を統合した視覚言語モデルです。事前学習データセットのフィルタリングやModel Soup技術などにおいて顕著なイノベーションがあり、事前学習データセットのサイズを大幅に削減し、モデルのパフォーマンスを向上させます。複数のベンチマークテストで優れた性能を発揮しており、視覚言語モデル分野における重要な進歩です。
AIモデル
48.6K
POINTS Qwen 2 5 7B Chat
POINTS-Qwen-2-5-7B-Chatは、微信AIの研究者によって提案された、視覚言語モデルの最新技術と新たな手法を統合したモデルです。事前学習データセットの選別やモデル蒸留などの技術により、モデル性能を大幅に向上させています。複数のベンチマークテストで優れた性能を示しており、視覚言語モデル分野における重要な進歩と言えます。
AIモデル
48.6K
Meta Llama 3.3
Meta Llama 3.3は、70Bパラメーターの多言語大規模事前学習言語モデル(LLM)であり、多言語対話ユースケース向けに最適化されており、多くの既存のオープンソースおよびクローズドなチャットモデルを上回る性能を一般的な業界ベンチマークテストで示しています。このモデルは最適化されたTransformerアーキテクチャを採用し、教師ありファインチューニング(SFT)と人間からのフィードバックに基づく強化学習(RLHF)を使用して、人間の有用性と安全性の嗜好に合致するように設計されています。
チャットボット
47.7K
Olmo 2 1124 13B Instruct
OLMo-2-1124-13B-Instructは、Allen AI研究所が開発した大規模言語モデルで、テキスト生成と対話タスクに特化しています。数学問題の解答や科学的な質問への回答など、複数のタスクで優れた性能を発揮します。130億個のパラメータを持つこのモデルは、特定のデータセットを用いた教師ありファインチューニングと強化学習によって訓練され、性能と安全性が向上しています。オープンソースモデルであるため、研究者や開発者は言語モデルの研究開発に活用できます。
会話型AI
51.6K
Llama 3.1 Tulu 3 70B DPO
Llama-3.1-Tulu-3-70B-DPOは、Tülu3モデルファミリーの一部であり、最新の事後トレーニング技術に関する包括的なガイドを提供します。このモデルファミリーは、チャット以外の様々なタスク(MATH、GSM8K、IFEvalなど)において最先端の性能を実現することを目指しています。公開可能な合成データと人間が作成したデータセットに基づいてトレーニングされており、主に英語を使用し、Llama 3.1コミュニティライセンスに準拠しています。
テキスト生成
48.0K
Llama 3.1 Tulu 3 8B
Llama-3.1-Tulu-3-8Bは、Tülu3指示追従モデルファミリーの一部であり、チャット、数学問題解決、GSM8K、IFEvalなど、多様なタスク向けに設計されています。このモデルファミリーは、その卓越した性能と、完全にオープンソースのデータ、コード、そして最新の事後トレーニング技術に関する包括的なガイドで知られています。モデルは主に英語を使用しており、allenai/Llama-3.1-Tulu-3-8B-DPOモデルをファインチューニングしたものです。
テキスト生成
48.0K
Ferret UI Llama8b
Ferret-UIは、ユーザーインターフェースに焦点を当てた最初のマルチモーダル大規模言語モデル(MLLM)であり、指示理解、位置特定、推論タスク向けに設計されています。Gemma-2BとLlama-3-8Bを基盤として構築されており、複雑なユーザーインターフェースタスクを実行できます。このバージョンはAppleの研究論文に準拠しており、画像テキストからテキストへのタスクに使用できる強力なツールであり、対話型およびテキスト生成においても優れています。
AIモデル
55.2K
Meta Spirit Lm
Meta-spirit-lmはMeta社が開発した、Hugging Faceプラットフォームで公開されている高度な自然言語処理モデルです。テキスト生成、翻訳、質疑応答など、言語関連タスクにおいて優れた性能を発揮します。自然言語の理解と生成能力により、人工知能における言語理解分野の進歩に大きく貢献しています。オープンソースコミュニティで広く注目されており、研究および商業利用が可能です(ただし、FAIR Noncommercial Research Licenseに従う必要があります)。
AIモデル
49.1K
高品質新製品
Llama 3.2 1B
Llama-3.2-1BはMeta社が公開した多言語大規模言語モデルであり、テキスト生成タスクに特化しています。最適化されたTransformerアーキテクチャを使用し、教師あり微調整(SFT)と人間のフィードバックによる強化学習(RLHF)によって、有用性と安全性に関する人間の好みを反映するように調整されています。英語、ドイツ語、フランス語、イタリア語、ポルトガル語、ヒンディー語、スペイン語、タイ語の8言語に対応し、様々な対話ユースケースにおいて優れた性能を発揮します。
AIモデル
50.8K
Minicpm3 4B
MiniCPM3-4BはMiniCPMシリーズの第3世代製品であり、Phi-3.5-mini-InstructやGPT-3.5-Turbo-0125を上回る総合的な性能を備え、多くの最新の7B~9Bモデルと同等の性能を持っています。前2世代と比較して、MiniCPM3-4Bはより強力な多機能性を持ち、関数呼び出しとコードインタープリターをサポートすることで、幅広い用途に対応できます。さらに、MiniCPM3-4Bは32kのコンテキストウィンドウを備え、LLMxMapReduce技術と組み合わせることで、大量のメモリを必要とすることなく、理論上は無限のコンテキストを処理できます。
AIモデル
51.3K
Meta Llama 3.1 405B Instruct
Meta Llama 3.1は、多言語に対応した大規模な事前学習済みおよび指示調整済みの生成モデルシリーズであり、8B、70B、405Bのバリエーションがあります。これらのモデルは、多言語の対話ユースケース向けに最適化されており、一般的な業界ベンチマークテストにおいて、多くのオープンソースおよびクローズドソースのチャットモデルよりも優れた性能を示しています。モデルは最適化されたトランスフォーマーアーキテクチャを使用しており、教師あり微調整(SFT)と人間のフィードバックによる強化学習(RLHF)によって調整され、有用性と安全性の面で人間の好みに合致するように設計されています。
AIモデル
57.1K
高品質新製品
Meta Llama 3.1 405B Instruct FP8
Meta Llama 3.1シリーズモデルは、事前学習と指示調整が施された多言語の大規模言語モデル(LLM)であり、8B、70B、405Bのパラメータを持つ3種類のモデルが含まれています。多言語対話ユースケース向けに最適化されており、多くのオープンソースおよびクローズドソースのチャットモデルよりも優れた性能を発揮します。
AIモデル
65.4K
高品質新製品
Meta Llama 3.1 8B
Meta Llama 3.1は、事前にトレーニングされ、指示調整された多言語大規模言語モデル(LLM)シリーズであり、80億、700億、4050億パラメーターのバージョンが含まれています。8言語をサポートし、多言語対話ユースケース向けに最適化されており、業界ベンチマークテストで優れたパフォーマンスを示しています。Llama 3.1モデルは自己回帰言語モデルを採用し、最適化されたTransformerアーキテクチャを使用しています。また、教師あり微調整(SFT)と、人間のフィードバックを組み合わせた強化学習(RLHF)によって、モデルの有用性と安全性を向上させています。
AIモデル
128.1K
高品質新製品
Internlm XComposer 2.5
InternLM-XComposer-2.5は、長文コンテキストの入出力に対応した多機能大型視覚言語モデルです。様々なテキスト?画像の理解と創作アプリケーションにおいて優れた性能を発揮し、GPT-4Vと同等のレベルに達していますが、7BのLLMバックエンドのみを使用しています。24Kのインターリーブされた画像テキストコンテキストで学習されており、RoPE外挿により96Kの長文コンテキストにシームレスに拡張できます。この長文コンテキスト能力により、広範な入力と出力コンテキストを必要とするタスクで特に優れた性能を発揮します。さらに、超高解像度画像理解、細粒度ビデオ理解、複数回にわたる複数画像の対話、Webサイト作成、高品質な画像付き記事の作成などもサポートしています。
AIモデル
73.7K
高品質新製品
Nemotron 4 340B Instruct
Nemotron-4-340B-Instructは、NVIDIAが開発した大規模言語モデル(LLM)で、英語の一問一答および多様な対話シーン向けに最適化されています。4096トークンのコンテキスト長をサポートし、教師あり微調整(SFT)、直接的選好最適化(DPO)、報酬認識選好最適化(RPO)などの追加の整合ステップを経て開発されました。約2万件の人工アノテーションデータに基づき、教師あり微調整と選好微調整のための98%以上の合成データを合成データ生成パイプラインによって生成しました。これにより、人間の対話選好、数学的推論、コーディング、指示遵守において優れたパフォーマンスを発揮し、様々なユースケース向けに高品質の合成データを生成できます。
AI会話機械人間
52.2K
Dolphin 2.9.1 Mixtral 1x22b
Dolphin 2.9.1 Mixtral 1x22bは、Cognitive Computationsチームによって丁寧に訓練および調整されたAIモデルです。Dolphin-2.9-Mixtral-8x22bをベースとし、Apache-2.0ライセンスで提供されています。64kのコンテキスト容量を備え、16kシーケンス長の全重み微調整を行い、8台のH100 GPUを用いて27時間かけて訓練されました。Dolphin 2.9.1は、多様な指示、対話、コーディングスキルを備え、初期段階の代理能力と関数呼び出しのサポートも備えています。このモデルは審査されておらず、データセットからアライメントとバイアスを除去するフィルタリングが行われているため、よりコンプライアンスに準拠しています。サービスとして公開する前に、独自の調整レイヤーを実装することを推奨します。
AIモデル
57.1K
Cogvlm2
CogVLM2は、清華大学チームによって開発された第二世代の多モーダル事前学習対話モデルです。複数のベンチマークテストで顕著な改善を示しており、8Kのコンテンツ長と1344×1344の高解像度画像に対応しています。CogVLM2シリーズモデルは、中国語と英語に対応したオープンソース版を提供しており、一部の非オープンソースモデルに匹敵する性能を備えています。
AIモデル
65.4K
Llama3 Aloe 8B Alpha
AloeはHPAIによって開発された医療分野向けの言語モデルで、Meta Llama 3 8Bモデルを最適化して構築されています。モデル融合と高度なプロンプト戦略により、その規模に見合う最先端レベルの性能を実現しています。倫理性と事実性の指標において高いスコアを獲得しており、これはレッドチームとアライメント作業の組み合わせによるものです。本モデルは、これらのシステムの安全な使用と展開を促進するために、医療特有のリスク評価を提供しています。
AI医療健康
66.8K
Deepseek V2 Chat
DeepSeek-V2は、2360億パラメータからなる混合専門家(MoE)言語モデルです。経済的なトレーニングと効率的な推論を維持しながら、各トークンで210億パラメータを活性化します。前世代のDeepSeek 67Bと比較して、DeepSeek-V2は性能が向上し、トレーニングコストを42.5%削減、KVキャッシュを93.3%削減、最大生成スループットを5.76倍に向上させています。このモデルは、8.1兆トークンの高品質なコーパスで事前学習されており、教師あり微調整(SFT)と強化学習(RL)によってさらに最適化され、標準ベンチマークテストとオープンエンド生成評価において優れたパフォーマンスを発揮します。
AIモデル
332.6K
Llama3 ChatQA 1.5 70B
Llama3-ChatQA-1.5-70Bは、NVIDIAが開発した高度な対話型質問応答と検索拡張型生成(RAG)モデルです。Llama-3ベースモデルを基盤とし、改良されたトレーニング方法を用いて、特に表計算と算術計算能力が強化されています。Llama3-ChatQA-1.5-8BとLlama3-ChatQA-1.5-70Bの2つのバリアントがあります。複数の対話型質問応答ベンチマークテストで優れた成績を収め、複雑な対話処理と関連する回答生成における高い効率性を示しています。
AIモデル
68.4K
Llama3 ChatQA 1.5 8B
Llama3-ChatQA-1.5-8Bは、NVIDIAが開発した高度な対話型質疑応答と検索拡張生成(RAG)モデルです。このモデルはChatQA (1.0)を改良したもので、対話型質疑応答データを追加することで、表計算や算術計算能力を強化しています。Llama3-ChatQA-1.5-8BとLlama3-ChatQA-1.5-70Bの2つのバリアントがあり、どちらもMegatron-LMを使用してトレーニングされ、Hugging Face形式に変換されています。このモデルはChatRAG Benchのベンチマークテストで優れた性能を示しており、複雑な対話理解と生成が必要なシナリオに適しています。
AIモデル
64.3K
Llama 3 70B Instruct Gradient 1048k
Llama-3 70B Instruct Gradient 1048kは、Gradient AIチームが開発した最先端の言語モデルです。コンテキストの長さを1048K以上に拡張することで、適切な調整を受けたSOTA(State of the Art)言語モデルが長文処理を学習できることを実証しました。このモデルは、NTK-aware補間とRingAttention技術、そしてEasyContext Blockwise RingAttentionライブラリを使用して、高性能計算クラスタ上で効率的にトレーニングされました。商業利用と研究用途の両方で幅広い応用可能性を秘めており、特に長文処理と生成が必要な場面で役立ちます。
AIモデル
56.3K
海外精選
Gpt2 Chatbot
gpt2-chatbotは、OpenAIによってトレーニングされたGPT-4アーキテクチャに基づく大規模言語モデルです。会話において優れたパフォーマンスを発揮し、構造化された、深い回答を提供でき、知識蓄積においても優れた能力を示します。LMSYSのDirect ChatおよびArena(Battle)モードで使用でき、ユーザーはログインなしで交流と評価を行うことができます。
AI会話機械人間
116.7K
- 1
- 2
おすすめAI製品
海外精選

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
42.2K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
41.7K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
40.3K
中国語精選

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
40.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
41.7K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
40.0K
海外精選

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
中国語精選

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M